
ML Case-study Interview Question: Transformer IOB Tagging for Accurate Date Detection and Reformatting in File Names


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing an automated file renaming system for a major cloud platform. Files are uploaded to folders, and these folders have rules to ensure that uploaded files follow a consistent naming convention. One of these rules is to detect and reformat dates in file names. However, file names can have inconsistent or ambiguous date formats. Your goal is to build a robust machine learning system to accurately identify dates (year, month, day) in the file names and then reformat them. Suggest a strategy to solve this, covering data annotation, model selection, optimization, and deployment considerations.
Detailed Solution
Overview of the Approach
You must identify the date components in file names. This requires a supervised learning pipeline. File names can have standard or unusual date formats. Traditional rules break easily under ambiguous formats. A transformer-based model can learn contextual patterns that simple regex or rule-based solutions might miss.
Data Annotation
Human annotators label file names. Each date component (year, month, day) in a file name is marked. An open-source annotation tool can store these labels. This ensures clarity about where each date component appears. Because unusual date formats are common, you can also generate synthetic data for coverage.
Tokenization
Split the file name into subword tokens. A subword tokenizer (for example, SentencePiece) strikes a balance between character-level and word-level details. This approach handles digits for dates while retaining enough context for textual portions of the file name.
Multi-class Classification
You predict Inside-Outside-Beginning (IOB) tags for each token. Each token is assigned a label: B-year, I-year, B-month, I-month, B-day, I-day, or O for non-date tokens. A transformer-based classifier (for example, DistilRoberta) is used and fine-tuned on your labeled data.
Core Formula for Multi-Class Classification
Below is a common cross-entropy loss function for multi-class classification:
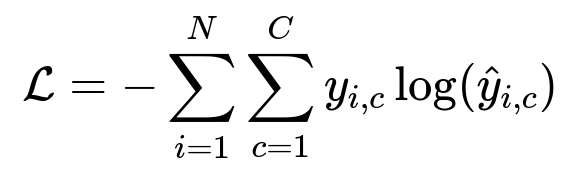
N is the number of training examples.
C is the number of classes (IOB tags in this scenario).
y_{i,c} is 1 if the true class of example i is c, otherwise 0.
hat{y}_{i,c} is the predicted probability for class c on example i.
Model Optimization
Transformer models can be large, causing high inference latency. You can prune layers or reduce precision (quantization) to accelerate inference. For instance, removing the last couple of layers can significantly boost speed while preserving accuracy. Switching parameters from float32 to float16 can also reduce memory load.
Deployment
A user-facing feature that renames files in real time demands short latency. Scaling to millions of files requires model serving optimizations such as caching, concurrent processing, or asynchronous handling. Store the model in a lightweight format, and load it once for many predictions.
Encouraging User Adoption
Some users may ignore the feature if it demands manual configuration. You can automatically generate recommended naming rules by scanning existing files in the folder. This reduces friction and fosters quicker adoption.
Follow-up Question 1
How would you handle partial or ambiguous dates, like “2023-06” or “June_2023,” where the day field is missing?
Answer and Explanation Partial dates occur if the file only has a year and month or any other incomplete date pattern. One approach is to extend the label set to include B-year-month or B-month-year and treat them as valid partial segments. You can also preserve an O label for missing day components. During model inference, the system can check which tokens get predicted. If the day is not identified, the model simply returns the two recognized components. Implementation details can include labeling partial dates in the training data or generating synthetic samples (e.g., “reports_Jun_2023.pdf”) to ensure the model learns to detect partial patterns. If your post-processing code expects a day, it can insert a placeholder like “01” if the user’s business rules allow it, or leave the date as partial if not.
Follow-up Question 2
Why is subword tokenization helpful here? Could word-level or character-level tokenization work?
Answer and Explanation Subword tokenization balances out-of-vocabulary (OOV) handling and context capture. File names might have textual sections plus numeric date sections. Word-level tokenization might produce large vocabulary sizes and many OOV issues for unique words in file names. Character-level tokenization can over-segment the file names, losing higher-level patterns, and it may degrade performance. By using subwords, digits and common textual patterns get split properly, retaining enough granularity for both date parts and meaningful textual context.
Follow-up Question 3
If you prune layers, how do you ensure the model still generalizes to unseen date formats?
Answer and Explanation Before pruning, the model is fine-tuned on carefully annotated data. During pruning, you remove layers that contribute minimally to the final prediction while monitoring validation performance. You only accept the pruned model if it maintains accuracy on a diverse validation set containing many date formats. It is crucial to test across a wide variety of real or synthetic file names. If performance drops on any major category of date formats, revert and prune fewer parameters. This iterative approach preserves generalizability.
Follow-up Question 4
How would you ensure your system remains efficient if traffic scales up by an order of magnitude?
Answer and Explanation You can containerize the pruned model with a fast inference server (like TorchServe or TensorFlow Serving). Then place autoscaling policies to handle load spikes. This is combined with caching repeated predictions (like repeated file names or repeated date patterns). Use asynchronous queues so that if the service is briefly overloaded, requests queue without blocking the entire system. This architecture ensures quick scaling without rewriting the entire codebase.
Follow-up Question 5
How would you maintain model performance over time if user behavior changes?
Answer and Explanation Continuously log anonymized file names that fail the date-detection step or produce unexpected results. Periodically retrain on new data that reflects recent user naming patterns. Maintain an annotation pipeline (possibly with partial human oversight) for newly introduced or rare date formats. This approach ensures the model stays relevant as naming practices evolve.
Follow-up Question 6
What are potential security or privacy concerns?
Answer and Explanation File names can contain personal data. Even though you only focus on date detection, the system sees the entire file name. Strict access control, encryption, and anonymization are important. If the platform logs file names for retraining, the pipeline must remove sensitive identifiers or store them with careful access policies. Compliance with privacy regulations (such as GDPR) is vital. No personal data or unique identifiers should remain without user consent or regulatory compliance.
Follow-up Question 7
How would you handle real-time failures in date detection?
Answer and Explanation You can implement a fallback mechanism. If the ML model returns low confidence or times out, revert to a simpler rule-based approach for date detection. This ensures continuity for the user. The system can also alert a monitoring service that logs the failure and flags the file name for further analysis.
This approach maintains a robust user experience. Even if the model fails on a rare file name, the user still gets some level of date detection or no rename at all instead of indefinite latency.
Follow-up Question 8
Why might large language models be considered for future improvements?
Answer and Explanation Large language models have broader understanding of textual context, including subtle patterns. They might detect more complex entities (e.g., names, locations) or handle extremely inconsistent date formats. They can also be fine-tuned on tasks like date extraction, which goes beyond standard year-month-day detection. However, these models can be large, so you would still need optimization and pruning for feasible deployment. The advantage lies in their ability to adapt faster to new or unusual file naming conventions.