
ML Case-study Interview Question: Machine Learning for Fraud Detection in Ride-Sharing Marketplaces.


Case-Study question
You are tasked with designing and deploying a fraud detection system at a large travel marketplace that connects people looking for rides with drivers. Fraudsters have been creating fake listings and scamming genuine users, often leveraging tactics like phishing or social engineering. The company already uses simple rule-based methods to detect suspicious activities, but these heuristics are easy to bypass and generate too many false positives. The existing Trust & Safety team manually reviews suspicious accounts, yet scammers keep adapting. You need to propose a robust, scalable Machine Learning system to reduce fraud while keeping good users protected.
Propose your solution. Include the following: Explain how you would define and track the right metrics to measure fraud. Describe how you would transition from simple rule-based detection to a Machine Learning solution. Explain how you would handle data labeling, model training, monitoring, and iteration. Clarify how you would measure and maintain the model’s performance over time. Detail any possible risks, trade-offs, or required organizational alignments to ensure success.
Detailed Solution
Understanding the business goal
The goal is to safeguard genuine users from losing money or sensitive information to scammers. The company wants a measurable reduction in reported fraud cases. The key is picking a metric that aligns with this goal and is easy to monitor. Reported scam cases per thousand active members is a strong baseline metric that directly measures impact on real users.
Defining metrics
A single metric often fails to give timely operational insights. It is wise to use proxy metrics. One proxy metric might be the daily percentage of suspicious driver profiles. Another might be the daily percentage of attempted bookings on suspicious rides. Manual labeling of daily user samples is critical for calculating these metrics accurately.
Laying the foundation before Machine Learning
A rapid first step is a rule-based or heuristic system. This approach provides initial fraud detection and helps gather labeled examples. Human analysts or Trust & Safety teams can review flagged accounts. This process yields real data on which to build a machine learning model.
Moving from heuristics to Machine Learning
Heuristics break easily once scammers notice patterns. Machine learning helps adapt to changing scam tactics. By frequently retraining the model, new trends get captured. The system can learn more subtle behaviors, such as suspicious messaging patterns or unnatural booking frequency. This allows for more nuanced detection and fewer false positives.
Important classification formulas
A central evaluation concept is Precision. This metric answers: "Out of all flagged cases, how many are actually fraud?"

TP means true positives (fraudsters correctly flagged). FP means false positives (legitimate users incorrectly flagged). High precision reduces inconvenience to genuine users.
Another important concept is Recall. This metric answers: "Out of all fraudsters, how many were caught?"
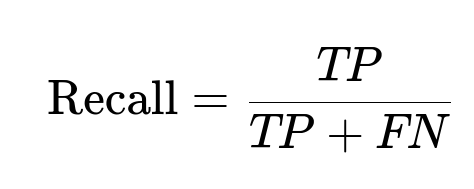
FN means fraudsters who were missed. High recall catches more scammers.
A balanced fraud detection system aims for good precision and recall. Depending on the company’s tolerance for false positives, the system might shift its threshold to optimize for fewer missed scammers or fewer frustrated legitimate users.
Building a data pipeline
Collect data on user profiles, trip details, booking patterns, complaint rates, and historical fraud flags. Include metadata on user activity (time intervals, IP patterns, etc.). Ensure you have a continuous labeling system, where flagged profiles get verified by the Trust & Safety team. Store these labels for model training.
Example code snippet (training a basic classifier)
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score
# Load data (example columns)
df = pd.read_csv("fraud_data.csv")
# X might have features like activity_count, profile_age, message_count
X = df[["activity_count", "profile_age", "message_count"]]
y = df["is_fraud"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
precision = precision_score(y_test, preds)
recall = recall_score(y_test, preds)
print("Precision:", precision)
print("Recall:", recall)
This example fits a Random Forest model on labeled data. Evaluate precision and recall to see how well it detects fraud. Adjust or retrain frequently to catch evolving scam patterns.
Human oversight
Human review helps the model learn from borderline cases. If a new scam pattern appears, analysts label them promptly. This labeled data feeds the next retraining cycle, keeping the system adaptive. Frequent labeling sessions reduce model drift. If oversight decreases, the model quickly becomes outdated.
Monitoring performance
Set up dashboards to watch:
Daily fraud rate (number_of_scam_reports / number_of_active_users).
Model-based metrics (precision, recall).
Distribution shifts (if user activity patterns change drastically, it may hint at new scam tactics).
Addressing organizational requirements
Machine learning for fraud is an ongoing investment. Multiple teams (Data Science, Trust & Safety, Engineering) must coordinate. Management needs to support labeling and model deployment. Everyone must trust the metrics and dashboards.
Trade-offs
A strict model threshold may flag too many users, hurting user experience. A loose threshold may miss too many scammers. The optimal balance depends on company priorities and user tolerance for friction. Using an adaptive threshold can help maintain an acceptable false-positive rate.
Possible Follow-Up Questions
How do you handle unbalanced data?
Fraud cases are often a small fraction of the total user base. Standard accuracy measures can be misleading. Focus on precision, recall, and f1-score to get a realistic picture of the model’s effectiveness. Consider oversampling suspicious cases or undersampling normal cases. Synthetic data generation methods like SMOTE can be used, but real data labeling from manual reviews is still crucial.
Reasoning: Random oversampling or undersampling can help the model see more examples of fraud. SMOTE can synthetically create new fraud samples with plausible feature values. Real labeled data remains more valuable than synthetic, because the latter might not capture unpredictable scam behaviors.
How do you keep the model updated against new scam strategies?
Schedule frequent retraining. Maintain a pipeline for continuous ingestion of fresh labeled data. Automate feature engineering so new suspicious patterns get captured. Watch for model drift, indicated by a sudden drop in performance or strange feature distributions. Retrain or fine-tune as soon as drift is spotted.
Reasoning: Scammers adapt. If you wait too long, the model’s recall falls. Frequent or on-demand retraining ensures the model sees new behaviors. Proper versioning of models and data helps track changes and revert if something goes wrong.
How do you explain the model’s decisions to stakeholders or regulatory bodies?
Provide explainability through techniques like feature importance rankings. Tools like SHAP (SHapley Additive exPlanations) show which features have the greatest impact on predictions. Keep a record of flagged cases, reasons, and final outcomes. Offer a feedback loop where stakeholders can see examples of false positives and false negatives.
Reasoning: Fraud detection can be sensitive, especially if legitimate users get flagged. Stakeholders and regulators need transparency. Feature contribution metrics show how the system arrived at its conclusion, ensuring accountability.
How do you mitigate false positives that frustrate genuine users?
Carefully tune the operating threshold. Use a system of tiered reviews where the model’s highest confidence fraud cases get immediate action, while lower confidence cases go into a manual review queue. Update your rules or model once you confirm misclassifications. Offer clear customer support channels for users who are wrongly flagged.
Reasoning: Too many false positives erode trust. Tiered review ensures only the most suspicious accounts are blocked instantly. The rest get human attention, which refines future model training.
How do you detect performance issues early, rather than waiting for fraud reports?
Build real-time dashboards that show daily distribution of predicted fraud vs. validated fraud. Chart changes in user sign-up or trip-booking patterns. Monitor sudden spikes in suspicious activity. Compare predictions against manual labels. Track time-lag between predicted fraud and user reports to measure reaction speed.
Reasoning: Sole reliance on user reports is slow. Automated alerts from dashboards reveal changes in scam volume or user behavior long before an onslaught of reports. Early detection allows timely interventions or re-training.
How do you justify the cost of building and maintaining a fraud ML system?
Show how each prevented scam translates to direct savings (chargebacks, refunds, lost user trust). Prove that automation cuts manual review costs. Present the synergy of machine learning with a smaller, more efficient Trust & Safety team. Highlight how advanced detection protects the brand and user loyalty.
Reasoning: Fraud impacts user retention, platform reputation, and operational budgets. A well-deployed ML system pays for itself if it reduces scam losses and manual effort. Demonstrating the return on investment secures ongoing support from leadership.
That concludes the case-study question, solution, and detailed follow-ups.