
ML Case-study Interview Question: Boosting Ad Performance with ML: GBDT-Ranked Recommendations for Bids, Budgets, and Targeting.


Browse all the ML Case-Studies here.
Case-Study question
A large visual discovery platform wants to improve advertisers’ campaign performance on its platform using machine learning. Advertisers have many customizable parameters (bid, budget, targeting) but often set these sub-optimally. Propose a system that generates recommendations for parameters like bids, budgets, and expanded targeting settings. Then propose a mechanism to rank these recommendations, so advertisers see the most impactful suggestions first. Provide details on how you would:
Identify under-performing campaign parameters.
Generate feasible recommendations for each parameter.
Leverage historical data to improve recommendation accuracy.
Rank and personalize recommendations using advanced models.
Detailed solution
Overview
The system analyzes under-performing advertiser parameters (bids, budgets, targeting) and recommends values or settings to optimize campaign reach and efficiency. Historical campaign data, auction data, and performance signals (impressions, clicks, conversions) provide insights. Each recommendation type can improve a key performance indicator like impressions or cost efficiency. A separate ranking model then ensures advertisers see the most valuable recommendations first.
Bid Recommendation
The platform records each auction an ad group participates in. For losing auctions, it computes the bid amount needed to win. For winning auctions, it computes the minimal bid that would lose. These values form a curve of additional winning vs. losing auctions for various bid changes. The system suggests a new bid that maximizes potential winning auctions without overshooting budget constraints. The difference between new and old bid is presented along with an expected improvement in impressions.
Budget Recommendation
Campaigns with stable cost efficiency can benefit from higher budgets. The system analyzes historic spend and potential impressions for different budget levels. If a campaign is capped, it might miss additional conversions. By simulating how many additional auctions could be won at higher budgets, it recommends an increase that balances cost-efficiency goals with the desire for more reach.
Expanded Targeting Recommendation
Advertisers often miss potential audiences by limiting interests or keywords. A neural retrieval model, using user and pin embeddings, locates relevant ad placements automatically. An under-delivering campaign might have narrow targeting. A Gradient Boosting Decision Tree (GBDT) regression model predicts how many more impressions an ad group could get if expanded targeting is enabled. If the expected increase is substantial, the system recommends enabling expanded targeting.
Recommendation Ranking
A classification model (GBDT) predicts the probability that an advertiser will click and adopt each recommendation. It considers advertiser features (historical performance, account attributes) and recommendation features (type, past acceptance rates). The model outputs a score for each recommendation, which is sorted in descending order to prioritize the most compelling suggestions.
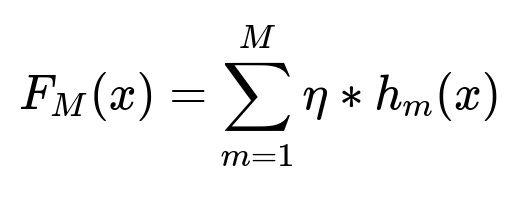
Here F_M(x) is the final model prediction after M boosting rounds, h_m(x) is the weak learner at iteration m, and eta is the learning rate. The model uses advertiser-level data, recommendation context, and past click outcomes to learn which factors drive positive adoption. Inference sorts recommendations by their predicted adoption probability. This ranking reduces cognitive overload by surfacing only the highest-scoring items.
Example Implementation Approach
A pipeline ingests ad group auction data, current bid/budget info, and performance metrics. It then runs logic for each recommendation type, storing results in a database. A separate ranking module runs the GBDT classification model on each recommendation to generate an adoption probability. The highest scores are served in the advertiser's dashboard. If an advertiser clicks to accept a recommendation, the system’s feedback loop captures that acceptance outcome to retrain models.
Python Code Snippet Illustrating GBDT Ranking (Conceptual)
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
# Suppose we have a DataFrame 'training_data' with columns:
# user_features, notification_features, label (1 if recommendation was adopted, 0 if not)
X = training_data.drop('label', axis=1)
y = training_data['label']
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3)
model.fit(X, y)
# Inference
# 'new_recs' has user_features + notification_features for fresh recommendations
predictions = model.predict_proba(new_recs)[:,1]
sorted_indices = predictions.argsort()[::-1]
ranked_recs = new_recs.iloc[sorted_indices]
The training set includes instances of how advertisers interacted with past recommendations. The model learns which signals correlate with positive adoption. During inference, it produces probabilities of adoption, and the recommendations are sorted in descending order.
Common Follow-up Questions
How do you ensure the system remains stable if bids or budgets become too large?
The approach uses historical spend and performance to generate a curve of potential returns. It caps recommendations once marginal gains diminish or budgets become too high. Business rules can limit certain abrupt changes. Large jump proposals are throttled to avoid overspending or overshooting cost targets.
How do you address cold-start scenarios for new advertisers or those with little data?
The system bootstraps from global or segmented averages. For targeting expansion, it relies on deep models that match pin content with user embeddings even if an ad group has no history. For bid and budget recommendations, it uses aggregated auctions and then refines estimates as data accumulates.
What techniques do you use for improving GBDT-based ranking quality over time?
Feature engineering is critical. Extra features include advertiser account age, seasonality patterns, prior recommendation acceptance rates, device-level interactions, and more. Regular retraining adapts the model to shifting advertiser behaviors and platform changes. Hyperparameter tuning, ensemble stacking, and cross-validation help maintain performance.
How would you validate that your recommendation system is truly driving advertiser success?
A/B testing and incremental adoption metrics measure real impact. One group sees the new recommendation engine, while a control group sees older suggestions or random ordering. Key metrics: acceptance rate, subsequent lift in impressions or conversions, and revenue impact. Analysis separates correlation from causation by ensuring well-designed experimental controls.
How do you handle contradictory recommendation types?
A single ad group might receive both a “raise bid” and “decrease bid” suggestion if data is conflicting. The ranking model identifies which suggestion is more likely to drive positive outcomes. The system may also merge or filter contradictory items. Business constraints or threshold-based logic can suppress obviously conflicting recommendations.
How is performance measured for the ranking model itself?
The ranking model’s success is measured by adoption AUC (Area Under ROC Curve) and precision at top K recommendations. If an advertiser systematically accepts or clicks on top-ranked suggestions, it indicates strong ranking alignment. Offline metrics guide iteration, and online metrics confirm real-world performance.
Why is it important to store and use adoption feedback?
The model learns from explicit signals (accept/reject) and implicit signals (time spent, partial acceptance). Such feedback reveals patterns in advertiser preferences. Continuous feedback loops ensure that each generation of recommendations is better aligned with advertiser goals. Over time, the system refines itself as more data flows in.