
ML Case-study Interview Question: Video Recommendation Pipeline: Ensemble Ranking for Freshness, Diversity, and Engagement


Browse all the ML Case-Studies here.
Case-Study question
A media streaming platform manages a large library of new and existing videos. They want to upgrade their mobile app’s home feed recommendations so that users see relevant, recent, and interesting videos with enough diversity to keep them engaged. All users must log in to the app, so the platform can leverage user-specific features like indicated interests or watch history. The goal is to deliver a simple but effective recommendation system in record time by starting with a basic prototype, monitoring real-world results, and iterating swiftly. You have to design the solution. How would you structure the entire pipeline, from candidate selection to ranking and final display? How would you ensure freshness, diversity, and user engagement metrics are satisfied? How would you handle new users with sparse data, and how would you refine the system over time as more user feedback arrives?
Proposed Solution
The system is divided into two stages: candidate selection and ranking. The platform first fetches potential videos from reliable sources, then ranks and merges them into a final list. This final list relies on a simple weighted approach, an exploration mechanism to show newer videos, and a diversity-based reshuffling step.
Candidate Selection
This stage starts by grouping videos according to each user’s stated interests. When a user opens the app, the system samples a roughly equal share of videos from every interest to avoid letting a high-volume interest dominate the feed. This method, known as stratified sampling, combats unbalanced data and guarantees each user sees content from all interests.
Ranking
Videos are then ranked using an ensemble of rankers:
A Freshness & Performance Ranker assigns each video a score based on attributes like how recently it was published, its real views ratio, how long on average it was watched, and its aspect ratio. A weighted sum aggregates these features:

Below is a textual explanation of the parameters:
Freshness measures how recent the video is.
RealViewsRatio is (number of 10+ second views) / (total views).
WatchRatio is (total watch time) / (video duration).
AspectRatio indicates how well the video fits a mobile screen (for example, vertical or square formats).
An Exploration Ranker randomly chooses from the top candidates of the previous ranker to give newer or less popular videos a chance. This prevents the same high-performing videos from continuously dominating the feed.
A Diversity Ensurer reduces redundancy by looking at how similar the recommended videos are. After picking the first video, the system picks the next video that is least similar to those already chosen. This ensures users see varied topics.
When finalizing the list, the system interleaves videos from the various rankers according to preset probabilities. This mix balances exploration and performance.
Handling Cold Start
New users choose their interests on signup. This helps the system show a balanced set of videos from those categories. Over time, actual user signals (like watch times and likes) allow the rankers to adapt and personalize further.
Evaluation
The platform measures success by median watch time. This is robust against outliers and punishes clickbait because those videos typically get abandoned early. Once a recommendation pipeline is in place, real-world user engagement patterns help fine-tune weights and add more features.
Iteration
After rollout, the team monitors performance metrics. They adjust weights for the rankers, or incorporate more context like user watch history or subscriptions. The system’s modular design makes it easy to swap or add new rankers without major rewrites.
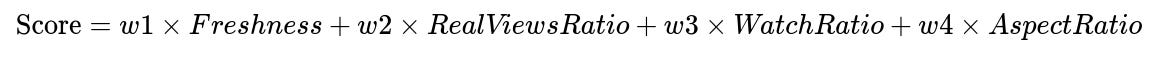
How would you handle large-scale implementation across millions of users?
A carefully distributed pipeline is key. Each user request should first hit a service that returns candidate videos based on user interests. A load-balanced approach fetches ranked results. Weights and fresh data can reside in a fast NoSQL store or caching layer for quick lookups. A separate feedback loop collects watch times and user behaviors for model updates or retuning.
Explanation
When many users request recommendations simultaneously, a single machine’s memory or processing power is insufficient. Spreading tasks across a cluster makes it possible to fetch, rank, and blend results in near real time. Caching frequently requested data speeds up responses, while a job scheduler or streaming system can handle continuous model updates or parameter tuning.
Why not push only revenue-maximizing videos?
Optimizing purely for clicks or ad impressions can degrade user experience and harm long-term retention. Many clickbait videos can generate clicks yet yield low watch time, leaving users dissatisfied. By emphasizing watch metrics instead of immediate revenue, the system promotes higher-quality content and user satisfaction, which in turn leads to better long-term engagement.
Explanation
User trust is easily lost if the platform serves low-value content. A focus on meaningful engagement ensures a healthier user relationship and boosts retention. If watch time steadily climbs, ad exposure also improves over the long run, as users stay on the platform.
How would you handle personalization for more mature users?
Upgrading the approach with behavioral data is crucial. Logs containing watch history, likes, and channel subscriptions provide deeper understanding of each user’s tastes. The system can then refine the candidate set and weighting scheme based on each user’s explicit and implicit feedback.
Explanation
When enough data accumulates, the platform can move beyond interest-based sampling to embed each user and each video in a latent vector space. The system can then compute a similarity score between user and video embeddings to decide what to serve next. This expands the approach to include robust methods like Matrix Factorization or deep learning–based collaborative filtering without sacrificing the simplicity of the existing pipeline.
How would you ensure the recommendations remain transparent and understandable?
Features like the user’s stated interests, the video’s performance metrics, and recency can be easily displayed or explained. The system ensures each ranker uses straightforward numerical signals to score videos. When a user wonders why a certain video appears, the platform can point to the relevant features: “This is new and aligns with your interest in Tech” or “You often watch cooking videos, so here is a top-performing recipe video.”
Explanation
Using interpretable numerical features fosters trust. For instance, if the user sees repeated coverage of a specific topic, the system can highlight that the user’s interest in that topic is driving the recommendations. Explanations encourage positive engagement and allow users to control or adjust their interests.
How would you refine the approach long term?
Data science teams watch for shifts in user behavior and domain changes. They continuously review metrics such as watch time, skip rates, and user churn. As the platform evolves, new rankers or features may be added, outdated ones removed. The high-level structure remains the same: candidate generation, ranking, then diversity merging. But the underlying algorithms adapt to keep up with new usage patterns.
Explanation
This iterative loop draws on observed real-world data: new content, user feedback, changing tastes, and business objectives. A robust pipeline design ensures new components can be tested (often through A/B testing) before wide deployment.