
ML Case-study Interview Question: AI-Powered Photo Curation: Building Automated Yet Controlled User Memories


Browse all the ML Case-Studies here.
Case-Study question
A technology firm faced a challenge with an enormous database of user-uploaded photos and videos. Many people rarely revisited old images, even though these captured memorable personal events. The company wanted to build an automatic “Memories” feature, which resurfaces meaningful past moments in a story-like format. They needed to detect and exclude poor-quality images, redundant shots, sensitive moments, and other undesirable items. They also wanted to let users hide or remove content they did not want to see again. How would you design and implement such a system, ensuring it balances automated curation with user control?
Proposed Solution
The system filters low-quality, duplicate, and sensitive images using a combination of non-pixel-based detection (metadata) and pixel-based models. Metadata flags items like screenshots, receipts, or images with low resolution. Pixel-based signals target blur, lighting, and near-duplicates. A separate process identifies images with potential emotional sensitivity. The user retains full control by hiding specific individuals (face grouping) or blocking dates to prevent the resurfacing of painful or private memories. The experience is presented in an immersive story format.
AI Model Training
The team trains a model that flags images for potential inclusion in the “Memories” feature. Labels or embeddings from a convolutional neural network identify people, objects, or settings. A second step scores image quality for exposure, sharpness, and composition. A confidence threshold determines if the image is recommended or discarded.
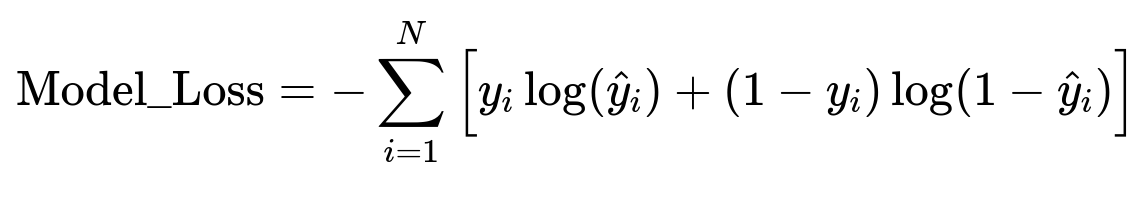
This loss function measures the cross-entropy between true labels y_i and predicted probabilities hat{y}_i. N is the total number of training samples. y_i is 1 if the image is suitable for resurfacing and 0 otherwise. hat{y}_i is the model’s predicted probability.
Under the hood, this means:
If the model sees an image with minimal blur and interesting content, it assigns hat{y}_i closer to 1.
If the model sees a repetitive or useless shot, it assigns hat{y}_i closer to 0.
Minimizing the above loss function pushes the model to assign correct probabilities.
Filtering Logic
Models alone do not solve everything. Rule-based filters remove screenshots or PDF scans using metadata. If the file format or resolution indicates a screenshot, the system drops it from consideration. This combination of learning-based and rule-based steps reduces edge-case errors.
User Controls
Users can hide faces or date ranges, removing them from future memory suggestions. If the model does resurface an unwanted moment, the user can remove it entirely. The design ensures that the system presents mostly positive or neutral memories by default, but respects personal preferences for any content.
Sample Code Overview
A Python pipeline might:
import cv2
import numpy as np
def filter_out_screenshots(image_path):
# Check resolution or aspect ratio
# If it meets screenshot criteria, return False
return True # or False
def blur_score(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Higher variance means sharper image
variance = cv2.Laplacian(gray, cv2.CV_64F).var()
return variance
def select_for_memories(image_path):
if not filter_out_screenshots(image_path):
return False
if blur_score(image_path) < 100.0:
return False
# Additional checks for near-duplicates or sensitive content
return True
This snippet checks if an image is a screenshot or too blurry. Real-world code would integrate face detection, object recognition, and user-specific rules.
How would you handle these follow-up questions?
How do you ensure sensitive events like funerals or breakups are recognized without too many false positives?
Sensitive events often share visual overlaps with ordinary gatherings. Classifiers can fail if they rely on color or dress code. The system could apply a hybrid approach: face clustering, textual cues from user captions (if available), and historical context. If the model still fails, user controls fill the gaps. Users hide the specific faces or entire date ranges that generate painful memories. The system learns these preferences as feedback signals. Over time it refines its predictions but keeps user overrides as the final authority.
Why not rely entirely on AI-based filtering instead of combining AI and rule-based steps?
The problem is partly solved by metadata. Screenshots, scanned documents, or parking receipts have consistent formats that do not need a neural network to identify. Rule-based checks are simpler, faster, and often more reliable for these patterns. The AI models focus on subtler tasks like aesthetic scoring or advanced content recognition. Splitting the workload leads to better performance and fewer misclassifications.
How do you handle the computational cost of large-scale image analysis?
The system processes metadata filters first because they are lightweight. This step drastically reduces the number of images that reach the pixel-based models. The pixel-based analysis then runs offline or in micro-batches. The pipeline can utilize distributed systems like Apache Beam or a large-scale dataflow engine. Images might be preprocessed and cached. GPUs or specialized hardware handle deep learning tasks, allowing real-time or near-real-time performance.
How would you measure success?
Success metrics track user engagement and user satisfaction. Engagement can be the frequency of “Memories” viewed or shared. Satisfaction can be measured by how often users hide or remove an unwanted memory. A high rate of immediate removals might indicate the model is surfacing too many undesirable events. Surveys or voluntary user feedback can supplement this data, revealing whether the suggestions feel genuinely meaningful. A separate metric is the fraction of negative feedback events, guiding whether additional improvements are needed for the curation logic.
What would be your approach if you wanted to create personalized memory themes (like pets or travel) for each user?
A theme-based pipeline tags images by context. A user traveling might have location metadata or geotags. A user with pets might have many pet faces recognized by the face grouping model. The system aggregates relevant images, sorts them by quality scores, and yields a theme-based memory. The user can fine-tune suggestions by approving or hiding certain images or entire themes. This feedback can help the model adapt quickly to personal preferences.
How do you validate the model’s performance for diverse cultural or personal preferences?
Training sets must reflect the diversity of global user bases. External domain experts (e.g., cultural consultants) can help identify edge cases like funerals or weddings that do not match Western norms. Testing includes a wide range of cultures, lifestyles, image capture styles, and events. A user feedback loop remains crucial. Regardless of model accuracy, some scenarios are highly individual. Providing robust user controls ensures that each person can override the defaults.
Would you store or process the user’s private photos on external servers for this?
Processing typically happens on secure servers that follow strict data handling policies. Sensitive operations can be optimized to run locally on the device if possible, but large-scale classification often requires back-end resources. Encrypted channels handle data transfer. Access controls prevent unauthorized use. Minimizing data retention helps. The system might store only essential embedding features or metadata, not the entire image. Privacy frameworks like differential privacy or federated learning can also be explored, depending on the scale and user acceptance.
Could you incorporate advanced personalization without risking privacy violations?
Yes, by doing inference on-device or through secure enclaves. For large-scale personalization, embedding vectors can be aggregated in anonymized form, decoupled from user identities. The result is a general, improving model that respects personal data boundaries. The user’s device re-links embeddings to specific images. Fine-grained settings let the user control how much data is shared or stored.
What are the biggest risks of shipping a feature like “Memories” too early?
Surprising or painful images might be shown, damaging user trust. Inaccurate or insensitive suggestions could spark negative publicity. Insufficient user control might cause frustration or privacy concerns. Data security lapses could lead to personal photos being exposed. Thorough testing with large, diverse samples and robust user interface controls are essential. Otherwise, a rushed release might do more harm than good, overshadowing the benefits of helpful AI-driven curation.