
ML Case-study Interview Question: RAG-Powered Automation for Recurring SQL Queries and On-Demand Summaries.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a data solution to handle a high volume of recurring analytical queries within a large organization. Many stakeholders request the same types of SQL queries with small parameter changes. You must propose a system that uses Retrieval-Augmented Generation (RAG) and a Large Language Model (LLM) to automate these tasks, generate on-demand summaries in a messaging platform, and assist with fraud investigations. How would you architect and implement this solution?
Include how you would:
Straight away handle the integration between the LLM and your data repositories. Ensure relevant data retrieval for accurate LLM outputs. Allow team members to incorporate their own specialized queries or scripts. Automate regular report generation, scheduling, and notifications in a central messaging platform. Manage cost-effectiveness and scalability when deciding between RAG and fine-tuning.
Detailed solution
RAG combines a model’s generative capabilities with a knowledge base or database containing relevant up-to-date data. The solution architecture involves multiple components working together to retrieve data, feed it into the LLM, generate a result, and then deliver insights in a messaging interface.
Data integration
Store reusable SQL queries or Python scripts in a central repository that exposes them as APIs. Each API runs a specific query or function and returns formatted data. This repository allows any domain expert to upload or modify their queries. The system orchestrates which query to call based on the user’s prompt, applying RAG to match the request with the correct API.
LLM orchestration
Use an in-house or third-party LLM orchestrator that tracks prompts, retrieves context from the APIs, and sends the final prompt to the LLM. The LLM receives the data as context, creates a concise summary, and returns it to the messaging interface. The orchestrator manages which query or script to invoke.
Scheduling and automation
Implement a scheduler that triggers queries and summary generation at fixed intervals. The LLM uses the fetched data to produce daily or weekly summaries. The system posts these summaries into a messaging channel. This automation frees Data Analysts from repetitive reporting, letting them focus on complex analysis.
Fraud investigations
Configure a dedicated LLM-based assistant that uses stored queries specialized for fraud detection. When an analyst requests an investigation, the system identifies the relevant queries, retrieves the data, and compiles a comprehensive result. The LLM consolidates this data, highlights suspicious behavior, and posts the findings in real time.
RAG vs fine-tuning
RAG avoids retraining the model for new information. It retrieves only the needed data from a dynamic knowledge base. Fine-tuning can be more expensive and requires frequent updates to remain current. RAG scales easily because new queries or context do not demand retraining. This makes it cost-effective in large organizations handling diverse or constantly updating information.
Example Python approach
Use a lightweight web framework like Flask or FastAPI to expose SQL queries as APIs:
import os
from fastapi import FastAPI
import sqlalchemy
app = FastAPI()
engine = sqlalchemy.create_engine(os.getenv("DB_CONNECTION_STRING"))
@app.get("/api/fraud_query/{user_id}")
def fraud_query(user_id: int):
with engine.connect() as conn:
result = conn.execute(
"""
SELECT user_id, transaction_id, amount, timestamp
FROM transactions
WHERE user_id = :uid
ORDER BY timestamp DESC
LIMIT 50
""",
{"uid": user_id}
)
rows = [dict(row) for row in result]
return rows
The LLM orchestrator uses an internal logic that, upon receiving a “Fraud check for user 12345,” calls /api/fraud_query/12345, parses the JSON response, and includes that data in the final LLM prompt. The LLM then summarizes the findings and returns them to the user.
Core retrieval formula
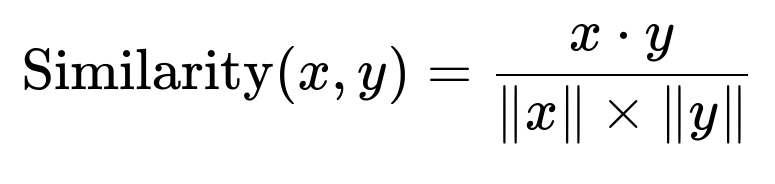
x is the embedding vector of the user’s query. y is the embedding vector of a candidate document or query. The system calculates this similarity to locate the most relevant stored queries or data chunks.
Why choose RAG over fine-tuning?
RAG pulls the latest data from repositories, saving time and compute resources. Fine-tuning requires training the model on new data whenever changes occur, which is inefficient for fast-changing fraud patterns or frequently updated datasets. RAG also simplifies adding new features or queries, as the base model remains unchanged while the knowledge base expands.
Follow-up question 1: How do you ensure data security when exposing multiple APIs?
Access control is managed by an authentication layer. Each request to an API is verified with tokens or credentials. The system uses role-based access so users can only call authorized queries. Sensitive endpoints employ strict permission checks. The organization’s secrets are stored in a secure environment variable manager to avoid embedding credentials directly in code.
Follow-up question 2: What happens if the LLM returns inaccurate or hallucinated answers?
A guardrail system checks if the data returned by the LLM aligns with known facts. When the orchestrator receives the LLM’s output, it validates the references to see if the final summary aligns with the retrieved data. If anomalies are detected, the system flags the response for manual review or triggers a fallback to a more conservative generation method. Logging user feedback helps retrain the orchestration pipeline if patterns of inaccuracies appear.
Follow-up question 3: How would you handle massive scale or higher latency?
Partition the database or scale horizontally using distributed data stores. Implement a caching layer for frequently accessed query results. For huge datasets, adopt an efficient vector store that can retrieve embeddings rapidly. Parallelize the orchestrator by running multiple instances behind a load balancer. Messaging queues can manage asynchronous requests, ensuring the system stays responsive under heavy load.
Follow-up question 4: How do you approach iterative improvements once the system is in production?
Monitor system logs for error rates, response times, and user feedback. Implement versioning for each query or script, so you can upgrade or roll back with minimal downtime. Experiment with advanced retrieval strategies (like advanced embedding libraries or specialized indexes). Track usage metrics to see which queries the LLM calls most often, then optimize those paths for speed and reliability.
Follow-up question 5: Could you extend the system to handle more than text data?
Add image or multimodal processing capabilities. For example, store references to relevant images in the same knowledge base as the text data. The LLM orchestrator can retrieve image metadata or actual image content via specialized APIs. If the LLM supports multimodal input, pass the image embeddings along with text embeddings. The system can then return combined insights from textual and visual content.