
ML Case-study Interview Question: Real-Time Multilingual Text Moderation Using Transformer Models


Case-Study question
You are working at a large-scale social networking platform that connects millions of users worldwide. You have been tasked with designing and deploying a real-time text moderation system to detect and flag harmful or abusive messages. Your system must support up to 50 languages and cannot rely on prior language detection steps. How would you build this solution from data collection through final deployment, ensuring high accuracy for multiple linguistic and cultural nuances?
Detailed Solution
Transformers-based architectures are well suited for a multilingual classification task. These architectures use attention mechanisms to learn contextual relationships across languages. One popular approach is to start with a large foundation model that has been pre-trained on massive multilingual datasets. Then fine-tune it on an in-house labeled dataset covering various abuse classes.
Model Architecture and Multilingual Approach
A Transformer takes an entire sequence at once, computing pairwise importance between tokens via self-attention. This lets the model learn nuanced connections in text without requiring separate language detection steps.
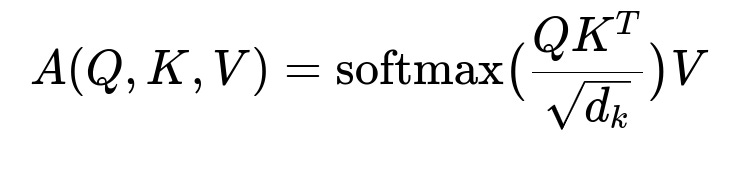
Where Q, K, and V represent the query, key, and value matrices derived from the token embeddings. d_k is the dimensionality of the key vectors. The softmax function ensures attention weights sum to 1 along each row. The model aggregates relevant features from each position in the sequence.
You can initialize the model with a state-of-the-art multilingual backbone that already knows representations for tokens in many languages. Then you add a classification head. This classification head produces logits for each class label (for example, Sexual, Insults, and Identity Hate).
During training, the system uses a standard multi-class classification loss. For a model predicting probabilities p_{n,c} for sample n in class c, you can compute the cross-entropy loss by comparing with the ground-truth y_{n,c}.
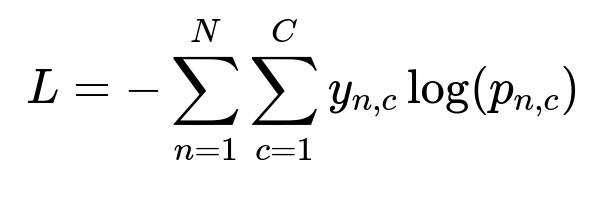
Where y_{n,c} is 1 if sample n belongs to class c, otherwise 0. p_{n,c} is the predicted probability for class c.
Data Collection and Labeling
Text samples should cover all target languages. Create a large curated dataset of real user messages with a balanced mix of clean text and abusive content. Multiple human annotators can label each sample to ensure high quality. If annotators disagree on certain texts, re-check them or mark them for special review.
Incremental Model Updates
Start with a few high-priority languages. Train the model, deploy, and monitor. Gradually include more languages. Watch key metrics like precision, recall, and F1 score. This step-by-step approach helps you refine hyperparameters, address corner cases, and manage label imbalance.
Production-Ready Infrastructure
Tokenization runs as part of the model graph. If you are using a custom tokenization layer, integrate it with the inference pipeline to avoid mismatch with training.
Run inference on GPU nodes using dynamic batching. Expand or shrink nodes based on real-time traffic.
Log predictions to a central monitoring system. Track error rates and user feedback for anomalies.
Support rollback for newly deployed model versions if you see unexpected drops in performance.
Robust Validation
Replay a representative slice of real traffic offline with the new model. Because toxic content is rare, build specialized test sets with more negative examples to assess performance. Compare the new model against older versions, checking confusion matrices and classification metrics in each language.
Possible Follow-Up Questions and Answers
How do you handle highly imbalanced labels?
You collect additional abusive examples to better represent the minority classes. You can oversample those examples or apply weighting in your loss function. Oversampling means repeating rare examples or using synthetic data. Class weighting modifies the loss to give more importance to underrepresented classes. The right choice depends on your dataset size and diversity. For text data, real curated samples of abusive text are typically more effective than synthetically generated ones.
What are the key hyperparameters to tune for this multilingual Transformer?
Focus on:
Learning rate: Too high destabilizes training, too low slows convergence.
Batch size: Larger can stabilize gradients but demands more GPU memory.
Decay rate (or schedule): Too fast can lead to underfitting, too slow can cause overfitting.
Max sequence length: If too short, you lose context. If too long, training can slow down and memory usage can increase.
Each new language can change the optimal values. You can do a grid or Bayesian search while monitoring validation metrics.
How would you ensure fairness and reduce biases in the model’s decisions?
You need balanced coverage of all languages and demographic groups. Check the model's false positive and false negative rates across subpopulations. If certain languages or dialects show worse performance, gather more data for those segments. Systematically investigate misclassifications to detect possible biases. If the training data has skewed patterns, you address it with improved data collection and label consistency.
What real-time considerations are important for GPU inference?
Throughput: The system must handle high volumes of messages per second. Dynamic batching groups requests to increase GPU utilization.
Latency: Keep the end-to-end inference below a certain threshold so that users get real-time feedback.
Scalability: Spin up or down GPU workers in response to traffic.
Monitoring: Use centralized logs and dashboards to spot latency spikes or GPU overload in real time.
How do you iterate if the model fails to generalize to new abusive patterns?
Continuously monitor user complaints and flagged content. Retrain the model with newly labeled examples or refine the labeling guidelines. Introduce new categories for novel forms of toxicity if required. Keep the system agile. Frequent incremental updates and a robust feedback loop let you adapt to evolving abusive behaviors.
How would you assess performance in production?
Use a live shadow evaluation approach. Log predictions on unseen real user messages (with minimal risk to user experience). Compare the model’s decisions with ground-truth labels obtained later via human moderation. Track metrics like precision, recall, and F1. High mismatch indicates drift or coverage gaps. Roll back if performance degrades severely.
That concludes the case study solution and the detailed follow-up Q&A.