
ML Case-study Interview Question: Continuous ML Session Analysis for Real-Time Banking Fraud Detection


Browse all the ML Case-Studies here.
Case-Study question
A large financial institution wants to protect each step of a user’s online banking journey against fraudulent activities. They want to analyze biometric information (like keystrokes, mouse or touch events), device details (like OS version or battery status), and network data (like IP origin) for every session a user initiates. They need to detect unusual behaviors early (like a sudden remote takeover) and block high-risk sessions in real time. Class imbalance is severe, with massive volumes of legitimate sessions but very few fraudulent ones. Describe your end-to-end approach to build and deploy a scalable machine learning system that continuously evaluates fraud risk at each step of a session. Assume you must handle thousands of requests per second per customer, keep false positives low, and deliver results with minimal latency. Outline your design, detail your modeling strategy, and propose how to integrate alerts into a final risk scoring workflow.
Detailed Solution Explanation
Continuous fraud detection requires coordinated data handling and scoring at scale. Multiple data types converge, including user behaviors and device/network details. The system must fuse them efficiently while operating within tight latency bounds. Below is a high-level breakdown.
Data Collection
The system listens to user events from web or mobile sessions:
Keystrokes, mouse moves, and clicks on desktops.
Touches and swipes on mobile devices.
Device info such as operating system version, browser type, battery level.
Network metadata such as IP, approximate location, ISP, network type.
These signals accumulate continuously, so the system collects them in near-real-time.
Data Processing
The system transforms raw inputs into coherent features:
Behavioral features: typing rhythm, velocity, unusual activity patterns.
Device features: OS or browser anomalies, malicious software indicators.
Network features: suspicious IP blocks, proxy usage.
Session-level summary: time spent on pages, suspicious attempt sequences.
Advanced sampling (like oversampling of fraudulent cases or synthetic minority data methods) tackles class imbalance during training.
Core Model Logic
The model ingests features across multiple events within a session. A simple approach is a classifier (e.g., logistic regression, gradient boosting, or neural network). Training aims to discriminate legitimate vs. fraudulent sessions.
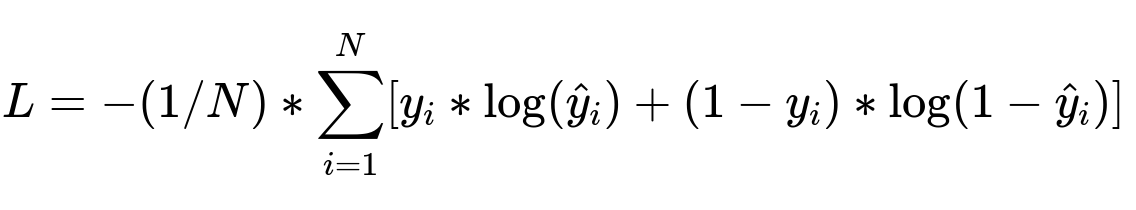
Here:
N is the number of training examples.
y_i is the true label (1 for fraud, 0 otherwise).
hat{y}_i is the predicted probability of fraud for the i-th example.
L is the cross-entropy loss function that penalizes misclassification.
This formula, or an equivalent objective, drives the model’s training to maximize separation between legitimate and fraudulent sessions.
Continuous Scoring Logic
The solution runs inference every time a relevant event arrives:
Start scoring at session initiation (login or registration).
Update scores whenever the user performs critical actions (transfers or changes to security details).
Emit an alert if risk surpasses a threshold, feeding into a final risk strategy.
Infrastructure and Deployment
Containers orchestrated by Kubernetes handle high throughput:
Horizontal scaling spawns more model-serving pods as load grows.
Inference servers use fast endpoints to deliver sub-second responses.
Logging/monitoring with open-source tools like Prometheus for metrics and Grafana for visualization.
A centralized event collector stores inference requests and outputs to facilitate re-training.
Risk Strategy Integration
The model’s output merges with domain-specific rules or business logic. For instance:
The system flags Potential Fraud Risk if the ML probability crosses a threshold.
Analysts combine it with additional checks (e.g., device recognized or not).
Adjust thresholds for each geographic region or use case, if needed.
Example Python Snippet
import numpy as np
from sklearn.linear_model import LogisticRegression
# Features: [behavior_score, device_score, network_score, ...]
X_train = np.load("features_train.npy")
y_train = np.load("labels_train.npy")
model = LogisticRegression(class_weight='balanced', max_iter=1000)
model.fit(X_train, y_train)
# Inference example (per session event)
def predict_fraud(session_features):
prob = model.predict_proba([session_features])[0,1]
return prob
Explanations:
class_weight='balanced' addresses class imbalance.
Model updates are possible by re-fitting on fresh data logs.
Follow-up Question 1
How would you address potential privacy and resource usage concerns when collecting continuous user behavioral data?
Answer and Explanation
User trust demands minimal intrusiveness. Collect only essential events and aggregate at a higher level if possible. Avoid storing raw biometrics; instead, store derived features (like average keystroke time). Keep data streams lightweight, possibly compressing events. Conserve device resources by throttling event capturing rates or enabling dynamic sampling if usage spikes. Govern everything with rigorous privacy policies and compliance measures (GDPR or relevant frameworks). Apply clear user consent flows to ensure legality.
Follow-up Question 2
What strategies would you use to handle class imbalance during training beyond simple class weighting?
Answer and Explanation
Combine multiple approaches:
Oversampling: Upsample fraud cases with naive replication or synthetic methods like SMOTE.
Undersampling: Reduce the volume of legitimate samples to balance proportions, though carefully to avoid losing key patterns.
Focal Loss: Adjust the loss function to focus more on difficult examples.
Cost-Sensitive Learning: Assign higher misclassification costs to fraudulent classes. This modifies objective functions to handle rare events more aggressively. Each method must be evaluated to confirm minimal overfitting and no key data is lost.
Follow-up Question 3
How would you ensure that early session scoring doesn’t produce excessive false positives when only partial user data is available?
Answer and Explanation
Use incremental scoring:
Score with partial data, but keep thresholds moderate. Early suspicious behavior triggers a lower-severity alert or a “monitor closely” state.
Re-score when more events arrive. Update the session’s final risk if new data reveals stronger or weaker evidence.
Provide context-sensitive thresholds: early in a session, require stronger signals to mark high risk. Later, with more data, refine the risk assessment. This tiered approach balances caution and accuracy.
Follow-up Question 4
What steps would you take to ensure the system’s explanations are understandable to non-technical analysts while using a complex model?
Answer and Explanation
Attach interpretable reasons to each score. For instance, show top features contributing to the risk:
“IP location mismatch from previous login”
“Unusually high mouse speed”
“New device with known malicious patterns”
Use surrogate models or feature-importance metrics to communicate insights in straightforward terms. Maintain logs that detail the main signals influencing a high fraud probability. Minimize black-box outcomes by summarizing key data points. This clarity helps analysts decide appropriate actions and fosters trust in the model output.