
ML Case-study Interview Question: Scaling Podcast Preview Generation with Streaming ML Pipelines and GPU Acceleration


Browse all the ML Case-Studies here.
Case-Study question
A large audio platform must generate short podcast previews for hundreds of thousands of new episodes daily, leveraging multiple Machine Learning models and frameworks. The legacy microservices approach processes only a few thousand episodes per day. Design a high-throughput, low-latency system that ingests and transcribes raw audio, applies an ensemble of language and audio detection models, and produces short podcast previews at scale. Show how you would handle dependency conflicts, GPU usage, and pipeline orchestration for both batch and streaming modes. Propose monitoring, observability, and cost optimizations. Explain your approach to manage pipeline failures and ensure system reliability.
Detailed Proposed Solution
A robust solution requires transitioning from an ad-hoc microservices setup to a fully managed pipeline execution framework. That framework must handle large daily volumes of incoming audio data, ensure minimal latency for time-sensitive episodes, and streamline all stages of preview generation.
System Architecture
Start by ingesting raw audio content and transcription data into a unified pipeline. Deduplicate episodes to avoid unnecessary work. Pass each episode through a series of Machine Learning models within a consolidated pipeline. Group models into a few major pipeline transforms, each responsible for a subset of related tasks. Use GPU-backed workers to speed up inference, balancing the need for large memory capacity with cost.
Model Ensemble Integration
Include multiple Neural Network models for language analysis, topic detection, and audio event identification. Combine frameworks like TensorFlow, PyTorch, Scikit-learn, and other libraries inside a custom container. Use dependency resolution tools before packaging to avoid library version conflicts.
Batch vs. Streaming
A batch pipeline partitions input data and processes it on a scheduled cadence. This approach is simpler but introduces significant latency. A streaming approach ingests data in near real time, continuously processes new episodes, and auto-scales resource usage. Switching from batch to streaming cuts end-to-end latency from hours to minutes.
Managed Pipeline Execution
Use a managed pipeline engine capable of autoscaling and GPU orchestration. This engine fuses transforms for efficiency. Insert fusion breaks between heavy steps to avoid loading many models into GPU memory at once. Enable streaming to dynamically adjust the number of workers based on queue size.
Preview Latency
Definition of preview latency in text form: preview_latency = completion_time - ingestion_time.
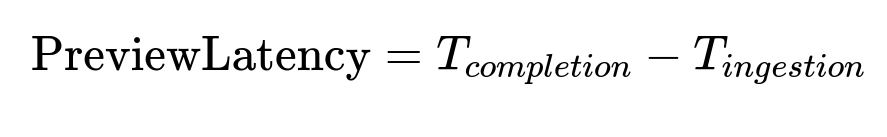
Where T_completion is the timestamp when the pipeline finishes generating the preview, and T_ingestion is the timestamp when the episode is available for processing.
Observability and Error Handling
Log successful outputs and exceptions to a central table. Include a fallback pipeline that handles cases where the main pipeline fails. Keep dashboards for pipeline throughput, backlog size, GPU utilization, and memory usage. Set up alerts to notify engineers if backlog sizes or error rates exceed thresholds.
Cost Optimization
Disable autoscaling for batch when the incoming load is predictable. Switch to streaming mode for frequent or unpredictable loads. Streaming reduces repeated spin-up and teardown cycles. Use smaller machine types or right-fitting techniques for steps that do not require GPUs.
Practical Dependency Solutions
Assemble all model and pipeline dependencies in a Docker image. Use a local environment as similar as possible to production to detect conflicts. Inspect all transitive dependencies carefully whenever upgrading the pipeline SDK or major libraries. Uninstall or pin packages that cause runtime crashes.
Follow-Up Question 1
How would you handle dependency conflicts that only occur under large input loads and are difficult to reproduce locally?
Dependencies often break under specific worker loads. Inspect the Docker image to find transitive libraries. Compare installed package versions in the final build to those in the local environment. Log all package versions and systematically remove or upgrade the suspicious libraries. Test with progressively larger inputs in a staging pipeline. Enable more verbose logging on worker nodes. Keep GPU memory usage in check by loading only the required models in each transform.
Follow-Up Question 2
What guidelines would you give for deciding between one large GPU transform versus multiple smaller transforms?
One large GPU transform reduces overhead from transferring data between transforms. However, it forces multiple models into limited GPU memory, risking memory contention. Multiple transforms improve modular debugging and isolate model loads, but they may require additional pipeline orchestration. Choose a single dense GPU transform when models are small or can share memory efficiently. Choose multiple transforms when each model is large, or if you need granular logging and fault tolerance at each step.
Follow-Up Question 3
How would you mitigate latency for time-sensitive podcast episodes?
Use a streaming pipeline that runs continuously, so new episodes start processing immediately. Scale workers on-demand. Create a priority queue for time-sensitive episodes. If hardware resources are limited, schedule urgent episodes first. Cache certain frequently used embeddings or partial results to cut inference time. Keep model loads warmed up on GPU-enabled workers.
Follow-Up Question 4
How do you ensure end-to-end observability and robust error handling in a production streaming pipeline?
Log input, output, and exceptions in a central data store. Monitor memory, GPU usage, backlog size, and job runtime in real time. Use incremental counters on each major step. Save failing episode identifiers and error traces for replay. Build automated fallback logic if a model step fails, redirecting episodes to a lighter pipeline variant. Configure alert rules that trigger when latencies exceed thresholds or errors spike.
Follow-Up Question 5
How would you incorporate further cost-saving measures once the pipeline is stable?
Profile the pipeline to see which steps consume the most GPU time. Switch smaller tasks to CPU where possible. Experiment with the pipeline’s concurrency limits. Use historical demand patterns to schedule fewer GPU workers during off-peak hours. Apply right-fitting methods so that steps with low load share smaller machines. Create aggregated micro-batches for inference to exploit GPU parallelism, then release GPU resources promptly once processing completes.