
ML Case-study Interview Question: Automated Marketing Loop: XGBoost Ranking for Dynamic Streaming Platform Ads


Browse all the ML Case-Studies here.
Case-Study question
A global streaming platform wants to automate off-platform content marketing campaigns at scale. They run paid ads on social networks and display channels worldwide. They seek a system that automatically generates large numbers of ad creatives featuring dynamic content (e.g., artist imagery), ranks which content to feature in each region, deploys those ads, tracks performance metrics (clicks, installs, registrations, and cost per registration), learns daily from the data, and repeats the process. How would you design such a system end-to-end, including data pipelines, creative generation, and a machine learning model that ranks and selects the best content?
Detailed solution
They built an automated marketing loop with five main stages: ingest, rank, deploy, learn, repeat. Each stage passes data or assets to the next, forming a closed feedback system. They needed to ingest content metadata, build ads with that content, measure performance on different ad platforms, and retrain or update ranking decisions based on aggregated performance signals.
They automated ad creative generation by first using a basic templating service that combined metadata from a backend service into static images. This approach was quick but offered minimal design flexibility. They then adopted motion graphics using a scriptable system that relied on Adobe After Effects plus an open source tool, allowing them to render videos or animated assets on cloud instances. The creative generation service was wrapped in an asynchronous pipeline. Workers could scale up or down based on how many new ad assets needed rendering.
They used a content ranking system to select which content would appear in each ad. It was driven by data pipelines that fetched performance metrics from multiple platforms’ APIs. They combined that data with their large content catalog (e.g., artists’ popularity, local listening stats, etc.). They approached ranking in two steps:
Heuristic approach. They started by using popularity, share_of_registrations, and diversity of content. They used a similarity graph to extend an already-known set of performers to new, untested performers. This let them explore new ads while favoring proven content.
Machine learning approach. They then trained an XGBoost model to predict two metrics: reg_percentage (or sub_percentage) and relative cost ratio (CPR or CPS share) at a campaign level. They used features like campaign location, ad dimensions, operating system, template IDs, or artist metadata. The model output suggested which artists or templates were predicted to drive better sign-ups at lower cost. An A/B test against the heuristic approach showed a significant reduction in cost per registration and a higher click-through rate.
They productionized this pipeline so that each day it fetched the latest ad performance data, computed new rankings, generated new ad assets, and deployed them on platforms. They also handled external dependencies, such as marketing platform outages or data attribution changes. They designed fallbacks to preserve previous-day rankings if new data was unavailable.
They tackled challenges like scaling render farms, mitigating ad platform API failures, adapting to new attribution frameworks (IDFA changes), migrating to new MMP partners, and exploring methods to incorporate artist diversity in slate recommendation. They concluded that an incremental approach (heuristics first, ML next) plus robust pipelines made it easier to adapt to new constraints.
Below is the core formula often used to define share of registrations for an artist in a campaign:
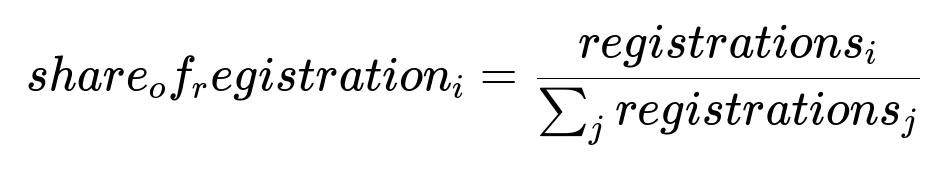
Here, registrations_i is the number of sign-ups attributed to artist i’s ads, and sum_j registrations_j is the total number of sign-ups from all artists tested in that campaign segment.
They implemented the ML training flows with Kubeflow, used XGBoost to learn from historical performance data, then generated daily predictions for how each artist or template might perform. That ranking fed back to the creative generator service, which output fresh ad creatives for each target region.
They tested the entire system with small experiments in selected markets and rolled it out globally once consistent improvements in cost efficiency were confirmed. This required collaboration between data engineers, ML engineers, designers, and marketing teams.
They also handled diversity by ensuring the system tested less-popular artists if predicted performance indicated upside potential, though it remained a challenging area. IDFA changes did not significantly degrade this model because it relied on aggregated data instead of user-level logs.
They maintained the system by monitoring daily pipelines, verifying performance metrics and cost fluctuations, and updating the ML model when new features or new data sources became available.
How do you handle scaling concerns when generating ad creatives?
The system moved from a synchronous Java-based templating approach to an asynchronous rendering pipeline for complex motion graphics. They ran background workers in the cloud that used a command-line tool to automate After Effects. They queued rendering jobs with references to each composition template. Workers pulled those jobs, rendered batches, stored outputs in the desired format, and reported completion. They scaled up or down the number of render workers based on the backlog of queued jobs. This asynchronous design avoided timeouts or blocking in a single service call.
Why use a separate preranking model when ad platforms have auto-optimization?
They generated thousands of possible ad creatives by combining many artists with various templates, languages, aspect ratios, or animations. Ad platforms optimize among a limited set of ads. With too many ads, those platforms’ built-in optimizers might yield poor coverage, never giving enough impressions to any single creative to learn. A preranking step trimmed the massive pool to a more manageable set. This ensured each creative received sufficient exposure and prevented high ad platform spend on low-performing or random picks.
How does the system handle outages in external APIs?
They preserved the previous day’s content rankings if a data pipeline could not refresh. When a social network’s API was down, they fell back to the last known set of recommended artists and templates. The pipeline resumed normal operation once the API was back. This strategy minimized disruption and avoided training a model on incomplete or missing data.
How did the team address data privacy changes such as IDFA?
They used aggregated daily performance data. They did not rely on user-level logs for training. Apple’s iOS changes primarily affect user-level attribution, but the model only needed total installs, registrations, or subscription counts to calculate reg_percentage or sub_percentage. As a result, IDFA changes did not break the model. They monitored performance metrics to confirm the model remained stable after the changes.
Why was XGBoost chosen for the machine learning model?
They wanted a robust gradient boosting algorithm that could handle mixed feature types (numeric, categorical, and textual), was scalable, and gave interpretable feature importances. XGBoost had strong library support, integrated cleanly with their Kubeflow environment, and trained efficiently on daily intervals. Its regularization mechanisms helped prevent overfitting in campaigns with changing external conditions.
How do you incorporate artist diversity?
They tried to encode diversity in the supervised model by adding features representing how similar or different artists were from each other, but it was not straightforward. They first used a heuristic that picked a set of diverse artists based on popularity, performance, and similarity. Over time, they attempted a slate recommendation approach, but it introduced extra complexity in model training. They discovered that simpler incremental approaches are easier to maintain in fast-changing production environments. They continue to explore more advanced multi-artist recommendation methods.
Could you show a small Python snippet for the daily ranking workflow?
Below is a simplified example:
import xgboost as xgb
def get_training_data(start_date, end_date):
# Pull historical performance data from warehouse
# Return a pandas DataFrame
pass
def train_daily_model(training_df):
# Prepare features X and targets y
X = training_df[["market", "os", "template_id", "artist_popularity"]]
y_reg_percentage = training_df["reg_percentage"]
model = xgb.XGBRegressor(objective="reg:squarederror", n_estimators=100)
model.fit(X, y_reg_percentage)
return model
def predict_and_rank(model, inference_data):
# inference_data: new day set of (market, os, template_id, artist_popularity)
# Return sorted predictions
preds = model.predict(inference_data)
ranked = inference_data.assign(score=preds).sort_values("score", ascending=False)
return ranked
training_data = get_training_data("2025-03-01", "2025-03-29")
model = train_daily_model(training_data)
new_artists = get_new_candidates()
ranked_artists = predict_and_rank(model, new_artists)
store_rankings(ranked_artists)
They used this approach to refresh rankings each day. They included more features in the real system (e.g., cost ratios, template variations, regional data).
How might you extend this system to ensure good coverage for emerging content?
They might add an exploration mechanism that periodically tests new artists or creative templates with a portion of the campaign budget, even if their predicted score is lower. This approach ensures they do not miss unexpected success stories. Bayesian methods or multi-armed bandit solutions could also help allocate impressions for exploration vs. exploitation. They might measure how fast a new creative ramps up performance and feed that signal back into the ML model to adapt quickly.
How would you respond if a marketing manager wants more frequent re-rankings?
They can shorten the training window from daily to hourly or multi-hour intervals, but that risks more noise in data. They should first analyze whether cost efficiency or user-acquisition dynamics shift drastically within a day. If yes, near-real-time retraining might be justified. Otherwise, daily intervals tend to be enough for stable learning, given typical ad platform data latency. Infrastructure scaling (e.g., spinning up more Kubernetes jobs for frequent retraining) is also necessary if re-rankings become more frequent.
How do you monitor model drift or changes in campaign performance?
They track cost per registration (CPR), click-through rates (CTR), and user sign-ups for each batch of ranked creatives. They compare these metrics against expected ranges from historical performance. If metrics degrade significantly, they investigate whether input data changed (e.g., a new major competitor in the same campaign, platform policy changes, or a shift in user behavior). They might retrain with new features or revert to a known stable version of the model until they fix the cause of drift.