
ML Case-study Interview Question: Enforcing Quality Software Change Titles with Rule-Based NLP


Browse all the ML Case-Studies here.
Case-Study question
An organization wants to enforce high-quality descriptions for each software change request. They require a single concise title (limited to 300 characters) that clearly states what is being changed and why it is being done. The aim is to ensure stronger commercial focus, better engineer accountability, more targeted reviews, and improved collaboration between product and engineering. Propose a data-driven solution that automates this enforcement, integrates easily into existing workflows, and handles large-scale adoption without sacrificing accuracy.
Detailed Solution
Overview
Engineers submit change requests with titles that must include what is being changed and why. A Natural Language Processing tool checks each title to ensure it contains both components. The system blocks merge requests if the title fails these checks. Accuracy on test samples needs to remain high to avoid developer frustration.
NLP Approach
A rule-based system splits incoming text into sentences, tokenizes words, tags them with parts of speech, and looks for noun + verb to identify what is happening. For the why component, it checks for specific conjunctions such as "as", "because", "in order to", or "to" followed by a verb. Titles without these constructs are rejected.
Title Analyzer Logic
Tokenization uses a standard library that separates punctuation from words. Each token is tagged with a grammatical category (noun, verb, etc.). A simple check confirms that at least one noun and one verb are present. A second check confirms the presence of a recognized conjunction pattern indicating why.
Model Performance
Accuracy is measured by comparing correct classifications (valid vs invalid titles) against total samples. The rule-based system reached around 93% accuracy on over 3000 real-world titles.
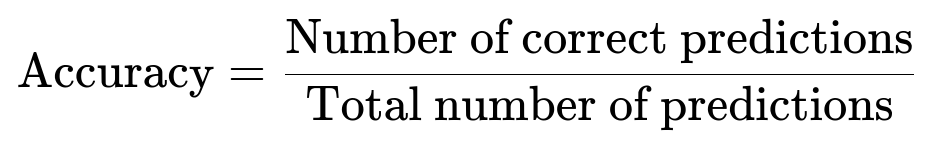
Accuracy remains stable because the rules are simple, explainable, and tuned over time with false positives/negatives.
Integration in CI/CD
The analyzer is exposed via an API. Each new merge request calls the API with the proposed title. A "pass/fail" response gates the pipeline. Failing titles prompt the user to update and resubmit. This direct enforcement pushes developers to create clearer titles.
Example Code Snippet
import spacy
nlp = spacy.load("en_core_web_sm")
def is_valid_title(title):
doc = nlp(title)
sentences = list(doc.sents)
# Simple check: at least one sentence must have noun+verb
# and a recognized conjunction or "to" followed by verb
has_what = False
has_why = False
conjunctions = {"as","because","since","in order to","so that","due to","therefore"}
for sent in sentences:
words = [token.text.lower() for token in sent]
pos_tags = [token.pos_ for token in sent]
if any(token.pos_ == "VERB" for token in sent) and any(token.pos_ == "NOUN" for token in sent):
has_what = True
# Check for recognized patterns
if any(phrase in sent.text.lower() for phrase in conjunctions):
has_why = True
# Special rule for "to" followed by a verb
for i, token in enumerate(sent):
if token.text.lower() == "to" and i + 1 < len(sent) and sent[i+1].pos_ == "VERB":
has_why = True
return has_what and has_why
test_title = "Updating the dependency to support Java 21 upgrade"
print("Valid title?", is_valid_title(test_title))
This example uses spaCy for tokenization and part-of-speech tagging. The function checks for the presence of a noun, a verb, and a relevant conjunction pattern.
Follow-up Question 1
How would you handle false positives and false negatives in this rule-based approach?
A valid title might fail if it uses an uncommon phrasing. A poor title might slip through if it accidentally matches the pattern. Frequent errors damage trust in the system.
Detailed Answer
Regularly maintain a feedback loop. Collect failing titles that should pass and passing titles that should fail. Expand or refine rules with more known synonyms or conjunctions. Avoid overfitting by checking whether changes degrade overall accuracy on a separate validation set. Keep the logic transparent so developers can suggest missing patterns.
Follow-up Question 2
Why not use a machine learning classifier instead of a rule-based approach?
Detailed Answer
Machine learning could capture more nuances but requires a labeled dataset, frequent retraining, and can be opaque for developers. A rule-based approach is cheap, transparent, and easy to integrate. Machine learning might be beneficial for advanced context extraction, but maintaining high precision out of the box might require significant data and monitoring overhead.
Follow-up Question 3
How do you ensure adoption across many teams with minimal workflow disruption?
Detailed Answer
Embed the analyzer check in the continuous integration pipeline. Provide clear error messages when a title fails. Keep the system near-zero in overhead. Pair the automatic checks with cultural advocacy so teams see the commercial and collaborative benefits. Give each team a quick reference and examples. This mix of enforcement and education fosters acceptance.
Follow-up Question 4
What if the conjunction list is incomplete?
Detailed Answer
Add a mechanism for developers to report repeated blocks that they believe are correct. Update the conjunction dictionary and incorporate special cases (e.g., "thus", "thereby") as they emerge. Create a small back-end system for managing these keywords. Monitor overall accuracy after each addition to ensure no major regressions.
Follow-up Question 5
How do you address the commercial aspect of "why"?
Detailed Answer
Encourage engineers to link each "why" to business value, performance impact, or user experience. The system only checks that some reason is given. Product managers can help refine this language. The combination of cultural guidance and the analyzer’s technical enforcement prompts more explicit statements of commercial benefit.
Follow-up Question 6
What if you need to scale beyond thousands of requests per day?
Detailed Answer
The rule-based approach is computationally light. A containerized API can handle parallel requests. Horizontal scaling with multiple instances supports high traffic. A caching layer can store repeated or similar requests, but this might be less critical since the CPU cost is low. Monitoring resource usage ensures timely addition of capacity as volume grows.