
ML Case-study Interview Question: Deep Learning for Scalable Real-Time User Personalization and Engagement


Browse all the ML Case-Studies here.
Case-Study question
You are leading the Data Science team at a high-traffic online platform. User interaction dropped significantly, and the platform suffers from imprecise recommendations, search inefficiencies, and customer churn. Stakeholders need a machine learning solution that quickly personalizes results, scales to massive real-time data, and boosts long-term engagement. Propose a system that addresses data ingestion, feature engineering, model selection, model evaluation, and production deployment. Provide a full technical plan, including any algorithmic frameworks, data processing flows, and monitoring strategies. Outline how you would organize cross-functional efforts to ensure a robust end-to-end solution.
Detailed solution
Data ingestion and storage
Collect log-level data streams from user actions through a distributed streaming platform. Move these event streams into a fault-tolerant data lake. Ensure each record includes user ID, session context, timestamps, and content metadata. Ingest them with an Extract-Transform-Load workflow.
Feature engineering
Capture user behaviors from clickthroughs, dwell time, and search queries. Aggregate session-level statistics. Identify the top predictive signals and transform them into numeric, categorical, or embedding formats. Generate historical engagement features and session recency features. Combine real-time streaming data with static user profiles.
Model selection and training
Test multiple architectures. Choose gradient-boosted decision trees or a deep neural network that handles sparse and dense features together. For neural models, embed high-cardinality categorical variables. Start with a hidden-layer architecture that merges embeddings and dense features. Optimize with a standard loss function.
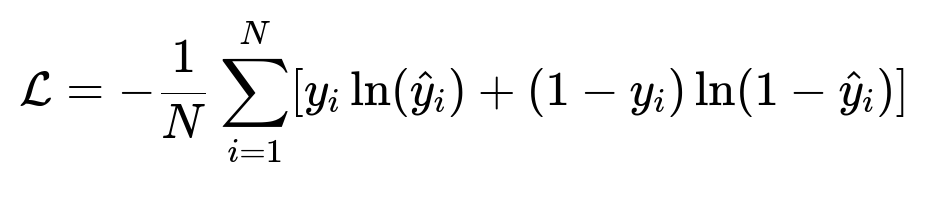
Here, N is the number of samples. y_{i} is the actual label (0 or 1). hat{y}_{i} is the predicted probability. This measures how well the model probabilities match the true labels.
Train the model on historical data. Validate with a holdout set. Then use an online A/B test to compare performance against existing baselines.
Implementation details
Implement data pipelines in Python. Use distributed computing frameworks to manage training on large datasets. Below is a brief Python code snippet showing a simplified approach to training with a deep model:
import tensorflow as tf
import numpy as np
# Assume X_train, y_train are preprocessed and loaded
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=256, validation_split=0.2)
Train this model on a cluster with GPUs or distributed CPU nodes if the dataset is large. Then export the trained model in a format compatible with your serving infrastructure.
Deployment and monitoring
Deploy the model as a real-time service. Monitor throughput, latency, and model quality metrics such as click-through rate and conversion. Track data drift. Retrain if performance declines or if new user behaviors emerge.
Long-term improvements
Incorporate advanced representation learning for user embeddings. Use deeper or more specialized architectures for sequential patterns. Explore multi-task learning that predicts multiple engagement targets simultaneously.
Possible follow-up questions and answers
1) How do you handle cold-start users with minimal data?
Leverage content-based features and generalized user profiles. Use item-level embeddings for recommendations. Cluster items by metadata and serve those to new users. Fine-tune the model to handle incomplete feature vectors. Apply real-time feedback signals from the user’s first sessions.
2) What steps ensure data consistency and reliability?
Validate incoming data with schema checks. Remove duplicates. Archive raw data for debugging. Implement checksums and hashing for large data transfers. Verify feature transformations with unit tests and daily pipeline checks.
3) How do you address latency constraints?
Use an online feature store. Precompute features that require heavy aggregation. Deploy a low-latency model-serving layer. Apply streaming inference for real-time user queries. Maintain minimal overhead at prediction time by limiting large feature transformations.
4) What hyperparameter tuning strategies would you apply?
Launch systematic hyperparameter searches. Configure random search or Bayesian optimization. Compare results on validation data. Use early stopping to prevent overfitting. Select final hyperparameters that consistently boost metrics across multiple splits.
5) Why choose cross-entropy instead of other losses?
Quantifies the divergence between predicted probabilities and actual labels. Yields smooth gradients that help neural networks converge. Adapts well to unbalanced classes by adjusting class weights or sampling strategies. Simplifies interpretation because lower cross-entropy implies better predicted probabilities.
6) How do you ensure reliable A/B testing?
Define clear success metrics, such as increased click-through rate or reduced bounce rate. Randomly assign users to test and control groups. Keep test durations long enough for statistical significance. Monitor confounding factors or changes in site layout. Stop tests only after stable convergence in metrics.
7) How do you handle potential model overfitting?
Regularize with dropout and weight decay. Use cross-validation. Monitor validation curves. Refrain from excessive hidden-layer size or unbounded training epochs. Evaluate on a long-tail test set to confirm generalization.
8) Why incorporate embedding layers for user and item features?
Represent high-cardinality user IDs or item IDs as dense vectors. Capture latent relationships. Reduce model parameters while preserving essential similarities between items and users. Boost capacity to learn from sparse data.
9) How do you retrain the model with real-time updates?
Maintain a rolling buffer of recent data. Periodically trigger incremental training or partial re-fitting. Update embeddings and track performance changes. Clear old training checkpoints when they become obsolete.
10) How would you handle missing data or sparse signals in production?
Impute with mean or mode if feasible. Set special indicator flags for missing values. Use embeddings that accommodate missing tokens. Evaluate production logs to see if missing data patterns change over time.
Explain these answers in technical depth. Show understanding of distributed systems, advanced model architectures, metrics, and big data best practices. A strong candidate can discuss edge cases and provide robust, maintainable solutions.