
ML Case-study Interview Question: Designing an LLM-Powered AI Recruitment Agent with Semantic Search and Orchestration.


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large technology enterprise. Your team is designing an AI-based recruitment agent to reduce the time recruiters spend on repetitive tasks. The system should interact with recruiters in natural language, analyze vast candidate pools, handle job postings, build shortlists, and even offer personalized suggestions for follow-up messages. The agent must maintain a log of all actions, learn recruiter preferences over time, and integrate data from an enterprise-wide platform to better understand candidate profiles. Recruiters must remain in full control of all agent actions and be able to override or edit any of the system’s recommendations. How would you design and implement such an agent from end to end, including ensuring trust, safety, and customization?
Detailed solution
Recruiters have a mix of structured data (job titles, skills, resumes) and unstructured data (notes, emails). An AI agent must unify all these elements in a secure, privacy-compliant framework. Deep language modeling and robust orchestration will be the foundation for this approach.
Overall architecture
A large language model is used as the core for interpreting recruiter queries, summarizing job information, and generating action steps. This is combined with an orchestration layer responsible for connecting the model to various system utilities such as candidate search, messaging, and scheduling services. The orchestrator transforms user intent into specific function calls, aggregates results, and presents them back in a concise manner.
Data ingestion and transformation
All relevant data sources, such as job descriptions, candidate resumes, prior recruiter notes, and real-time feedback, are aggregated and stored in a secure system. Features like candidate skill sets, job requirements, and recruiter preferences are extracted. The AI agent references these features to form queries for candidate retrieval and ranking.
Personalization strategy
A memory mechanism enables the system to track recruiter actions, choices, and feedback. This memory system updates the agent’s parameters or a supplementary preference model. Over time, this process refines how the agent ranks profiles or crafts suggestions.
Semantic search and ranking
Below is the core ranking function for candidate matching:
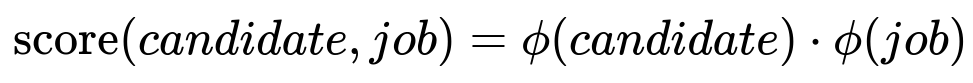
Here, phi(candidate) is the vector embedding of the candidate's profile, and phi(job) is the vector embedding of the job requirements. The dot product measures similarity. phi is learned from large-scale text corpora and fine-tuned on relevant recruitment data. Higher scores indicate stronger alignment between the candidate’s background and the job's qualifications.
Orchestration layer
The AI system uses the reasoning of the large language model to interpret each recruiter request, interact with a semantic search service, filter and rank candidates, and generate the final candidate list. It logs activities and explanations for each step. This log allows recruiters to see which data was used, when it was used, and how final results were derived.
Control and overrides
Recruiters maintain control by receiving the agent’s proposed actions before anything is executed. Each step is editable, ensuring that recruiters can stop, modify, or confirm suggestions. An audit log records all actions and text generation outputs for transparency.
Responsible AI measures
A content filtering layer is integrated to intercept low-quality or policy-violating outputs. Hallucination detection is handled through verification steps, such as cross-checking job requirements against an authoritative data store. Recruiters can provide explicit feedback, which continuously improves the system’s alignment with desired behaviors.
Example Python snippet
import openai
def generate_candidate_ranking(job_description, candidate_pool):
# Convert text to vector embeddings using a pretrained model
job_embedding = embed(job_description)
scored_candidates = []
for candidate in candidate_pool:
c_embedding = embed(candidate.profile_text)
similarity = dot_product(job_embedding, c_embedding)
scored_candidates.append((candidate, similarity))
# Sort by descending similarity
scored_candidates.sort(key=lambda x: x[1], reverse=True)
return scored_candidates
The snippet shows a simple approach for generating ranked candidates. The orchestration layer then processes these ranked lists, formats them for the recruiter, and requests confirmation before taking further steps.
How would you handle tricky follow-up questions?
1) How do you ensure the system does not recommend unqualified candidates due to biased embeddings?
Bias can surface if the embedding model associates certain attributes with groups in unintended ways. A data scientist can mitigate this by identifying bias indicators in training data, rebalancing data, and applying post-processing filters that remove or adjust features leading to discriminatory outcomes. Continuous monitoring of recommendations allows quick action if unusual patterns emerge.
2) What if a recruiter’s feedback is contradictory or changes rapidly?
Conflicting signals can occur, for example, if a recruiter initially prioritizes leadership skills but then focuses on niche technical competencies. The system must capture time-stamped feedback. A preference model can weigh recent feedback more strongly while keeping a history of broader preferences. If contradictions appear, the system asks clarifying questions instead of guessing.
3) How do you prevent sensitive or private data leakage in generated responses?
Sensitive data might inadvertently appear in AI-generated text, especially if the model was trained on broad corpora. This is addressed by a specialized safety filter that flags personally identifiable information, health data, or any other protected categories. The orchestration layer redacts or replaces private data with placeholders. Access control policies prevent the language model from retrieving data beyond the current user’s permission level.
4) How does the system adapt to new job roles or new skill sets not in its original training data?
The system is retrained or fine-tuned periodically on recent job postings, evolving skill requirements, and fresh market data. When encountering unknown terms, the model attempts to infer meaning from context. A fallback to direct recruiter input ensures that the system quickly integrates these new skills or roles.
5) How would you evaluate the agent’s performance beyond search result accuracy?
Metrics include time saved on administrative tasks, overall candidate conversion rates, and feedback from recruiters on recommendation quality. Performance on intangible aspects, such as user trust or perceived reduction of busywork, can be measured via satisfaction surveys and focus group sessions. Agent improvement is driven by analyzing these qualitative and quantitative metrics.
6) What is your approach to detecting and handling hallucinations in complex workflows?
A step-by-step verification procedure checks each recommendation. If the system suggests a candidate with a skill that is not reflected in the candidate’s profile, that suggestion is flagged. This triggers a routine that re-examines data sources or references past user feedback. When uncertain, the agent explicitly informs the recruiter to review the suggestion rather than present it as fact.
7) How would you maintain system performance at scale?
Shard candidate indices across multiple servers, and use approximate nearest neighbor search for embedding-based queries to quickly return top matches. Caching frequent queries and search results helps. The orchestration layer distributes workloads, and an asynchronous task queue processes agent requests in parallel. Monitoring CPU and GPU usage helps with proactive scaling strategies.
8) How do you handle repeated user queries or frequently automated tasks?
A session memory component tracks short-term context. Repeated tasks, like drafting a standard follow-up message, are identified and delegated to an automated workflow. If the agent sees a repeated pattern—such as the same set of filters or the same standard message—this is queued as a reusable template. Recruiters can tweak or approve these templated actions, saving time while maintaining oversight.
9) How do you deal with errors in production?
Extensive logging and monitoring expose system failures or incorrect suggestions. Alerts are triggered when error rates spike or user override frequency surpasses a certain threshold. A safe rollback or fallback mode reverts to traditional recruitment tools. Error details are stored for post-incident reviews, guiding bug fixes and iterative model improvements.
10) How would you approach ongoing improvement of this system?
Implement a feedback loop where recruiters can vote on or annotate the accuracy of candidate recommendations. Combine these annotations with usage metrics to fine-tune model weights, refine the memory module, and adapt to new hiring practices. Maintenance of an up-to-date skill taxonomy ensures that the system remains aligned with current industry trends.
Recruiters need tangible help from AI that addresses the real pains of their workflow without compromising on oversight and trust. By combining a strong language model core, a careful orchestration layer, and robust safety checks, the proposed agent streamlines repetitive tasks while letting humans handle the final decisions.