
ML Case-study Interview Question: Designing a Real-Time ML System for Scalable Product Search Ranking


Browse all the ML Case-Studies here.
Case-Study question
A large consumer-facing platform wants to refine its product discovery pipeline. They have millions of items, each with various attributes and user interaction signals. They observe users searching for specific products, clicking certain results, and occasionally making purchases. They want to build a Machine Learning system that uses this user feedback and item information to improve search relevance and ranking in real time. How would you design and implement a data-driven solution that addresses data ingestion, feature engineering, model training, deployment, and monitoring at scale?
Detailed Solution
Data Ingestion and Processing
Raw logs include search queries, clicked results, user profiles, timestamps, and item attributes. Data is huge, so a distributed framework like Apache Spark can handle large-scale transformations. Continuous data pipelines keep the model’s training data updated. Transform logs into training pairs (query, item, user actions).
Feature Engineering
Features include query text embeddings, item metadata, user behavioral patterns, and context (device, location). For text embeddings, represent search queries with pretrained language models. Numerical user signals like click-through rate or add-to-cart ratio capture historical engagement. Normalize or bucket continuous numeric features to keep them stable.
Model Architecture
Initial stage can be a two-step system: a candidate generator that narrows the item pool, followed by a ranking model that refines the top results. The ranking model can use gradient boosting (e.g., XGBoost) or deep neural networks. Train on user interactions: positive labels for clicks/purchases, negative labels for impressions without clicks.
Key Objective Function
Often use cross entropy as the loss for classification tasks. Log loss punishes wrong probabilities. The main formula is:
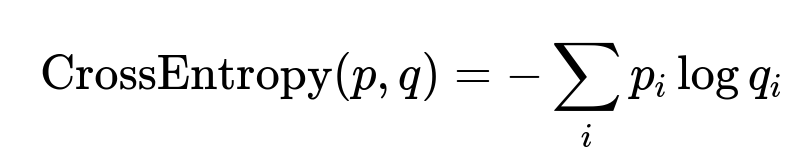
Here p_{i} is the true distribution (often a one-hot vector for a specific class), and q_{i} is the model’s predicted probability of that class.
Model Training
Offline training uses historical data and multiple negative samples for each positive example. Shuffle data well to prevent bias from chronological ordering. Validate with metrics such as Normalized Discounted Cumulative Gain or Mean Reciprocal Rank to measure relevance. Hyperparameter tuning uses a held-out set, or cross-validation, to avoid overfitting.
Deployment
Deploy the trained model behind a real-time service. Expose it via a low-latency application programming interface. Use a lightweight inference engine that can load the trained parameters. Replicate the service across multiple data centers for fault tolerance.
Monitoring
Track key metrics like click-through rate, search latency, user retention, or purchase rate. Alert the team if anomalies appear. Regularly retrain or fine-tune as data changes. Maintain a shadow deployment environment to test new models on live traffic in parallel before a full rollout.
Practical Example
Below is a simple snippet illustrating a training pipeline in Python with a gradient boosting library. Split the data, train the model, and then evaluate:
import xgboost as xgb
import pandas as pd
data = pd.read_csv("training_data.csv")
train_data = data.sample(frac=0.8, random_state=42)
val_data = data.drop(train_data.index)
train_labels = train_data["label"]
val_labels = val_data["label"]
train_features = train_data.drop(columns=["label"])
val_features = val_data.drop(columns=["label"])
dtrain = xgb.DMatrix(train_features, label=train_labels)
dval = xgb.DMatrix(val_features, label=val_labels)
params = {
"eta": 0.1,
"max_depth": 6,
"objective": "binary:logistic",
"eval_metric": "logloss"
}
evals = [(dtrain, "train"), (dval, "val")]
bst = xgb.train(params, dtrain, num_boost_round=100, evals=evals, early_stopping_rounds=10)
preds = bst.predict(dval)
# Evaluate predictions
This pipeline reads input, splits it, trains a gradient boosting model, and checks early stopping with a validation set.
How would you handle these follow-up questions?
1) How do you handle noisy data or labeling errors?
Noisy clicks or accidental taps occur. Confirm user intent by combining multiple signals (dwell time, subsequent actions). Filter short clicks that indicate accidental taps. Calibrate with purchase data if it exists. Large-scale logs still hold many quality labels, but weighting them based on user engagement helps reduce noise impact.
2) How do you ensure the system remains stable under data drift?
Continuously check distribution shifts. Automate daily or weekly retraining with rolling windows. Compare new data statistics (means, standard deviations) against historical values. If the distribution diverges, trigger faster retraining. Validate on fresh data, measure performance changes, and apply robust features that generalize better.
3) How do you address scalability challenges in real-time inference?
Precompute heavy feature transformations offline. Maintain an in-memory key-value store for quick retrieval. Optimize model structure, possibly distilling large models into smaller ones. Use specialized hardware (GPUs or Tensor Processing Units) if deep networks are used at scale. Implement caching for repeated queries to save computation.
4) How do you evaluate success beyond online metrics?
Consider user satisfaction measured by retention. Track how often users refine queries or abandon searches. Conduct A/B tests with different ranking models. If user experience improves, you see better engagement or revenue signals. Tie your final model choice to a balanced view of business key performance indicators and user outcomes.
5) How do you handle cold-start for newly added products?
Use metadata-based models with content features like text description or images. Use item similarity to bootstrap predictions. Combine popularity signals from items with similar features. Once the item accumulates more clicks or purchases, incorporate real interaction data into retraining or real-time updates.
6) How do you debug unexpected system behavior in production?
Log inputs, outputs, and user actions in detail. Compare predictions from offline training to real-time predictions. Identify mismatch in feature distributions between training and production. Adjust feature transformations if necessary. Maintain robust fallback logic to handle misconfigurations or large-scale outages. Trace user sessions to see if recommendations deviate from expectations.
7) How do you handle ranking among multiple objectives, such as clicks and revenue?
Combine them in a multi-objective function or train separate models. Weighted objective can reflect business priorities. For instance, you might assign a higher weight to items with higher profit margins. Validate that you do not degrade user experience. If you want a single composite score, define the trade-offs explicitly and measure final outcomes carefully.
8) How do you ensure interpretability for stakeholders?
Provide feature importance for tree-based models. Use model-agnostic methods like Local Interpretable Model-Agnostic Explanations for neural networks. For legal or product requirements, track the top contributing features for each prediction. Summarize these explanations in dashboards or automatic reports that highlight how the model arrived at a ranking decision.
9) What if users behave differently in various regions or device types?
Partition data by region or device category. Train specialized models if usage patterns diverge significantly. Incorporate region or device type as features in a single global model if differences are slight. Monitor separate key metrics per region or device to catch performance drops in smaller user segments.
10) How do you test deployment changes without risk?
Use canary releases. Route a small percentage of queries to the new model. Compare performance to the old system before a full rollout. Track metrics in real time. If the new version consistently outperforms or remains on par, proceed to increase coverage. If anomalies appear, revert quickly and investigate the root cause.