
ML Case-study Interview Question: Real-Time Wholesale Product Ranking using Elasticsearch Retrieval and XGBoost Re-ranking


Browse all the ML Case-Studies here.
Case-Study question
A large online wholesale marketplace wants to replace its basic retrieval and ranking system for products. The existing system relies on MySQL queries and nightly batch-computed scores. This causes inconsistencies and limits personalization. They need real-time retrieval for text-based search, category navigation, and brand pages, and must then re-rank the retrieved results using more sophisticated, personalized models. The marketplace Data Science team requires sub-500ms latency, a unified retrieval method, a developer-friendly feature store, real-time and offline feature pipelines, and a fast re-ranker able to handle millions of products. They also want monitoring, alerting, and data consistency between training and inference. How would you architect and implement a new system to achieve these goals? Propose a solution from end to end and highlight what models or techniques you would use. Explain your design choices. Describe how you will track success. Include how you handle potential failures, scale, and future model upgrades.
Proposed Solution
A real-time ranking platform consists of multiple components stitched together to handle retrieval and re-ranking in a single pipeline. Retrieval narrows down candidates. Re-ranking uses a model to score each candidate. Then a final ranking is returned to users with personalization and secondary objectives applied. Each part must integrate seamlessly.
Retrieval
Use Elasticsearch for a unified retrieval approach on all search surfaces. Index products with fields like title, description, category tags, brand, and embeddings. A typical setup fetches about 1000 matching products per query. BM25 is useful for initial text scoring.
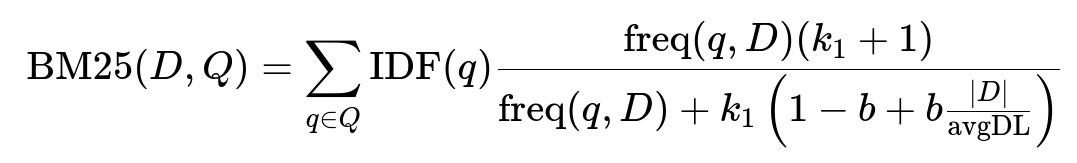
freq(q, D) is the frequency of term q in document D. IDF(q) is the inverse document frequency of q. k1 and b are constants controlling term saturation and length normalization. |D| is the document length and avgDL is the average document length in the index.
For category navigation, filter products by category tag. For brand pages, retrieve all products of that brand. For recommendation surfaces, index item embeddings and use approximate kNN retrieval. This ensures consistent data schemas, quick queries, and easily adjustable filters.
Feature Store
Split features into offline batch-computed and online real-time. Store offline features in a key-value database like Redis for fast lookup. Compute online features using a backend service that merges session signals (recent views, searches) with offline data. Expose these features to the re-ranker in a single request flow. Some features are numeric aggregates (click rates, conversion rates). Others use vector embeddings. For a new feature, implement minimal code in the feature pipeline so you can quickly integrate it into the model.
Example Python snippet for an embedding similarity feature:
def compute_embedding_similarity(retailer_embedding, product_embedding):
# Dot product or cosine similarity
dot = sum(r * p for r, p in zip(retailer_embedding, product_embedding))
norm_r = sum(r*r for r in retailer_embedding)**0.5
norm_p = sum(p*p for p in product_embedding)**0.5
return dot / (norm_r * norm_p)
def get_embedding_similarity_features(retailer_id, product_id):
retailer_vec = fetch_retailer_embedding(retailer_id)
product_vec = fetch_product_embedding(product_id)
sim_score = compute_embedding_similarity(retailer_vec, product_vec)
return {"retailer_product_similarity": sim_score}
Model Training
Train XGBoost with pointwise losses. Log all features and outcomes (like add-to-cart events). Pull these logs into the data warehouse, join them with labels, and re-train. This guarantees data fidelity because the same feature logic applies in production. A daily or weekly training schedule captures changing trends.
Model Store
Save the trained model and metadata in an S3 bucket or similar storage. A model deployment setting references the stored model artifact. Update the reference to swap models with minimal code changes.
Inference and Re-ranking
Fetch around 1000 products from Elasticsearch. Compute or retrieve all features. Score each candidate with the XGBoost model. Optionally apply a secondary ranker for tie-breaking or business rules. Keep total latency under 500ms by caching frequently accessed features, optimizing code paths, and monitoring performance.
Monitoring and Alerting
Track throughput and latencies. Alert on anomalies in feature coverage or scoring. Monitor offline vs. online distributions of features to catch data drift. Ensure logs feed your data warehouse for offline debugging and re-training.
Handling Scale and Future Upgrades
Add more shards or nodes to Elasticsearch. Transition to approximate kNN if expansions happen in similarity-based retrieval. Add neural network re-ranking or new large-scale embeddings. Maintain the same real-time pipeline. Keep the feature store design flexible to accommodate new features.
Possible Follow-Up Questions
How do you ensure personalization without exploding storage costs for pairwise features?
Use embeddings and dynamic similarity calculations at request time. Store a single embedding vector per product or user. Compute pairwise metrics only when needed.
How would you design an experiment to measure the impact of a new ranking model?
Split traffic using an A/B test with a random fraction of users getting the new model. Compare click-through and add-to-cart rates. Roll out fully if metrics improve.
How do you deal with cold-start products or new retailers?
Fall back to generic popularity signals. Switch to personalized features once enough behavioral data is logged. Use textual features and brand-level signals during cold-start.
What happens if the Elasticsearch cluster fails or lags?
Implement fallback strategies. Cache some results in Redis or degrade to a basic MySQL-based approach. Add circuit breakers and real-time alerts. Auto-scale the cluster when needed.
How do you tune the XGBoost model’s hyperparameters?
Use random search or Bayesian optimization. Conduct grid searches on a validation set. Regularly review feature importance to refine or prune features.
Why use pointwise ranking rather than pairwise or listwise?
Pointwise is simpler to implement. It gives good performance with minimal complexity. Pairwise or listwise approaches may perform better in certain ranking contexts but can be more complex to train and serve.