
ML Case-study Interview Question: Building an LLM-Powered AI Assistant for E-commerce Sales Agent Support


Browse all the ML Case-Studies here.
Case-Study question
A major e-commerce retailer is developing an advanced AI assistant to help human sales agents handle live customer chats. The system provides real-time suggestions for agent responses based on company policies, product information, and ongoing conversation context. Agents can accept or edit these suggestions before sending them to customers. You are leading the data science team responsible for designing and evaluating this AI assistant.
Describe how you would build and optimize such a system to handle diverse product-related inquiries and policy questions. Include details about how you would incorporate conversation history, policies, and product data when generating prompts for the Large Language Model (LLM). Propose specific metrics to assess the AI assistant’s performance, including both quantitative and qualitative factors. Explain how you would integrate real-time feedback from agents to further refine the model. Finally, explain how you might improve the assistant’s contextual capabilities over time.
Detailed Solution
System Architecture
A natural language pipeline would parse each incoming customer message and build a dynamic prompt for the LLM. The prompt must include relevant policy texts, product data, and the conversation’s history. A specialized template would inject essential constraints and instructions (for example, “Maintain consistent tone,” “Adhere to current shipping policy,” and “Suggest alternative products if out of stock”). The LLM then generates a candidate response. Sales agents see the suggestion, decide whether to use it as is, or edit it. The final text is sent to the customer.
Prompt Construction
Prompts should combine policy snippets, product information, conversation context, and desired response style. Each segment of the prompt must be concise to avoid context overflow. Guidelines must be explicit, so the LLM never strays into irrelevant or incorrect details. If the system identifies multiple relevant policies or product data, it appends them. The conversation history is included to provide coherence across messages.
Model Output and Post-processing
The LLM outputs token-by-token probabilities for each potential response. The highest-probability tokens are selected to form the final suggestion. This suggestion is displayed in an agent-facing interface, where the agent can revise or send. Any manual edits get logged.
Monitoring and Quality Checks
A second quality-assurance LLM can automatically evaluate the correctness, rule adherence, and clarity of the proposed responses. Agent feedback (“Why did I edit this suggestion?”) is captured. If edits occur because the assistant produced extraneous content, we label that scenario as “stylistic fix” or “factual fix.” Over time, the system learns the agent’s communication style and policy preferences.
Performance Metrics
Average handle time (AHT), order conversion rate, and agent adoption rate measure quantitative impact. Factual correctness and policy adherence measure qualitative success. The system should store logs of suggestions, final messages, and agent feedback. Continuous analysis reveals if the AI assistant is speeding up or slowing down the conversation, improving conversions, or generating mistakes.
Example of Levenshtein Distance
To measure how much the agent’s final message differs from the AI suggestion, define Levenshtein distance. If s is the LLM’s suggestion and t is the final agent message, distance(i, j) is the cost of transforming the first i characters of s into the first j characters of t. It is computed by a dynamic programming recurrence:
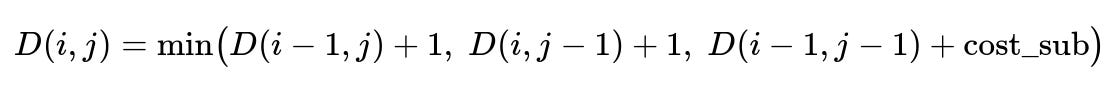
Where cost_sub is 0 if the i-th character of s equals the j-th character of t, else 1. This distance helps quantify how closely the final text follows the AI’s suggestion.
Python Snippet for Levenshtein Distance
def levenshtein_distance(s, t):
m, n = len(s), len(t)
dp = [[0]*(n+1) for _ in range(m+1)]
for i in range(m+1):
dp[i][0] = i
for j in range(n+1):
dp[0][j] = j
for i in range(1, m+1):
for j in range(1, n+1):
cost_sub = 0 if s[i-1] == t[j-1] else 1
dp[i][j] = min(
dp[i-1][j] + 1, # deletion
dp[i][j-1] + 1, # insertion
dp[i-1][j-1] + cost_sub # substitution
)
return dp[m][n]
This function returns the total number of insertions, deletions, or substitutions required to convert the suggestion into the agent’s final response.
Future Enhancements
Retrieval Augmented Generation (RAG) could provide real-time data queries, ensuring product specs and policies are always up to date. Fine-tuning the underlying LLM on historical chat data helps match top-performing agents’ style. As the system evolves, new training examples with agent feedback improve accuracy and trustworthiness.
Follow-up question 1
How would you handle situations where the LLM hallucinates information about product features or policies?
Answer: Hallucinations arise when the LLM fills knowledge gaps with false data. One solution is to enhance the prompt with precise product specifications and official policy text. Another solution is to incorporate a retrieval mechanism that fetches verified facts from a document store. If the assistant’s proposed response contains content not found in the verified source, that part is flagged or removed. This approach ensures the model stays grounded in actual data. Agents can also be prompted to tag incorrect responses, and those tags become training signals to reduce future hallucinations.
Follow-up question 2
How would you decide if the new AI assistant is truly beneficial compared to a simpler rule-based solution?
Answer: One method involves running an A/B test. Half of the agents use the new assistant, while the other half rely on a rule-based system. Measure AHT, conversion rate, and agent satisfaction. If the LLM-based system shows consistent reductions in handle time and improves customer satisfaction, it is more beneficial. Qualitative reviews by experienced agents or managers can complement these metrics. If performance gains are small or overshadowed by errors, additional fine-tuning or prompt engineering might be needed before a full rollout.
Follow-up question 3
Why is it crucial to track edit reasons and how can these insights feed back into model improvements?
Answer: Agent edits reveal exactly where the assistant goes wrong. If an edit reason is “policy mismatch,” the system likely needs updated policy data or better policy instructions in the prompt. If the edit is “stylistic fix,” the model might overuse certain phrases or tone. Tracking edit reasons highlights the most frequent failure modes. Fine-tuning the model on the corrected responses, or adjusting the prompt structure to fix specific mistakes, systematically reduces error rates. This targeted approach improves output quality and agent trust.
Follow-up question 4
How would you approach scaling this AI assistant to multiple languages for customers worldwide?
Answer: Multilingual support requires either training a multilingual LLM or maintaining separate models for each language. A multilingual LLM can streamline updates since new features can be added once. However, if certain languages require specialized domain terms (for example, region-specific shipping details), additional fine-tuning on targeted data is needed. Quality checks must include bilingual evaluators or language-specific QA models to verify factual correctness, style appropriateness, and policy alignment. Real-time feedback from agents in different locales and thorough localization of policy text ensure consistent accuracy across languages.