
ML Case-study Interview Question: AI-Driven Re-ranking with User Affinity Profiles for Personalized Experiences


Case-Study question
You are a Senior Data Scientist at a large platform that handles diverse customer interactions across search, browse, and product recommendation experiences. Executives want a tailored, AI-driven personalization strategy that optimizes relevance and drives key performance metrics such as conversion rate, average order value, and user engagement. You have millions of daily active users with varying levels of interaction, and the leadership team needs a robust solution that can ingest event data from multiple sources, automatically generate user affinity profiles, and re-rank results in real time. They also require an easy way for business stakeholders to experiment with personalized experiences, measure performance, and refine personalization rules over time.
Explain how you would architect an end-to-end personalization platform to handle this scenario. Describe how you would set up data ingestion (e.g., user events, catalogs), create and maintain dynamic user profiles, and integrate these profiles into live queries for re-ranking. Propose how you would measure success. Outline how you would leverage human oversight (merchandisers, product managers) to ensure the system remains aligned with business goals.
Detailed Solution
Data ingestion and user profiling
Start by sending user actions such as views, clicks, and conversions to a tracking layer. In parallel, store catalog or content records (e.g., products, articles) and maintain the relevant metadata or attributes. Ingest the events and records into a processing layer that updates each user’s affinity profile. Assign weights to attributes that matter most, such as category, brand, or other product facets. Continuously update these affinities whenever new events are captured.
AI-driven re-ranking
At query time, adjust the ordering of results by combining a relevance score with each user’s affinity score. Compute a final score for each item to reflect both how well it matches the query and how strongly it aligns with the user’s preferences. One simple approach is to sum the base relevance and an affinity component multiplied by a tunable factor.
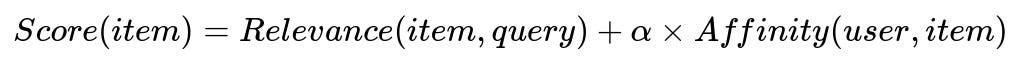
Where:
Relevance(item, query) is the core text matching or search relevance function.
Affinity(user, item) captures how closely the item matches the user’s behavioral profile.
alpha is a hyperparameter that determines the strength of personalization.
Increasing alpha puts more emphasis on personalization signals. Decreasing alpha relies more on generic search relevance.
Autocomplete and facet personalization
Autocomplete should retrieve the top results that align with user preferences as soon as they start typing. For facet personalization, reorder or highlight facets that reflect the user’s past engagement patterns. Show favored brands or categories first. Log user interactions for continuous fine-tuning.
Recommendations and inline segmentation
Generate recommendation carousels by matching items to user profiles. Insert dynamic banners or targeted offers (inline segmentation) to surface the most relevant promotions or calls-to-action. Track impressions and clicks to measure whether these personalized elements boost engagement.
Business rules and transparency
Provide a dashboard or interface for non-technical teams to set business rules. For example, they can specify constraints like “promote new arrivals for returning users” or “highlight brand X for high-value users.” Display to users when content is being personalized to maintain trust and allow easy configuration changes.
Measuring success
Monitor key performance metrics such as click-through rate, conversion rate, average order value, and repeat visits. Conduct A/B experiments where some cohorts receive personalized results and others do not. Evaluate the net lift on primary metrics. Periodically retrain or adjust personalization parameters based on these outcomes.
Example Python snippet
# Pseudocode for combining relevance and affinity scores
def compute_final_score(item, user_profile, alpha):
relevance_score = compute_relevance(item, user_profile.query)
affinity_score = user_profile.get_affinity(item)
return relevance_score + alpha * affinity_score
def rerank_items(items, user_profile, alpha=0.5):
scored_items = []
for item in items:
score = compute_final_score(item, user_profile, alpha)
scored_items.append((item, score))
scored_items.sort(key=lambda x: x[1], reverse=True)
return [item for (item, _) in scored_items]
This code iterates over items, computes a combined score, and re-sorts them. Each item’s final position depends on the user’s specific affinity signals and the search relevance.
Human oversight
Merchandisers and product managers update or override the personalization logic based on business goals. They can adjust alpha, tune attribute weights, or create special promotions for particular user segments.
AI-driven re-ranking in more depth
Train or configure an algorithm that computes a final score for each item by blending its baseline relevance (how well it matches the user’s query) with how strongly it aligns to the user’s preferences. The system often starts with a set of candidate results returned by a search engine or recommendation module, then re-orders them with AI-based logic.
At query time, each item is scored using a combination of textual/semantic relevance and personalized affinity signals derived from the user’s interaction history:
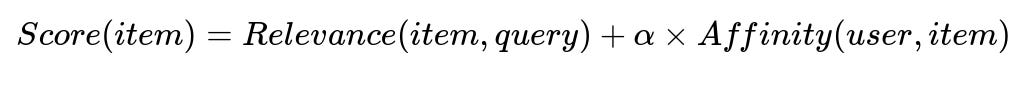
Where:
Relevance(item, query) measures how well the item text, keywords, or semantic features match the user’s query.
Affinity(user, item) measures alignment between the user’s profile and the item’s attributes. For example, if a user has frequently clicked on a particular brand or category, items containing that brand or category receive a higher affinity value.
alpha is a tunable weight that controls how aggressively personalization is applied. Higher alpha means the system ranks content more by user preference. Lower alpha weights it more toward baseline relevance.
Explain each step in detail:
1. Retrieve initial results. Search or recommendation services retrieve results using standard matching rules. This involves lexical search, vector search, or a hybrid approach. Gather enough candidate items (e.g., top 100).
2. Compute baseline relevance. Evaluate each candidate’s match to the query. If textual relevance is used, measure keyword frequency. If semantic search is used, compute a similarity metric based on embedded vectors. Store this relevance as a numeric score.
3. Lookup user affinity. Load the user’s personalized data from a profile store. That profile might have aggregated signals like brand preferences, category preferences, or historical engagement patterns. Map each item’s attributes (e.g., brand or category) to the user’s preference weight.
4. Combine the scores. Add the baseline relevance to the user affinity multiplied by alpha. This arithmetic ensures items that fit the user’s personal profile float up. For users without robust history, rely more on the baseline relevance or fallback defaults.
5. Sort. Sort all candidate items by the final score in descending order. The highest-scored items appear first.
6. Serve results. Return the re-ranked items to the user interface. Consider caching or storing these results if they will be accessed frequently.
7. Real-time updates. Update user affinity whenever new interactions (click, add-to-cart, purchase) occur. For performance and scalability, use asynchronous pipelines or streaming platforms so the next query reflects the user’s most recent preferences. If extremely low-latency updates are required, incrementally update the user profile in near real time.
8. Monitoring and tuning. Track click-through rate, add-to-cart rate, and overall engagement. Conduct experiments to see how changes in alpha or weighting of particular item attributes affect conversions and user satisfaction. Fine-tune the weighting strategies accordingly.
Advanced considerations Some systems train a more complex re-ranker model that captures intricate interactions among user attributes, item attributes, and contextual factors. For example, factorization machines or deep neural networks can model higher-order interactions. However, such models can be expensive to serve at scale. A hybrid approach is common: use a lightweight formula-based re-ranker in production, then feed logs into a more complex model offline to suggest improvements or new features for the re-ranking pipeline.
Follow-up question 1: How would you handle new users with little or no interaction data?
Answer: Cold-start users lack direct interaction data. Use several strategies: Rely on contextual attributes like geolocation or device type. Apply aggregate trends, such as popularity or trending items. If partial data is available (e.g., user arrived from an affiliate link), incorporate known preferences. Encourage profile-building signals. As the user begins interacting, incorporate real-time events to update their preference profile. Maintain fallback logic that reverts to generic relevance if not enough data exists.
Follow-up question 2: How would you ensure the system remains scalable with millions of requests per day?
Answer: Distribute the ingestion and query-processing load across multiple clusters. Use indexing strategies that support rapid writes for event updates. Keep user profiles in a high-throughput data store with fast read/write performance. Cache popular queries and maintain a streaming pipeline for real-time updates. Employ load-balancing across the serving layer. Monitor latency and throughput to detect bottlenecks. Scale horizontally by adding more computing resources or specialized nodes to handle peak traffic. The key is a well-designed microservices architecture that decouples data ingestion, user profile updates, and query-serving layers.
Follow-up question 3: How would you measure the impact of personalization versus baseline search?
Answer: Set up experimentation where a controlled group receives baseline relevance-based results. Compare their metrics to a treatment group that receives personalized results. Monitor differences in click-through rate, conversion rate, revenue, session length, or any other key performance metric. Use statistical significance testing to confirm whether the personalization uplift is meaningful. Repeat these tests regularly as the system evolves.
Follow-up question 4: How would you refine facet personalization if certain segments show reduced engagement?
Answer: Look for patterns in segment behavior. Identify which facets or categories users skip or select. Adjust the weighting for the underperforming facets. Optionally hide them for that segment if they provide no value. If an unexpected facet becomes popular in that segment, prioritize it. Re-run A/B tests to confirm that changes improve engagement. Ensure the updated logic doesn’t conflict with other segments by continuously monitoring feedback and usage metrics.
Follow-up question 5: How would you integrate third-party data sources or external platforms?
Answer: Use connectors or batch pipelines to import user events and catalog data from external platforms (e.g., a customer data platform or a streaming analytics service). Normalize the events into a consistent schema. Merge them with the user’s existing profile. When pushing updated user profiles or segment labels into third-party tools, expose an API or regularly export the enriched profiles. Confirm data quality by validating each data feed and verifying that attribute mapping remains consistent.
Follow-up question 6: How would you handle data governance and privacy regulations?
Answer: Respect data minimalism. Store only the attributes essential for personalization. Mask or anonymize user identifiers wherever possible. Provide user-facing settings to opt out or limit personalization. Comply with regulations like the General Data Protection Regulation by allowing data deletion or user consents. Implement role-based access controls to ensure only authorized personnel can view or modify user data. Log data access requests and encrypt data in transit and at rest.
Follow-up question 7: How would you keep the personalization model updated with evolving user behaviors and changing catalogs?
Answer: Schedule periodic reviews of attribute weights and alpha. Track shifting trends or seasonal patterns in user behavior. Retrain or refresh the personalization algorithms with the latest data. When new products or categories are introduced, ensure they are added to the indexing pipeline. Observe how users interact with them and update affinity scores accordingly. Maintain a feedback loop, so new items gain or lose prominence in response to real-time engagement signals.
Follow-up question 8: How would you handle potential bias or fairness concerns in personalized ranking?
Answer: Analyze attribute distributions to ensure diverse representation. If certain categories or brands consistently surface, confirm they align with user interest rather than inherent bias. Calibrate alpha so user interest does not overshadow content diversity. Provide a user setting for “generic view” to see non-personalized results. Conduct periodic audits of aggregated personalization outcomes. If bias emerges, adjust attribute weights or introduce fairness constraints. Monitor outcomes continually to confirm that any corrective measures remain effective.
Follow-up question 9: How would you adapt your approach for non-e-commerce platforms?
Answer: Focus on content relevance rather than product attributes. Track events such as article views, video plays, or forum interactions. Build user profiles around topics, authors, or media formats. Re-rank content items based on a blend of textual relevance and user affinities. Incorporate rules that highlight trending content or editorial picks. Evaluate success by measuring session length, content shares, or subscription sign-ups. The core principle remains the same: combine user behavior signals with base relevance to create personalized experiences.
Follow-up question 10: What key technical challenges might arise when deploying the entire solution?
Answer: Data quality is a frequent obstacle: inconsistent events or incomplete user profiles skew personalization. Latency and throughput requirements force engineering teams to scale carefully. Integration with legacy systems or diverse data sources complicates the pipeline. Periodic index updates and user profile refreshes must be done without noticeable delays or downtime. Lastly, interpretability can be difficult if personalization involves complex machine learning methods that yield opaque decisions. Planning for debugging, monitoring, and traceability is essential to manage these complexities.