
ML Case-study Interview Question: Building a Multi-Model AI Assistant for Online Work Marketplace Talent Matching


Browse all the ML Case-Studies here.
Case-Study question
A large online work marketplace wants to integrate customized AI models to connect employers and skilled professionals. They have decades of historical data from successful collaborations on their platform. They want to build and scale an AI assistant that streamlines job postings, proposal creation, and talent matching. How would you design a multi-model AI solution that leverages both external pretrained models and custom trained models using domain-specific data, ensuring high-quality outcomes, efficient resource usage, and responsible AI practices?
Detailed Solution
They have amassed a substantial dataset from successful projects on the platform. The data includes job postings, proposals, user-to-user conversations, and engagement patterns. The marketplace needs to leverage this historical data alongside synthetic and human-curated data to build specialized Large Language Models (LLMs) that serve distinct use cases. The strategy involves using external foundation models for speed and breadth, then layering custom models tuned on domain-specific signals.
Trained models can power tasks like generating effective job descriptions or suggesting improvements to proposals. The marketplace also wants specialized recommendation engines for matching the right professionals with the right projects. The multi-model approach balances general pretrained capabilities with narrow, use case-specific fine-tuning.
Data Collection and Quality
They access high-quality platform records from actual collaborations. This data covers diverse industry verticals and conversation types. They also generate synthetic data that mimics real interactions but at larger scale, plus human-written data by professional writers that produce gold-standard examples of how ideal user interactions should go. These curated datasets reduce hallucinations and enrich model comprehension of complex, job-related dialogues.
Custom vs. Pretrained Models
They integrate a pretrained foundation model for general tasks like summarizing text or drafting broad content. This is efficient because it requires minimal computational cost to get off the ground. Then they develop smaller custom models dedicated to tasks such as:
Proposal generation
Candidate selection
Work-specific recommendation
These models are trained on narrower datasets relevant to each task. This approach yields higher accuracy and deeper insight into the nuances of the work platform. Fine-tuning smaller models allows for better error analysis, debuggability, and performance optimization.
Training Objective
They adopt a standard language modeling approach for text generation tasks. The training objective usually involves maximizing the probability of the next token. A commonly used formula for language modeling is:
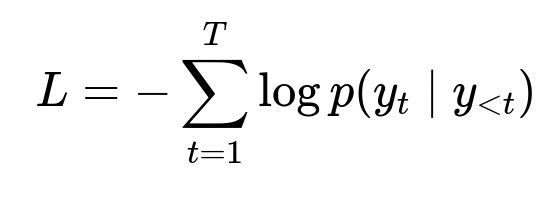
L is the loss. T is the sequence length in tokens. p(y_t | y_{<t}) is the predicted probability of the current token given the previous tokens. Minimizing this loss improves the model’s ability to predict the next word accurately, which leads to coherent text generation.
Implementation Considerations
They set up a pipeline that retrieves data from a secure repository, filters out low-quality samples, and segments the data by use case. Synthetic data generation scripts create large volumes of plausible conversations. Human writers produce curated dialogues for edge cases or advanced scenarios. Engineers then tokenize this text, feed it into model training routines, and store model checkpoints in a robust version-control system.
Code Example
Below is a Python snippet showing a simplified example of training a custom LLM using a popular deep learning framework. The snippet illustrates how the dataset is loaded, tokenized, then used for a training loop:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("open_source_foundation_model")
model = AutoModelForCausalLM.from_pretrained("open_source_foundation_model").to(device)
texts = [
"Conversation snippet 1: ...",
"Conversation snippet 2: ...",
# Many more examples, possibly synthetic
]
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
model.train()
for epoch in range(1, 6):
outputs = model(**inputs, labels=inputs["input_ids"])
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print("Epoch:", epoch, "Loss:", loss.item())
They store the fine-tuned weights in a model registry. When the model is deployed, an API gateway routes requests based on the use case. Users needing general tasks hit a large pretrained endpoint. Users needing specialized assistance (like proposal help) are routed to a dedicated smaller model.
Performance Tracking
They use automatic metrics such as perplexity or cross entropy to ensure the models generate coherent text. They also run manual evaluations on newly fine-tuned models with short test conversations, verifying correctness and clarity. Feedback loops are in place for continuous model improvement and risk mitigation.
Responsible AI
They only use data in compliance with user privacy settings. Engineers treat user data with caution, anonymizing sensitive fields. Synthetic data procedures are carefully tested for realism and diversity, so the models learn relevant patterns without overfitting to private or proprietary user information.
Potential Follow-Up Questions
How would you ensure high-quality synthetic data?
Review the generation algorithms and compare synthetic outputs with real user interactions. Examine grammar, style, and domain relevance. Use periodic manual spot checks to validate that synthetic texts align with actual project discussions. Adjust generation parameters to match the complexity level of real dialogues. Enforce diversity constraints, so the synthetic data set spans multiple industries and scenarios.
How do you handle hallucinations in the generated text?
Use smaller specialized models that are trained on curated domain-specific examples. Introduce an iterative process of prompt refinement, model output checks, and user feedback loops. Consider retrieval augmentation, where the model references an indexed knowledge base. The narrower domain coverage of each model reduces the chance of random or inaccurate outputs.
How would you measure success beyond standard metrics like perplexity?
Evaluate real-world user engagement with each custom model. Observe whether the model-generated job descriptions, proposals, and conversations lead to actual successful outcomes, like filled job postings or accepted proposals. Track user satisfaction, time to completion, and repeat usage. Combine this with structured A/B tests measuring user conversions and the final business impact.
What are the trade-offs of using a single large foundation model versus multiple custom-trained models?
A single large foundation model simplifies system architecture but might miss domain-specific nuances. Fine-tuning might still not achieve the depth of understanding needed for specialized tasks. Multiple smaller models increase complexity in deployment and maintenance but provide precise, relevant responses. Debugging is easier when each model focuses on a specific use case because error localization is more direct.
How do you manage continuous updates to maintain model relevance?
Retrain or fine-tune as new data becomes available. Set up a pipeline that regularly ingests fresh conversations and outcomes to keep the models current. Monitor drifting issues, where older training data no longer represents real user behavior. Include data versioning to enable rollback in case of unexpected performance drops.
How would you adapt the solution to multilingual contexts?
Expand the training datasets with multilingual corpora. Split or label data by language. Build separate smaller models for major languages if resources allow. Alternatively, fine-tune one large multilingual model, but test thoroughly for each language. Confirm that domain context is intact and that cultural nuances are captured.
How might you handle custom user requests with unusual requirements?
Route advanced or unusual queries to a fallback pipeline that combines the custom model with a larger, more general foundation model. Let the system detect that the query falls outside the specialized domain. The fallback route then uses the more general capabilities of the larger model. Add a sanity-check filter that ensures the final response still respects platform policies and user privacy.
How can you scale the infrastructure for millions of user interactions?
Use container orchestration tools like Kubernetes to spin up model-serving instances. Employ load balancing to distribute requests. Monitor resource usage at peak and normal times. Cache frequent model outputs where possible. Use a robust queue-based architecture to handle spikes in traffic. Profile GPU usage for heavy inference loads, then optimize with techniques like mixed precision or model distillation for improved throughput.