
ML Case-study Interview Question: Boosting User Retention with an AI Pipeline for Real-Time Personalized Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A major online platform struggled with low user retention caused by irrelevant recommendations. They wanted an AI-driven pipeline that identifies user behavior patterns and provides real-time personalized suggestions for products or content. The challenge: design a system capable of handling large volumes of user interactions, incorporate new data in near real-time, and measure engagement improvements accurately. How would you approach building and deploying this system?
Detailed Solution
A robust solution needs careful data handling, model selection, metric design, and deployment. The main steps involve data ingestion, feature engineering, model training, model evaluation, and an iterative feedback loop.
Data Ingestion and Exploration
Collect user interaction logs, transactional data, and user profile attributes from multiple sources. Aggregate them into a centralized data store. Check data schema consistency. Conduct exploratory analysis to identify patterns. Use distributed processing frameworks like Spark if data is large.
Feature Engineering
Engineer features such as user demographics, historical behavior, session frequency, product metadata, and contextual signals. Construct features from events that show user interest in items (views, clicks, watch-time). Evaluate transformation strategies to keep data consistent in real-time.
Model Selection
Pick an algorithm that can handle sparse data and changing behavior. Matrix factorization or deep-learning-based recommendation models are common. A neural network approach can capture complex interactions between users and items. For classification tasks, a logistic model or gradient boosting can be used. For ranking tasks, factorization machines can be effective.
Training Objective
Minimize the loss function. For a binary recommendation outcome, cross-entropy is standard. Below is the core formula in big h1 format:
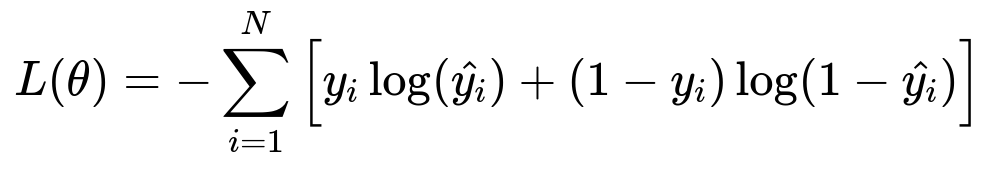
Where:
Nis the number of training examples.y_iis the actual label indicating if the user engaged with the item.hat{y_i}is the predicted probability of engagement from the model.thetarepresents the model parameters.
Model Evaluation
Split data into training and validation sets. Evaluate metrics such as AUC for binary classification or MRR for ranking tasks. Conduct offline experiments with historical data. Use a holdout period to mimic future user behavior. Analyze how well the model generalizes.
Serving and Deployment
Deploy a real-time inference pipeline that fetches the most relevant items for a user. Store model artifacts in a versioned repository. Roll out updates in a controlled manner using canary or shadow testing. Automate data pipelines with orchestrators like Airflow.
Iterative Feedback Loop
Integrate feedback signals from user sessions. Capture new data as users accept or ignore recommendations. Retrain or fine-tune the model at regular intervals or in streaming mode. Monitor online metrics such as click-through rate, watch-time, or conversion rate. Introduce A/B testing to measure lifts in engagement.
Example Code Snippet
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
# Load data
df = pd.read_csv('user_interactions.csv')
# Prepare features and target
X = df[['user_id', 'item_id', 'feature_1', 'feature_2']]
y = df['engaged']
# Split data
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Evaluate
preds = model.predict_proba(X_val)[:,1]
auc_val = roc_auc_score(y_val, preds)
print("Validation AUC:", auc_val)
This sample shows a simple classification approach. Production systems require advanced feature encoding, distributed training, and real-time scoring.
How would you handle data quality issues?
Answer
Identify missing or inconsistent data by profiling new events. Use imputation or default indicators for missing features. For extreme outliers, cap or clip feature values. Standardize categorical codes, unify time zones, and maintain robust data validation checks. Outdated or incorrect data can degrade model performance, so automate data consistency checks and data drift detection workflows.
How would you scale this pipeline for real-time recommendations?
Answer
Adopt streaming frameworks like Spark Streaming or Kafka Streams to gather events. Use a feature store for quick lookups. Train incrementally on fresh data. Use memory-optimized serving layers (Redis or approximate nearest neighbor indexing) for sub-millisecond recommendation retrieval. For each user request, combine recent interactions with precomputed embeddings to produce top relevant items.
How do you ensure the model remains up-to-date?
Answer
Schedule frequent retraining or partial fine-tuning on newly ingested data. Track performance metrics in production. If there is a noticeable drop, trigger a model refresh. Monitor distribution shifts in user demographics or content. Version-control your models. Keep fallback logic for extreme changes in user behavior or system outages.
How would you validate performance in production?
Answer
Use online metrics such as click-through rate, conversions, or dwell time. Split users into control and treatment groups with an A/B test. Compare performance to the existing recommendation engine or to a baseline. Watch for significant differences in key metrics. If improvements are validated, gradually expand the new model to the full user base.
How do you handle model interpretability?
Answer
Generate local explanations with frameworks like LIME or SHAP for critical decisions. Log interpretation outputs for each request if domain regulations require transparency. Provide aggregated feature importance insights to the business team. If certain factors are ethically or legally sensitive, systematically remove those signals and retrain.
How would you approach hyperparameter tuning?
Answer
Adopt Bayesian optimization or grid search for systematic tuning. Evaluate on validation sets or via cross-validation. Examine learning rate, regularization coefficients, hidden layers, or embedding dimensions. Set up parallel experiments. Track results in an experiment management system like MLflow or Weights & Biases.
How do you manage data privacy?
Answer
Anonymize user IDs and sensitive attributes. Restrict direct access to raw personally identifiable information. Use encryption at rest and in transit. Apply role-based access controls. If regulations like GDPR apply, provide data deletion workflows. Minimize data retention. If necessary, use federated techniques to train on-device and only share model updates.
This approach addresses the entire lifecycle: data gathering, modeling, evaluation, deployment, and iterative improvement. It scales for large user bases and time-sensitive recommendations.