
ML Case-study Interview Question: Detecting Inaccurate Delivery Locations with Multimodal Machine Learning


Browse all the ML Case-Studies here.
Case-Study question
A q-commerce platform has frequent delivery issues due to inaccurate GPS coordinates entered by customers. They store textual addresses and automatically populate parts of these addresses using reverse geocodes. The problems arise when the location is offset by large distances from the true address. This causes delayed or failed deliveries and leads to revenue loss. The firm wants a system that identifies these location inaccuracies by learning patterns from past deliveries, including numeric signals (delivery partner calls, complaints, cancellations, etc.) and textual address data. How would you design and implement such a classifier to detect and flag an incorrect customer-captured location?
Detailed Solution
Overview of Approach
Train a multimodal machine learning model that uses:
Geographic location (in geohash form).
Textual address obtained from both the customer and an automated reverse geocode.
Numeric signals derived from delivery partner behavior (e.g., calls to support, tickets raised for traveling longer distances, cancellations, etc.).
Data Preparation
Construct two datasets:
Perturbation dataset by validating historically correct locations, then adding random Gaussian noise for positive (inaccurate) samples.
DBSCAN dataset by clustering historical delivery locations and treating the centroid of the largest cluster as the ground truth. Captured locations beyond a chosen distance threshold become positive (inaccurate) samples, while those within the threshold become negative samples.
Model Architecture
Use a RoBERTa-based text encoder to transform the address text and geohash input into an embedding. Obtain additional numeric features (fraction of orders with incorrect address calls, average call duration, fraction of orders with tickets for traveling longer distances, etc.). Combine these features with the text embedding in a Concat model or a Weighted model.
Three-Phase Training
Pre-train RoBERTa on Masked Language Modeling.
Fine-tune RoBERTa on the perturbation dataset (binary classification: accurate vs. inaccurate).
Incorporate numeric signals for a final fine-tuning pass on the DBSCAN dataset (only addresses with enough order history).
Inference
Use the final model’s prediction probability. Flag an address location as inaccurate if the probability is above 0.5. Downstream systems either prompt the customer for corrections or invoke a geocoder to fix the location.
Key Mathematical Formula for Binary Classification
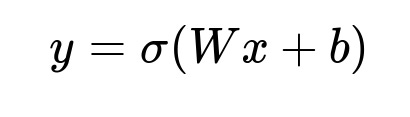
Where:
y is the predicted probability (inaccuracy vs. accuracy).
x represents the concatenated feature vector (text embedding + numeric signals).
W and b are trainable parameters.
sigma() is the logistic (sigmoid) function.
Python Code Snippet (Example)
import torch
from transformers import RobertaTokenizer, RobertaModel
import torch.nn as nn
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
roberta_model = RobertaModel.from_pretrained("roberta-base")
class MultimodalModel(nn.Module):
def __init__(self, hidden_size, numeric_feature_size):
super().__init__()
self.roberta = roberta_model
self.fc_text = nn.Linear(hidden_size, hidden_size)
self.fc_numeric = nn.Linear(numeric_feature_size, hidden_size)
self.fc_out = nn.Linear(hidden_size, 2)
self.activation = nn.ReLU()
def forward(self, input_ids, attention_mask, numeric_feats):
roberta_output = self.roberta(input_ids=input_ids, attention_mask=attention_mask)
cls_embedding = roberta_output.pooler_output
text_feats = self.fc_text(cls_embedding)
numeric_feats_transformed = self.fc_numeric(numeric_feats)
concat = torch.cat([text_feats, numeric_feats_transformed], dim=1)
combined = self.activation(concat)
logits = self.fc_out(combined)
return logits
Explain in interviews that the numeric features arrive from aggregated historical signals about addresses, and the text embedding comes from the final hidden representation of RoBERTa. Emphasize the importance of self-supervised training because it avoids expensive manual labeling.
Could Inaccurate Reverse Geocodes Interfere With the Training?
Yes. Reverse geocodes often mismatch if the captured location is off. The model must learn robust address representations that account for partial or incorrect reverse geocode text. Many addresses have unstructured text with possible spelling and language issues. Fine-tuning on real historical data with numeric signals helps the model detect such discrepancies despite errors in the reverse geocode.
Why Not Rely Solely on Delivery Partner Signals?
Delivery partner signals (like incorrect address flags or calls to support) might be sparse or incomplete. Some addresses with wrong coordinates may still see successful deliveries because the delivery partner knows the place. It is critical to combine location/address text with numeric signals to catch cases with weak partner data. The text model alone may fail if the reverse geocode text is also erroneous, but the numeric signals might help. Conversely, numeric signals might be missing or too subtle, but the text can reveal an obvious mismatch.
How Would You Handle Addresses With Low Historical Orders?
Addresses with low orders have fewer numeric signals. Rely more on textual features and geohash. Consider data augmentation by producing synthetic “perturbed” samples for addresses lacking many deliveries. The self-supervised approach with the perturbation dataset and the DBSCAN dataset ensures coverage across both low and high-density addresses.
How Would You Evaluate Generalization to New Localities or Cities?
Partition the training and testing sets based on different cities or localities. Check area under curve, precision, recall, and false positive rate across these partitions. Pay special attention to distances used as thresholds for labeling in the DBSCAN dataset. A mismatch in typical building spacing across regions may require region-specific distance thresholds.
Testing on fresh localities ensures the model does not overfit to the distribution of known neighborhoods and can handle new or less structured address patterns.
Could This Model Scale to Millions of Addresses in Production?
Yes. Pre-filter obviously accurate addresses by comparing the captured location with the median of successful delivery locations. This quick check prevents unnecessary inference for many orders. The deep classifier is then run on only suspicious addresses, making the overall system scalable. Use distributed serving infrastructure or batch inferences to handle large volumes of requests.
Would You Ever Manually Label Training Data?
Manual labeling can be expensive but beneficial for error analysis or rare corner cases. Most training data here is self-supervised. Manually label a small set to evaluate or refine distance thresholds for DBSCAN or to identify missing features. In practice, a small labeled set can provide additional checks for model drift and performance monitoring over time.