
ML Case-study Interview Question: Building Ranked E-commerce Search Suggestions from User Clicks and Conversions


Case-Study question
A major e-commerce platform needs to improve its site search to match user expectations shaped by large-scale search engines. Users demand instant, relevant, and personalized results. The team has been capturing click and conversion events each time users search, then wants to harness that data to generate relevant query suggestions for an autocomplete box. They also need ways to ban inappropriate queries, choose a threshold for how often a query must appear to be considered a valid suggestion, and incorporate category-specific (scoped) suggestions. Propose a solution approach to achieve this, focusing on data collection, indexing, integration with a search front-end library, and preventing offensive content. Explain how you would build, configure, and maintain the system in production.
Proposed solution
Data collection happens by sending user events to a centralized analytics pipeline each time a user clicks or converts on a search result. These click and conversion events feed a specialized index that focuses on popular queries and how often users select items after typing them. Developers can send events manually or rely on an existing widget or library if one is available. After enough data is collected, a separate suggestions index is generated. The index only includes queries that meet a minimum frequency threshold to maintain relevance.
Query suggestions are ranked by a score reflecting usage frequency and conversion rates. One straightforward scoring approach is:
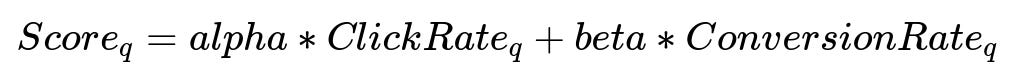
alpha and beta are weighting factors. ClickRate_q is the fraction of users who clicked on any result after searching for query q. ConversionRate_q is the fraction who performed a purchase or a defined conversion event for query q. Adjusting alpha or beta changes the relative importance of click behavior versus post-click behavior.
Building the suggestions index requires configuring a set of rules. One rule bans offensive queries by blacklisting terms. Another controls the minimum number of user searches for a query before it is eligible for display. Another may group suggestions by category so the autocomplete menu can show them under separate headings or tags.
The front-end autocomplete module connects to this suggestions index. Developers load a query suggestions plugin and pass it the specialized index name. The module displays suggestions as the user types. This approach can extend to scoped suggestions. The user sees “Shoes in Women’s Fashion” or “Blenders in Home Appliances” if the system includes category or filter metadata. That reduces friction because users can refine their searches faster.
Below is a JavaScript snippet (adapted to a generic library rather than referencing a specific provider). It shows how the team might integrate the query suggestions index into an autocomplete component:
import { autocomplete } from 'your-autocomplete-library';
import { createQuerySuggestionsPlugin } from 'your-autocomplete-plugin';
const searchClient = yourSearchClient('YOUR_APP_ID', 'YOUR_PUBLIC_API_KEY');
autocomplete({
container: 'CSS_SELECTOR_OF_YOUR_AUTOCOMPLETE_CONTAINER',
plugins: [
createQuerySuggestionsPlugin({
searchClient,
indexName: 'YOUR_QUERY_SUGGESTIONS_INDEX_NAME'
})
],
openOnFocus: true
});
Developers configure the plugin to fetch suggestions from the index. The index builds itself from stored events, so no extra back-end code is required apart from initial analytics tracking and pipeline setup.
Tuning the system happens by adjusting alpha and beta for scoring. Setting alpha higher rewards frequent queries, while setting beta higher rewards those with stronger conversions. Another tuning step involves managing the minimum query frequency threshold. This helps you avoid showing niche queries that confuse more users than they help.
A separate blacklist file or pattern matching system ensures no inappropriate or hateful terms ever appear. This file is updated whenever suspicious terms are discovered. Category-based suggestions come from storing metadata at index time, linking each query to categories. That metadata is appended to the suggestion results, which the front end displays with category labels.
Deployment and maintenance require consistent tracking of click and conversion metrics, periodic refreshing of the suggestions index, and user acceptance testing. The system scales because the index build process is incremental, meaning only queries with new data get updated with each pass.
How do you handle real-time changes in user behavior?
High-volume events can be processed in near real time if the analytics pipeline collects them immediately. The indexing job can run frequently (hourly or even more often) to keep suggestions current. Some pipelines use a streaming approach with micro-batching to add new queries to the index. Ensuring low-latency writes depends on a robust ingestion framework. A second factor is the size of the suggestions index. Lightweight indices allow faster rebuilds.
In production, a standard pattern is:
Events flow into a message bus or queue.
A job processes these messages in batches.
The job updates the suggestions index with the new tallies.
Maintaining good throughput is crucial. Leveraging a distributed system can handle large data volumes. If the platform must reflect new trends (for instance, unexpected surges in searches for a particular product), these frequent partial updates capture that behavior quickly.
How would you maintain quality and block offensive terms?
A special filtering step runs after logs are aggregated but before final indexing. This step checks if query terms match a blacklist or violate internal policies. Those terms never make it into the index, which ensures users never see them as suggestions. Category-based suggestions also require checks because category paths might contain sensitive content. An internal admin portal can let non-technical teams add or remove terms without going into the underlying code.
To avoid partial or ambiguous offensive words, the system can store a list of patterns rather than just exact matches. It can compare each new candidate suggestion against those patterns. If any match triggers, that query is flagged and removed.
How do you optimize relevance for mobile users?
Mobile devices have limited screen space. Only a few suggestions can be displayed at once. Users benefit from more precise suggestions. Setting a stricter minimum query frequency reduces clutter. Weighted scoring ensures that the top queries with the best conversion rates appear first.
Scoped suggestions also help. A user browsing a shoe category on mobile should see suggestions that reflect the footwear category. That focuses them on queries they are more likely to type. A single short text input is enough, but the platform supplies context from the user’s location or previous actions to scope suggestions.
Lazy loading or partial rendering is often used in mobile contexts. When the user starts typing, the system fetches top suggestions. A second background request can refine them if more relevant queries appear. This keeps the interface responsive.
How do you integrate category filters into the suggestions?
Categories attach as metadata when indexing. Suppose the raw analytics events also store the category where the query was used. The system aggregates frequency per category. The suggestions index stores query plus associated categories. The front-end plugin or widget looks for that metadata and displays something like “Run shoes in Men’s sports.” That format is simply a design choice. The data behind it is the query text plus the category label. A typical approach is to store multiple category labels for the same query if it appears in multiple contexts. The front end can decide how to display them.
When the user selects the suggestion, the system passes a refined query plus a category filter. The search results are automatically limited to items in that category. No separate user step is needed. This speeds up the path to relevant items.
How do you test and validate your approach?
A/B testing is standard. Split traffic between the new query suggestions approach and an older baseline. Compare metrics like search success rate, add-to-cart events, or final conversions. A lift in those numbers signals that suggestions are helping users find what they need faster. Also watch for user feedback about speed, accuracy, and satisfaction.
Offline analysis is another layer. Engineers can examine logs to see how frequently suggested queries lead to good outcomes. If the system frequently suggests queries that result in zero relevant items or poor click-through, they can tweak scoring parameters or the minimum threshold. Occasional log reviews identify offensive terms that slipped through so they can be added to the blacklist.
What if user interests shift drastically?
Sudden shifts can come from seasonal trends, viral social media moments, or supply chain disruptions. Frequent incremental index updates handle mild changes. Extreme shifts might need an on-demand re-index. If a major holiday campaign starts, the team triggers an immediate re-index with updated data to push relevant queries to the top. If new categories appear, they must be integrated into the indexing pipeline so that query suggestions reflect them immediately. Relying on real-time or near real-time pipelines makes the system resilient when user searches suddenly spike for new terms.
What about system performance and scalability?
Sharding or partitioning the suggestions index is possible if it grows large. Each shard handles a subset of queries. A load balancer routes queries to the right shard. Horizontal scaling of the analytics pipeline ensures that large volumes of click and conversion events do not slow the indexing jobs. Caching mechanisms can also accelerate read operations on the autocomplete backend. The front end typically calls a specialized endpoint that returns suggestions quickly, often in just a few milliseconds, so the user sees results as they type.
Careful usage of logging and tracing tools ensures that if suggestion latency spikes, engineers can identify the bottleneck in real time. A metrics dashboard can show indexing queue times, compute usage, and memory consumption. Those metrics guide capacity planning for the next scaling step.
How do you deploy and monitor such a system in production?
Continuous deployment pipelines automate merges to production. They run unit tests and integration tests against the indexing logic. If any test fails, the pipeline rolls back the changes. Observability involves logs, metrics, and alerts. If suggestions return unusual data, or queries spike for unknown reasons, an alert notifies on-call engineers to investigate.
Feature flags let the team toggle new weighting parameters or index configurations without redeploying the entire stack. If alpha or beta needs fine-tuning, the team modifies them behind a feature flag. A small percentage of traffic sees the new parameters. If the metrics improve, the new settings can roll out for everyone. If not, engineers revert them. This approach avoids downtime or major disruptions to user experience.
End of case-study.