
ML Case-study Interview Question: Scalable Real-Time Travel Ranking with Streaming Pipelines and Feature Stores


Browse all the ML Case-Studies here.
Case-Study question
A large online platform serves millions of real-time ranking predictions daily for users searching for travel experiences. The system must handle diverse feature types, some updated in real time, and deliver personalized, low-latency results in under 80 ms. The data science team needs to maintain cost efficiency, manage seasonal traffic spikes, run daily retraining pipelines, conduct continuous A/B testing, and perform data drift detection. The goal is to keep the model fresh and accurate. How would you design and implement such a ranking pipeline, from data ingestion and feature engineering to model training, serving, A/B testing, cost efficiency, and ongoing model observability? Include a discussion on how you would handle real-time feature updates, daily retraining, detection of concept drift, and measurement of ranking performance with metrics such as NDCG. Provide a step-by-step plan.
Detailed Solution
System Overview
The platform ingesting user interactions at scale must employ an event streaming backbone for capturing realtime interactions. A feature store can maintain and serve precomputed features. A daily orchestration pipeline trains fresh models by joining historical events with point-in-time accurate features. A separate service or library handles inference in a container, exposing an API for ranking. A real-time store quickly serves the latest feature values under strict latency.
Feature Engineering
An event ingestion layer aggregates data such as impressions, clicks, and user bookings. Feature engineering transforms raw interaction streams to user- and item-level features. One real-time feature example is a position-discounted impression count with a short lookback window. A streaming application can consume each impression event, update counters in memory or a key-value store, and store them for quick retrieval. Offline features, such as historical item performance, can be computed in a data warehouse, then periodically updated in the feature store.
Real-Time Pipeline
A streaming application can subscribe to a message queue or event bus that publishes user interactions. An internal aggregator calculates partial counts or sums in near real time. For example, below is a simple Python snippet showing a streaming aggregator:
from collections import defaultdict
impressions_count = defaultdict(int)
def process_impression(user_id, activity_id, position):
discount_factor = 1.0 / (1 + position)
impressions_count[(user_id, activity_id)] += discount_factor
# The aggregator regularly writes aggregated values to a feature store.
The aggregator writes these impressions to a feature store, making them instantly available for inference. Load tests ensure the aggregator keeps up with peak traffic.
Model Training
A daily orchestration system (for example, using a DAG-based scheduler) merges historical ranking events with subsequent user behaviors (clicks, bookings). This labeled dataset is then joined with offline features and real-time features from the feature store. Point-in-time joins avoid data leakage. A training script fits the model, logs metrics, and pushes a versioned artifact to a model repository.
Serving and A/B Testing
A container with FastAPI or a similar framework loads the model. Real-time features, such as the discounted impressions, are fetched by providing the user ID and item ID to the feature store. The ranking service then computes a score for each item and returns the top results in under 80 ms. Scaling is handled by autoscaling mechanisms tied to request loads, preventing over-provisioning. The container can simultaneously host a control and a treatment model for A/B testing by routing a fraction of live traffic to each variant.
Observability
A model observability platform ingests inference logs and compares real-time distributions to training distributions. It creates drift alerts if input feature distributions deviate from a moving reference window. It also tracks the ranking metric. One popular choice is Normalized Discounted Cumulative Gain. The key formula can be shown below:
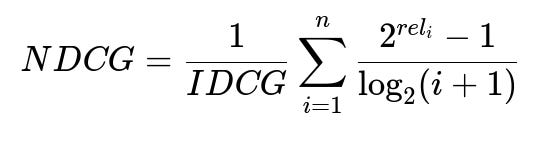
Here, rel_i is the relevance score of the item at position i. IDCG is the idealized ranking's DCG.
The system triggers alerts if the NDCG score drops below a threshold or if certain features drift significantly from expected ranges. The data science team investigates root causes and retrains or reverts the model if needed.
Cost Efficiency
Seasonal traffic patterns can be handled by scaling the streaming aggregator, feature store, and serving layer up or down automatically. Some systems let you set custom policies that correlate with real-time usage, so you pay only for the resources needed.
Q1: How would you manage schema changes or data format mismatches in the streaming pipeline?
When a new event version appears, the feature engineering step must check for differences in field names or data types. One approach is to maintain a versioned schema registry. If the aggregator sees mismatched data, it routes them to a staging area for further investigation. The aggregated data gets validated before entering the feature store. You can also implement a strict schema validation that discards or reshapes invalid messages.
Q2: What methods ensure that point-in-time joins are accurate?
Each event includes a timestamp, and each feature record in the store is also versioned with a valid range or an update timestamp. When building the training dataset, the system queries the store for the feature values that were valid at or immediately before the event timestamp. This prevents data leakage from future knowledge. Strict time-bound queries to the feature store ensure correctness.
Q3: How would you handle incremental updates to the model without retraining from scratch?
You can deploy an incremental learning pipeline or a warm-start approach. The daily pipeline could use the previous model as a starting point and only update weights based on new data. Another technique is online training, where small batches of new data refine the model on a frequent schedule. However, continuous training can introduce drift or degrade performance if not monitored carefully.
Q4: What is the reasoning behind using a short lookback window for real-time features?
User behavior patterns can shift quickly, so a short window captures the latest preferences without overly weighting older interactions. For example, a 7-day window can reflect current trends more accurately. If the window is too large, stale data may dominate. If it's too small, random fluctuations might override stable signals. Experimentation determines the ideal window length.
Q5: How do you debug poor performance in production when metrics show a drop?
Compare distributions of current features to the reference window in the observability tool. Check which feature drift triggered the alert. Examine if certain user or item segments have changed. Investigate data ingestion or aggregator issues. Verify that your A/B test variant is fetching the right feature set. If the model or pipeline is correct, you may decide to retrain more frequently or revert to a prior model.
Q6: How would you handle personalized re-ranking at scale for thousands of items?
One approach is to retrieve a candidate set of items, often using a more basic filter or retrieval model, then apply the ranking model on only those candidates. This two-stage approach saves computation. In real time, the top relevant items from the candidate set receive personalization via the trained ranking model using the user’s feature vectors.
Q7: How do you choose the best metric for a ranking system, and why might NDCG be a strong choice?
Choose a metric that aligns with user satisfaction. NDCG prioritizes correct ordering at higher ranks, which is valuable when the top search results matter the most. This metric also allows partial credit for lower-ranked correct items. Some environments may prefer precision-at-k or reciprocal rank. In practice, track multiple metrics to gain a holistic view.
Q8: How do you ensure reliability in the face of unexpected system failures?
Set up health checks on the aggregator and serving layers. Use automated failover or load balancers to switch to backup instances if a primary service fails. Persist real-time feature updates to a robust store that can replay missed events. Monitor end-to-end latencies and use an incident management system to escalate anomalies quickly. Continuous integration tests and chaos engineering can further improve system resilience.