
ML Case-study Interview Question: Precise Automated Bug Routing Using XGBoost Text Classification.


Browse all the ML Case-Studies here.
Case-Study question
A large software product with a massive user base receives hundreds of daily bug reports through a centralized bug tracking system. Many development teams handle different parts of the product. Manually assigning each bug to the correct product sub-area is slow. The engineering leadership wants an automated triage system using a supervised text classification model to route new bugs quickly. Describe how you would design, train, deploy, and maintain such a system to achieve high precision in bug-to-sub-area assignment, given multi-year historical data with thousands of potential sub-areas.
Detailed solution
Training starts with a curated dataset of bug reports from the last two years. Clean each bug’s data by rolling it back to the moment of its creation. Remove fields that only become available after triage. Restrict the label space to sub-areas that have enough samples, such as the top categories that each have at least 1 percent of the largest category’s bug count. Process textual features from bug titles, first comments, and any relevant metadata flags.
Train a gradient boosting classifier to predict sub-area. The model ingests text tokens from bug fields and transforms them into numeric representations. Use a confidence threshold (for instance 0.60) to decide when to perform an automated assignment. Anything below that threshold remains unassigned for manual triage. This balances speed against false positives.
Use a modern gradient boosting library. One effective approach is XGBoost. The objective function combines loss plus regularization terms to reduce overfitting.
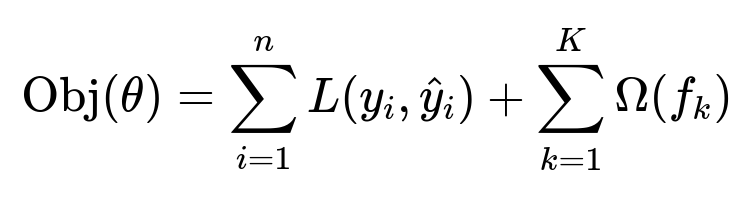
In this formula, n is the number of training samples. L(y_i, hat{y}_i) is the loss between true label y_i and predicted label hat{y}_i. K is the number of boosted trees. Omega(f_k) is the regularization for the k-th tree. Training time is roughly 40 minutes on a machine with 6 cores and 32 GB of RAM for ~100k bug reports. Prediction is extremely fast.
Deploy the model in production as a service. When a new bug is filed, extract the same features as in training (title text, initial comment text, flags). Pass them to the XGBoost model. If the top sub-area score exceeds 0.60, assign that sub-area. Otherwise, leave it for manual triage.
Monitor performance by sampling newly filed bugs and verifying assignments. Keep track of precision and recall metrics. Retrain monthly or quarterly to adapt to shifting bug patterns.
Use Python for data processing:
import xgboost as xgb
import pandas as pd
import numpy as np
# Suppose df has columns: 'title', 'comment', 'label'
# Preprocess text and split into train and validation
X_train, X_val, y_train, y_val = my_train_val_split(df)
dtrain = xgb.DMatrix(X_train, label=y_train)
dval = xgb.DMatrix(X_val, label=y_val)
params = {
"objective": "multi:softprob",
"num_class": num_labels,
"max_depth": 6,
"eta": 0.1,
"subsample": 0.8
}
evallist = [(dtrain, "train"), (dval, "eval")]
model = xgb.train(params, dtrain, 1000, evallist, early_stopping_rounds=20)
This code trains a multi-class classifier with a set of chosen hyperparameters. The training routine stops early if validation metrics stop improving, preventing overfitting. The final model is then used for predictions on new bugs.
Maintaining the system means evaluating any drift in incoming bug patterns, checking if new sub-areas should be added to the model, and refining the confidence threshold if the false-positive rate changes.
Follow-up question 1: How to handle sub-areas with fewer examples?
Use a threshold on the minimum bug count per sub-area to keep training stable. Sub-areas below that threshold merge into an “Other” category. If enough bugs later accumulate in that category, subdivide it and retrain. This avoids having too many classes with insufficient training data.
Follow-up question 2: How to handle new sub-areas that emerge after deployment?
Mark them manually until a sufficient number of examples is collected. Retrain or fine-tune the model with these newly labeled instances once they reach the threshold. This ensures the model’s label space remains relevant.
Follow-up question 3: Why apply a confidence threshold instead of always assigning the top predicted sub-area?
Avoiding a forced assignment on uncertain predictions reduces misclassifications. When the model’s probability is below 0.60, the bug might be ambiguous or more complex. A human triager can handle it. This strategy protects precision and developer trust in the system.
Follow-up question 4: How to detect duplicate bugs?
Compare incoming bug reports with existing reports using text similarity on the title, first comment, or crash signature. A similarity score above a certain threshold suggests a potential duplicate. This can be integrated into the same system or a separate workflow. Verified duplicates feed back into training data and improve future recommendations.
Follow-up question 5: How to incorporate missing “steps to reproduce” alerts?
Implement a classifier that checks if the first comment or bug text contains standard “steps to reproduce” patterns. If the model detects incomplete steps, send an automated comment asking the reporter to clarify. This keeps bug quality high before developers investigate.
Follow-up question 6: How to maintain model quality as data grows?
Periodically retrain on new bug data. Monitor metrics such as accuracy, precision, recall, confusion matrices, and sub-area distribution. If performance drops below a threshold, investigate data shifts, tune hyperparameters, or refine text preprocessing.
Follow-up question 7: How to optimize training time without sacrificing predictive accuracy?
Experiment with parallelization, sampling, or distributed training. Reduce maximum tree depth or tune learning rate to speed convergence. Prune very low-frequency tokens. Use sparse feature representations. Adjust your early-stopping strategy to avoid unnecessary rounds of training.