
ML Case-study Interview Question: Supervised Ranking on Social Graphs for Friend Recommendations


Case-Study question
You are tasked with designing a friend recommendation feature called “People You May Know.” The goal is to increase meaningful connections among users on a social media platform. There is an initial approach that suggests recommending contacts from a user’s uploaded address book. Another approach relies on analyzing the social graph to propose friends-of-friends. You also need a strategy to help new users who have few or no existing connections. How would you build this system to maximize meaningful connections?
Clarification of Key Requirements
You want to rank potential friends for any given user based on how likely they are to form a friendship. You have rich signals, such as mutual friends, similar profiles, co-engagement on events and posts, and usage patterns across multiple apps. You also face a cold-start problem for new users. You need to propose methodologies and algorithms to solve these challenges effectively.
Detailed Solution Explanation
Building the Ranking System
The approach uses signals from the platform to identify potential connections. A user’s profile attributes like age, employer, school, and location help measure similarity. Behavioral data such as mutual group memberships, shared event attendance, and messaging on interconnected apps provide valuable features. A candidate list forms from second- and third-degree connections in the social graph.
A supervised learning method can predict whether two users will form a friendship. Data about existing confirmed friendships becomes the training set. The target variable is whether two people eventually become friends. Features include mutual friend count, frequency of profile views, shared events, and other co-occurrences. The output is a probability that the connection would be accepted.
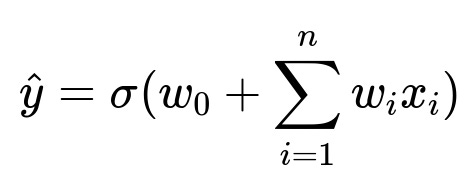
w_0 is the intercept term. x_i are the features, such as mutual friend count or shared groups. w_i are the learned weights for each feature. sigma(.) is the logistic function mapping the value into a probability between 0 and 1. When the probability crosses a chosen threshold, the pair is recommended to each other.
Unsupervised Methods
In settings where labeled data is insufficient, clustering approaches like K-means can group similar users. Dimensionality reduction using principal components analysis can also group similar users in a lower-dimensional space. Users in the same cluster are recommended to one another. These methods rely on feature overlap, including profile attributes and other engagement signals.
Addressing the Cold-Start Challenge
New users may not upload any contact list, so signals are limited. The system can boost new users’ visibility in the recommendations for existing users. The system can also display more “People You May Know” modules to new users, encouraging them to form initial connections. A progress bar can prompt them to complete key onboarding steps. Friend chaining—showing new suggestions immediately after a new user accepts a friend request—helps them quickly accumulate a base of connections.
Impact on Growth
The product is only valuable if each user has a sufficiently connected feed. Friend suggestions accelerate the formation of an active social graph. Good recommendations keep users engaged and reduce churn, especially during the onboarding phase. These factors improve the overall health of the network.
How would you handle data sparsity for brand-new users?
Data sparsity arises because new users lack historical interactions. Boosting them in existing users’ candidate sets helps gather more engagement signals quickly. Encouraging them to complete their profiles and connect with people from their contact lists or from relevant clusters expands their graph. Setting a rule-based threshold (for example, if a user has fewer than a certain number of friends after one week, show them extra friend suggestions) can address early inactivity.
How would you monitor the success of this recommendation system?
Key metrics are the number of newly formed connections per day and retention rates among new users. Tracking the acceptance rate of recommendations indicates how well the system targets relevant candidates. Measuring repeated engagement, such as two users messaging each other, signals meaningful connection. Evaluating how many new user accounts remain active over a certain time frame gauges the feature’s impact on overall platform growth.
How would you handle negative feedback about recommendations?
Building a logging mechanism for “remove suggestion” and “ignore” actions on friend recommendations allows the model to retrain on these signals. Observing repeated negative feedback for the same type of suggestion indicates certain features may be weighted incorrectly. Periodically updating the model, either online or in batch, ensures fresh data influences the ranking. Negative feedback reduces the likelihood of re-suggesting the same pair and improves the model’s overall precision.
What if the model still struggles with scalability issues?
Filtering billions of potential edges is computationally expensive. Incrementally build candidate sets using approximate nearest neighbor search for large-scale similarity computations. Use caching to store partial computations for a user’s second- or third-degree connections. Periodically refresh to keep friend lists updated. Distributed systems and graph databases can handle large-scale computations in parallel, using data sharding across multiple servers.
How would you ensure that the system meets privacy requirements?
Respect user data permissions by only analyzing phone or email contacts if they opt in. Clearly inform users about how contact matching works. Anonymize and encrypt raw data during processing, ensuring only aggregated signals feed into recommendations. Offer simple privacy controls that let users opt out of suggestions that arise from certain data sources.
How would you perform online experiments for these recommendations?
Use A/B testing to compare alternative models or different user interface designs. Randomly bucket a fraction of users to see whether new features drive higher acceptance rates and friend formation. Observe long-term metrics such as message frequency or session duration. Validate that changes do not harm user satisfaction or lead to lower retention.
What if the user’s engagement signals come from multiple apps under the same umbrella?
Aggregate cross-app signals to capture richer user context. Merge data from messaging platforms and photo-sharing services to strengthen the model’s understanding of user connections. Consolidate user profiles and friend graphs while respecting privacy settings. Evaluate whether more cross-app signals genuinely produce better friend matches in an online experiment.
How would you iterate to maintain model freshness?
Schedule periodic model retraining as user behavior shifts. Real-time updates can be done if you maintain a streaming pipeline that ingests live interactions (friend acceptances, profile visits, etc.). Retrain the weights for logistic regression or update cluster assignments in near-real-time. Introduce time-decay factors in features to avoid overweighting historical data that is no longer relevant.
What if you want to incorporate text-based signals like shared group names or post content?
Convert textual data into vector embeddings. Use natural language processing to extract similarity features, such as top topics or frequent keywords. Incorporate these embeddings as additional features. Weight them carefully to avoid overshadowing more direct social signals like mutual friend connections. Check for user privacy constraints.
How do you handle performance trade-offs for real-time recommendations?
Rank predictions must complete quickly. Pre-compute and store candidate lists for each user. Maintain a graph index that is updated at set intervals. Cache expensive computations like similarity scores in memory, then retrieve them for final ranking at query time. Maintain a fallback for scenarios where real-time data is missing, using older but cached ranks to avoid delays.
How would you ensure fairness and avoid unintended biases?
Monitor for patterns that systematically exclude certain user segments. Regularly analyze distributions of friend suggestions to see if some demographic or interest group is underrepresented. Adjust the feature weighting in the model or augment it with fairness constraints. Engage with a diverse set of test users to gather qualitative feedback on recommendations.
What might be your final implementation plan timeline?
Start by testing a baseline supervised model (logistic regression) on existing users to confirm the concept. Integrate cross-app signals. Expand the approach to new users with contact-import-based suggestions. A/B test short-term acceptance rates and longer-term retention. Iterate quickly, refining key features such as mutual friend counts or shared group embeddings. Prepare for incremental updates in a streaming pipeline.
No fluff or concluding statement.