
ML Case-study Interview Question: Predicting Video Platform Churn from Outdated Browsers Using Classification Models


Browse all the ML Case-Studies here.
Case-Study question
A large online video platform noticed a drop in user engagement among viewers running outdated browsers. The outdated browsers hinder new features, resulting in lower watch times and higher churn. The platform wants a data-driven approach to detect users with outdated browsers, forecast potential churn, and recommend personalized interventions (like upgrade prompts or alternative streaming options). Propose end-to-end strategies for data collection, modeling, deployment, and measurement of performance. Describe approaches for handling noisy logs, scalable model training, and robust evaluation. Outline how you would build and iterate on this system in production.
Proposed Solution
Focus on user data ingestion from server logs and client-side telemetry. Identify fields that reflect browser version, session length, watch patterns, and interactions with upgrade prompts. Clean out incomplete entries. Map each user to a numeric feature vector capturing browser freshness, watch-time patterns, and usage frequency. Split the data into training, validation, and testing sets. Normalize numerical columns and encode categorical fields.
Train a classification model to detect churn risk. Assess whether logistic regression or gradient boosting performs better. For a logistic regression model, the probability of churn for user i with feature vector x_i is:
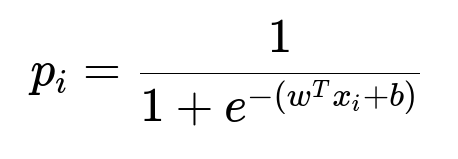
Where w is the parameter vector and b is the bias term. The model outputs p_i in [0,1]. A threshold separates users into high-risk or low-risk churn categories.
Evaluate the model with AUC and F1-score. Compare metrics to ensure coverage of true-positives and limit false-positives. Retrain or tune hyperparameters to handle class imbalance. For gradient boosting, use hundreds of decision trees, each learning residual errors from the previous iteration. Fine-tune tree depth, learning rate, and number of estimators. Compare final models on a validation set.
Implement a personalized intervention strategy for high-risk users. Recommend an upgrade prompt or alternative streaming methods. Track engagement changes post-intervention. Use an online experimentation setup. Assign high-risk users to treatment or control groups. Monitor metrics like watch time, conversion to updated browsers, or reduced churn. Release the best approach to all users once the results are statistically convincing.
Deploy the pipeline with a batch process or near-real-time scoring. For near-real-time, use stream processing to capture logs as they arrive, transform them into the feature format, apply a pre-trained model, and issue a prompt. Store inference outputs for tracking and model retraining. Schedule frequent model retrains if usage patterns shift.
Monitor for concept drift, especially if new browser versions introduce different user behaviors. Automate data quality checks. Evaluate partial dependencies to see how each feature influences the churn probability. Update interventions if the model identifies specific user segments needing different prompts.
Below is a Python-like snippet for building a logistic regression pipeline:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, f1_score
data = pd.read_csv("user_features.csv")
X = data.drop("churn_label", axis=1)
y = data["churn_label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression(solver='lbfgs', max_iter=500)
model.fit(X_train, y_train)
pred_probs = model.predict_proba(X_test)[:, 1]
threshold = 0.5
preds = (pred_probs >= threshold).astype(int)
auc = roc_auc_score(y_test, pred_probs)
f1 = f1_score(y_test, preds)
print("AUC:", auc, "F1:", f1)
Explain the metrics, identify users predicted as high-risk, and link those users to a system that triggers upgrade prompts.
Key Follow-Up Questions and Answers
How would you handle missing data in the logs?
Impute missing values with statistical methods like median or mode if the fraction of missing entries is small. Drop or exclude rows if the data is too sparse. Use indicators for whether fields are missing. Validate the effect of imputation on model performance.
How do you evaluate if your personalized interventions are effective?
Run an A/B test comparing two groups: one receiving targeted prompts and one receiving random or no prompts. Measure differences in watch time, engagement, browser updates, or other success metrics. Use significance testing to confirm whether the intervention yields meaningful improvements.
How would you handle high-cardinality categorical features?
Convert them into frequency-based or target-based encodings to avoid massive one-hot vectors. Monitor overfitting, because target encoding can introduce data leakage if not done properly. Use cross-validation to compute target-encoded values for training partitions to keep the process robust.
Why might gradient boosting outperform logistic regression?
Gradient boosting fits additive decision trees that can learn complex relationships between features. Logistic regression uses linear boundaries. Gradient boosting may capture non-linear interactions among features and adapt more effectively to complicated patterns in high-dimensional data.
What would you monitor in production?
Monitor prediction distributions, model drift, system latencies, user engagement metrics, frequency of outdated browser usage, and overall conversion rates. Investigate alert triggers if the model’s performance drops or if a major browser release changes user patterns. A well-instrumented pipeline helps you catch anomalies and update models accordingly.