
ML Case-study Interview Question: Scaling Real-Time Voice Moderation with Transformers and Machine Labeling


Browse all the ML Case-Studies here.
Case-Study question
A large-scale social platform wants to moderate real-time voice communications across millions of daily active users. They have limited human-labeled audio data, but they must detect policy violations such as profanity, bullying, and other unsafe speech behaviors in near real time. They want to process multilingual voice streams with minimal latency. How would you design a solution that automatically identifies these violations, reduces moderation load, and adapts to new violation categories over time?
Detailed solution
Data Scarcity and Labeling
They lack enough high-quality human-labeled data for training. They combine small amounts of human-labeled data for evaluation with large-scale machine-labeled data for training. They split audio into short segments, use an Automatic Speech Recognition system to transcribe text, then apply an internal text filter to label violations. They collect thousands of hours of audio in weeks instead of years by relying on this machine-labeling pipeline. Human-labeled data remains critical for final evaluation.
Machine Labeling Pipeline
They build a production pipeline that runs continuously. It: splits raw audio based on silence (audio chunk splitting), transcribes each chunk with an open-source Automatic Speech Recognition model, classifies the resulting text using an ensemble text filter for policy-violating content.
This pipeline labels training data at scale. They only use it for generating labeled examples. The final model must run without full transcription (to save time and compute), so they train a specialized model that directly classifies audio for policy violations.
Model Architecture
They select a Transformer-based approach because it handles sequential data effectively. They need near real-time performance and the ability to handle multiple languages. They choose a 15-second window as a trade-off between enough context and minimal latency. The model outputs multiple labels for each audio segment (multilabel classification) to capture different violation types.
They adopt Binary Cross Entropy as the loss function:
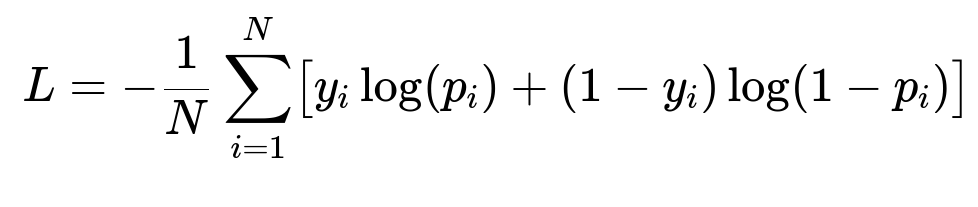
Here:
N is the total number of samples.
y_i is the true label (1 if violation, 0 otherwise).
p_i is the model’s predicted probability of a violation.
They train multiple versions, including:
A fine-tuned WavLM model.
An end-to-end Transformer trained from scratch on thousands of hours of machine-labeled audio.
A distilled version that uses a Whisper encoder as a teacher network and a smaller WavLM-based student for improved inference speed.
They incorporate optimizations: selective quantization of Transformer layers, Mel-frequency cepstral coefficients for feature extraction, and Voice Activity Detection to skip silent or noisy segments.
Production Considerations
They deploy a high-throughput cluster with thousands of central processing units to label tens of thousands of audio hours in parallel. They add queue-based infrastructure for each step (chunk splitting, transcription, filtering) to eliminate bottlenecks. For real-time use, they run the final model at scale with 2,000+ requests per second, filtering only audio with speech detected by Voice Activity Detection.
Outcomes
They measure success with precision-recall metrics on a human-labeled validation set. They see a precision-recall area under curve of 0.95 for detecting unsafe speech. They observe a double-digit percentage drop in severe voice abuse reports after rolling out automated warnings. They then extend training to multiple languages, covering different accents and potential code-switching in user conversations.
Follow-up question 1
Why use a machine-labeling pipeline if you already have a text filter and a transcription model?
Answer and Explanation They need an audio-based model that avoids full transcription in production due to high compute costs. The text filter plus transcription is too slow for every voice stream at scale. Machine labeling only generates training data. The final audio-based model classifies raw waveforms directly, reducing latency and resource demands. It is compact enough to deploy near real time, while still achieving high accuracy thanks to the massive machine-labeled dataset.
Follow-up question 2
How do you handle low-prevalence violation categories like self-harm or references to drugs?
Answer and Explanation They group these categories into a single “other” class initially because there is insufficient data to train separate labels. They continue monitoring usage. As more examples appear, they split the “other” category into more precise classes. This incremental approach ensures the model still flags rare violations, even if it cannot categorize them individually from the start. They improve coverage by gradually adding labeled examples over time.
Follow-up question 3
How do you evaluate the model given the mismatch between high-violation test sets and real-world low-violation data?
Answer and Explanation They use multiple datasets. One dataset is a high-prevalence set, often from abuse reports, to confirm the model catches violations accurately. Another set reflects overall platform usage, where prevalence is low. They tune thresholds for each scenario. For general traffic, they pick lower sensitivity to reduce false positives. For abuse-report traffic, they increase sensitivity because the baseline violation probability is higher. They track metrics like precision, recall, false positive rate, and user impact.
Follow-up question 4
How do you reduce false positives and improve trust in the system?
Answer and Explanation They lower thresholds in low-violation contexts. They add a teacher-student distillation step to preserve classification quality with a smaller student model. They use Voice Activity Detection to discard silence and background noise. They continually refine training data by including mislabeled samples from real traffic. They set up human-in-the-loop moderation workflows to intercept uncertain cases. They share user notifications that identify the flagged phrase, improving transparency.
Follow-up question 5
How do you handle multilingual support and language mixing?
Answer and Explanation They gather multilingual data with machine labeling and unify it in a single training set. They train with combined audio from various languages to build a single model that accommodates code-switching. They incorporate domain adaptation by adding more data from underrepresented languages. They do teacher-student distillation in each language pair to preserve performance. They re-check user reports and continuously refine the training set for improved multilingual robustness.