
ML Case-study Interview Question: Multilingual Customer Message Classification and Routing Powered by BERT


Browse all the ML Case-Studies here.
Case-Study question
You are working at a fast-growing online retail platform operating in multiple countries. Your Customer Support team handles thousands of daily messages in different languages across email, in-app, and chat channels. They need an automated way to classify incoming messages by topic and sentiment, then route them to the right support agents. Initially, you built separate logistic regression models, each with its own language-specific tokenizer, but the system struggled when you launched in new markets without enough training data. You also noticed you were missing messages written in unexpected languages. Finally, you wanted to reduce overhead by consolidating models. How would you architect and implement a new multilingual classification solution to handle these challenges, while keeping operational continuity?
Detailed solution
Background
The original approach relied on logistic regression for each language and channel. Each message was tokenized separately, then classified according to topic. This created high maintenance cost, made it tough to onboard new languages, and left many messages unclassified when they were written in a language outside the model’s scope. A modern Transformer-based method, specifically a multilingual BERT, can solve these problems by ingesting messages of any supported language into a single unified model.
Old approach using logistic regression
The logistic regression model calculates the probability p(y=1|x) for a binary classification with the formula:
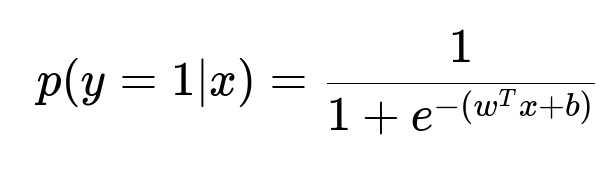
Here, p(y=1|x) is the predicted probability that the label is 1 for the input x. w is the learned coefficient vector, x is the input feature vector (such as bag-of-words or TF-IDF embeddings), and b is the bias term.
This approach worked but required a separate tokenizer and model for each language-channel combination, and it often failed when new languages lacked sufficient data. The system struggled with cold starts in new markets. It also missed messages written by users in other languages.
Proof-of-concept using multilingual BERT
A multilingual BERT can handle multiple languages in one model. A core Transformer component is self-attention, which learns context across sequences:
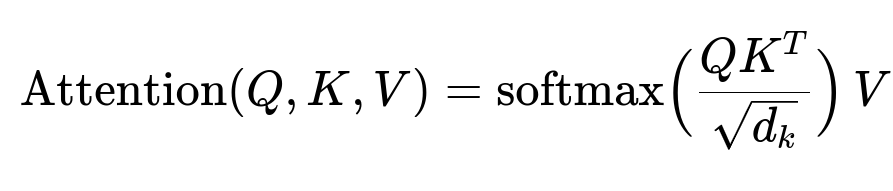
Here, Q, K, and V are the query, key, and value matrices derived from the token embeddings, and d_k is the dimensionality of the key vectors. BERT uses multiple layers of attention to capture rich language representations in a shared multilingual embedding space.
To validate this architecture, a small proof-of-concept filtered out “thank you” or closure-type messages. Human annotations provided labeled examples across all existing languages, then a single multilingual BERT (for instance, distilbert-base-multilingual-cased) was fine-tuned. Results showed a large improvement in recall, reducing manual triage by half.
Full roll-out
Encouraged by the proof-of-concept, the entire routing system migrated to a unified multilingual BERT classifier. Rather than training separate logistic regression pipelines, the team consolidated data across all countries and labeled it with fine-grained topics. With millions of training examples, the model learned to classify messages for all languages in one shot.
This solved several issues:
One global model replaced multiple language-specific models.
New markets no longer required from-scratch training.
The model recognized languages outside of the platform’s official ones.
Classification performance rose sharply due to richer contextual embeddings.
Implementation details
Data was collected from various support channels, then preprocessed by removing sensitive information. The model was fine-tuned with standard cross-entropy loss, using only the message text and the known labels. This drastically simplified feature engineering. The final model was deployed on the existing cloud infrastructure. Careful canary releases ensured continuity: a small traffic subset was routed to the new model while monitoring error rates. After confirming stability, the system was fully switched over.
Follow-up questions
1) How would you handle a new market with very little data to train on?
Use the existing multilingual BERT, which already has robust general language representations. Fine-tune it with the minimal new-market data you have, but also leverage the older markets’ data. The model’s shared multilingual embeddings let it adapt quickly. If the new language is entirely unseen, bootstrap with labeled data from other similar languages. Gradually collect more user messages to improve performance. Monitor confidence thresholds; uncertain classifications can be queued for human review to gather more labeled data.
2) How would you ensure data privacy, given that sensitive information could appear in customer messages?
Mask or remove personally identifiable information (PII) before storing or processing texts. For example, replace names, addresses, or payment details with placeholder tokens, then maintain a mapping in a secure location. Encrypt raw logs at rest and in transit. Restrict model training data access to authorized personnel. If the compliance requirements are strict, consider on-premise or private-cloud deployments where you control the entire pipeline.
3) Why not use a hosted large language model (LLM) from a third party?
Two reasons: cost and control. A third-party LLM with strong multilingual capabilities might be expensive to run at scale, especially with high daily message volume. You also lose some control over data, which can be risky if it’s sensitive. A local multilingual BERT is cheaper and can be fully managed in-house, making it easier to track and audit data handling. You keep internal expertise and maintain interpretability through smaller, well-understood models.
4) Why did the cold start problem arise with the older approach?
Each logistic regression model had limited scope and had to be trained from scratch for each new language. Without enough labeled examples, the model produced unreliable predictions. The multilingual BERT approach eliminates separate language tokenizers and leverages shared parameters across languages, so new languages benefit from existing patterns. Fewer samples from the new market are required to see acceptable performance.
5) How would you improve the model’s confidence calibration?
Evaluate calibration metrics like expected calibration error on a validation set. Use temperature scaling or Platt scaling to adjust output probabilities. Adjust hyperparameters that affect confidence distributions during training. Encourage the model to predict “unknown” for ambiguous inputs, routing them for manual review. Track real-world feedback on classification confidence to refine calibration further.
6) What if you wanted more granular classifications, such as subtopics under each broader issue?
Expand the label set and gather enough annotated examples for each subtopic. Fine-tune the same multilingual BERT on a multi-class or hierarchical classification task. If subtopics change frequently, consider a dynamic taxonomy that uses embeddings to cluster messages in real time. With BERT’s contextual nature, it can generalize subtopics from examples. Confirm these new labels with customer support stakeholders, then retrain or do incremental learning.
7) How would you integrate sentiment analysis into the same pipeline?
Add a separate output head for sentiment detection or train a multi-task model with intent and sentiment labels together. BERT’s encoder would feed two classification heads, one for topic and one for sentiment. This multi-task setup shares embeddings while learning specialized layers. Confirm it meets latency and memory constraints, then monitor if each task’s performance remains high.
8) How would you handle inference latency with Transformer-based models at scale?
Use lightweight variants of BERT like DistilBERT or quantized models to reduce size and speed up inference. Deploy on GPUs or specialized hardware with efficient batching. Scale horizontally with more instances behind a load balancer. Use asynchronous request handling if needed. Profile real-time performance and memory usage, then optimize with techniques such as TorchScript or ONNX runtime.
9) What if messages arrive with code-mixed language (mix of two languages in one sentence)?
Multilingual BERT embeddings can handle code-mixed inputs because it learns cross-lingual patterns. If the mix is common, fine-tune the model on that style of text. If accuracy remains low, gather more code-mixed examples, label them, and retrain. Evaluate the model specifically on code-mixed examples. If necessary, incorporate language detection heuristics or domain-specific augmentation.
10) How would you adapt this system for fully unsupervised topic discovery instead of fixed-labeled classification?
Use a topic modeling approach with embeddings derived from BERT, such as clustering embeddings of messages. DBSCAN or hierarchical clustering can discover new topics on the fly. Evaluate cluster coherence and re-label them if needed. This unsupervised approach can be combined with partial supervision, where discovered topics are manually reviewed and assigned official labels before retraining a supervised classifier.