
ML Case-study Interview Question: ML-Driven Push Notification Scheduling via Integer Programming Optimization.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale consumer platform sends push notifications from multiple teams (marketing, regional operations, product, etc.). These notifications promote new offers, discounts, or features, and are delivered to millions of users daily. They are often sent at overlapping times, sometimes with conflicting messaging, and without personalized scheduling. The platform wants to improve user engagement and reduce opt-outs by choosing the best times and frequencies to send each push. The platform also aims to factor in constraints (promotion expiration, daily push limits, etc.) while maximizing expected conversion. Design a system that stores incoming push notifications, scores each (push, time) combination using a machine learning model, and then applies an optimization approach to determine which pushes to send and at what times. Explain how you would structure this system, which model you would use to predict a push’s value for a given user and timeslot, and how you would handle relevant constraints. Propose a reliable end-to-end design that can process billions of notifications a month while continuously refining its decisions based on live data.
Solution
Problem Overview and Reasoning
Push notifications arrive from several sources. Each notification has metadata such as expiration time, valid delivery windows, promotional codes, and links. Storing notifications in an inbox allows easy retrieval. A scheduling component must pick the most valuable timeslots to send these notifications, while respecting constraints like maximum daily pushes or spacing between notifications. An optimization engine scores each feasible (push, time) pair and then selects a subset to maximize the sum of scores. The scoring function is learned by a machine learning model that predicts the user’s probability of performing a desired action (such as an order) within 24 hours.
Core Optimization Formulation
The system formulates the scheduling problem as an integer linear program. Let x_{i,t} be a binary variable that is 1 if notification i is sent at time t and 0 otherwise. Let s_{i,t} be the predicted score for sending notification i at time t. The objective is:
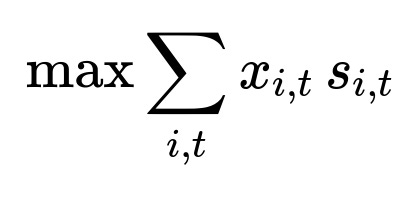
Subject to constraints:
Each notification can be sent at most once. For all i, sum over t of x_{i,t} <= 1
At any timeslot t, at most one notification is sent (if that is part of the design) or at most F notifications over the full time horizon if F is a frequency cap.
Expiration constraints: x_{i,t} = 0 if t >= expiration_i.
Send-window constraints: x_{i,t} = 0 if t not in window_i.
Other business requirements: daily push limits, spacing constraints, or resource constraints.
Scoring with Machine Learning
A gradient-boosted decision tree model is often used. It learns to predict conversion probability from historical data. Training data might consist of past notifications, user engagement outcomes, user features, push content, and temporal features. A typical label is whether a user completed the desired action within 24 hours. Because of heavy class imbalance, negative class downsampling is common.
An example snippet for training with XGBoost in Python could be:
import xgboost as xgb
# features: "hour_of_day", "day_of_week", "push_category", "user_engagement_score", etc.
# X_train, y_train are assumed to be prepared
train_data = xgb.DMatrix(X_train, label=y_train)
params = {
"objective": "binary:logistic",
"eval_metric": "auc",
"max_depth": 6,
"eta": 0.1
}
bst = xgb.train(params, train_data, num_boost_round=100)
The resulting model outputs a probability p for a given user, push, and timeslot. That probability becomes the score s_{i,t}, or a scaled version of it if needed. Higher predicted probability implies higher expected value.
Scheduler and Delivery Pipeline
A schedule generator retrieves all unsent pushes for a user from a data store and solves the integer linear program to determine the best (push, time) assignments. Each assignment is passed to a workflow engine that triggers the notification at the chosen timeslot. This engine can queue assignments in a distributed manner, handling large throughput. The final delivery step checks last-minute conditions such as resource availability or changes in user context before sending. If conditions fail, the push is suppressed or marked expired.
Implementation Details
A document store keyed by user IDs efficiently groups notifications by user. Sharding supports high parallelism. The scheduling process runs every time a new push arrives or on a fixed schedule. The ML scoring service predicts the conversion probability for each (push, time). These predictions feed into the integer linear program solver, which quickly identifies the best schedule under constraints. A messaging component dispatches notifications at the correct times. If updates happen (new pushes, user unsubscribes, or promotions expire early), the scheduler can re-run and reschedule.
Potential Challenges
Training data might be sparse or unbalanced. Negative downsampling and careful feature selection mitigate this. Modeling non-linear relationships between time and user engagement often boosts performance. Meeting real-time or near-real-time latency requirements for scheduling can be tough, so the scheduling might be triggered in batches. Handling concurrency at scale requires robust orchestration. If a push is scheduled for a time that has changed user context (like a store closed early), the system may need last-moment checks to avoid sending invalid promotions.
Next Steps
Expanding to multiple channels (email, SMS, etc.) only requires adding new scoring models and constraints for each channel. Multi-objective optimization (promoting membership, or different services) is achievable with advanced scoring or separate terms in the objective. Incorporating more granular, real-time features (recent user actions) could further improve conversion predictions. Switching to deep learning or real-time updated models can capture more sophisticated patterns.
What are the main follow-up questions a FANG interviewer might ask?
1) Why use an integer linear program instead of a greedy or heuristic approach?
A pure greedy method might pick the next highest-scoring push without considering future constraints. If a push is about to expire soon, ignoring it early can reduce overall value. An integer linear program accounts for conflicts, time windows, and capacity caps simultaneously. This approach yields a globally optimal schedule under the constraints.
2) How do you handle heavy traffic when scheduling pushes for millions of users?
A distributed architecture partitions the inbox storage by user ID. The schedule generator only processes pushes for one user at a time, which is parallelizable across many users. A queue-based system triggers the generator for each new push. Kafka topics segregate scheduled timeslots. Workers consume these topics at the correct times, delivering notifications as events. Horizontal scaling is straightforward by adding more consumers.
3) How do you tackle the cold-start problem for users with no history?
A fallback or baseline model is used when user data is limited. The system can cluster users by region, device type, or other similarities and use aggregated statistics for that cluster. In time, once enough data accrues for a user, the model uses individualized features.
4) How do you determine which features to include in the model, and why prune them?
Time-based signals (hour, day of week) and user-level engagement metrics (recent orders, push open history) are critical. Push category or content type are straightforward predictors of user interest. Pruning removes weak or redundant features to simplify training and reduce overfitting. Analyzing feature importance metrics from tree-based models highlights which features are truly valuable.
5) How do you incorporate real-time user behavior changes in your model?
A near-real-time feature pipeline updates user engagement signals if a user opens, clicks, or unsubscribes from pushes. Retraining the model frequently or using online learning can help the system adapt faster. The scheduling logic could also be re-triggered if a user shows unexpected behaviors that invalidate prior assumptions.
6) How do you extend this approach to multi-objective optimization?
In multi-objective scenarios, each push might have different goals: user conversions, brand awareness, membership signups, etc. One approach is to combine these objectives into a single weighted score s_{i,t}, with weights aligned to business priorities. Another approach uses advanced multi-objective optimization, but that adds complexity. Balancing trade-offs then becomes a strategic decision among stakeholders.
7) How do you measure success and evaluate this system online?
An A/B test can compare the system-generated schedule to a baseline (simple rules or random assignment). Metrics might include user conversion rate, overall revenue, churn/opt-out rate, and user satisfaction. A well-calibrated model should yield higher conversion at lower churn. Proper experiment design isolates the effect of the scheduling algorithm from other factors.
8) How can deep learning improve the current setup?
Deep learning can capture more complex relationships among time, user context, and push content. Sequences of user actions or recurrent patterns in daily behavior might be better modeled with recurrent or transformer architectures. Embeddings for push content or user profiles could help generalize faster for new notifications or new user behaviors.
9) How do you ensure constraints (like promotion expiration or frequency caps) are always respected?
The integer linear program sets x_{i,t} = 0 outside a valid window or after expiration. A daily frequency cap is implemented as sum_{i,t in day} x_{i,t} <= daily_cap. The solver never selects invalid assignments if constraints are set correctly. The scheduling system also re-checks constraints before final send to handle last-minute changes.
10) How can you reduce model inference time when scoring many notifications?
A batching strategy sends multiple (push, time) queries at once to the scoring service. Vectorized operations and GPU support in libraries like XGBoost or deep learning frameworks speed up inference. Precomputing certain features, such as day-of-week or user profile stats, also cuts latency. An efficient caching layer might store repeated features if many similar notifications are scored together.