
ML Case-study Interview Question: Hybrid Grocery Recommender: Boosting Repeats & Exploring New Items with Sequence Models


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with building a recommendation system for an online grocery retailer. Customers typically buy a small set of items repeatedly, but the store’s assortment is over 30,000 products. The goal is to recommend both items they already purchase (repeat) and items they have never tried before (explore). The store already has a model that predicts repeat purchases using features like average rebuy frequency and shopping periodicity. However, this model does not handle items a customer has not yet bought.
You must outline a plan that predicts both repeat and explore items for customers’ next baskets. Address the challenges of sparse historical data for rarely purchased products, subtle differences in individual preferences for similar products, and the long-tail distribution of shopping behavior. Propose an end-to-end solution with the relevant machine learning approach (or multiple approaches) and explain how you would adapt or combine models to handle both types of recommendations.
Describe how you would evaluate your system’s performance on both repeat and explore metrics. Suggest how you might leverage category-level data and handle scenarios where a customer’s purchase might materialize in future orders. Explain how you would design your architecture for scalable training and efficient online inference.
Detailed Solution
Overview of the Challenge
Customers often buy a narrow set of items repeatedly. Sparse data makes it difficult to recommend items they have never bought. Simple models with handcrafted features can excel at repeat predictions. Complex models like transformers or recurrent neural networks can predict future baskets, but they may struggle with the long-tail nature of grocery assortments.
Model Architecture
A two-pronged approach can work best: Use a highly tuned repeat model that captures user-specific rebuy patterns. Combine it with a separate model (or an integrated multi-task model) that focuses on explore items by leveraging sequence-based or embedding-based representations.
Core Formula for Sequential Modeling
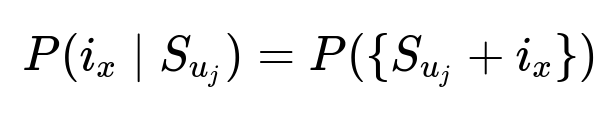
i_{x} is the candidate item. S_{u_{j}} is the sequence of items a user u has purchased in chronological order (up to the j-th purchase). The probability of a future purchase depends on how well item i_{x} fits into user u's prior sequence of shopping events.
One approach adapts standard single next-item prediction by processing multiple subsequences. Then aggregate the scores with a mean-pooling step to derive top-N recommendations for the next basket.
Repeat Model
A gradient-boosted tree model (such as XGBoost) can predict the repeat probability of each previously purchased item. Features include the time since last purchase, typical re-purchase intervals for the user, and item popularity. It excels in capturing strong periodic behaviors.
Explore Model
A sequence-based deep model (e.g., a transformer or recurrent neural network) can capture transitions between product categories. Embeddings represent items and users. Attention or recurrence extracts patterns from each user's purchase history.
Integrate or combine the outputs from the repeat model and the explore model with a final ranking. The ensemble method ensures stronger performance across both item types.
Category-Level Aggregation
Instead of recommending entirely new items, recommend categories that a user has never purchased. This intermediate step partially addresses data sparsity because category-level data is less sparse. Then refine the recommended categories into specific products based on user embeddings or popular products in that category.
Handling Delayed Purchases
Customers may only purchase recommended items in a future order. Track performance across multiple subsequent baskets, not just the immediate next basket. This broader window captures items that resonate with the customer but are purchased at a later date.
Model Evaluation
Use Precision@K and MAP metrics on a test set of baskets. Evaluate separate metrics for repeat and explore items. Compare your final system against baselines such as “always recommend the most popular items.” Examine performance on a holdout set that focuses on less frequently purchased items.
Example Code Snippet
import xgboost as xgb
import pandas as pd
data = pd.read_csv("repeat_training_data.csv")
X = data.drop("label", axis=1)
y = data["label"]
dtrain = xgb.DMatrix(X, label=y)
params = {
"objective": "binary:logistic",
"eval_metric": "auc",
"max_depth": 8,
"learning_rate": 0.1
}
model = xgb.train(params, dtrain, num_boost_round=100)
Above code shows training for a repeat model using XGBoost. For exploration, a separate deep learning pipeline is needed.
Reasoning on Production Considerations
Data pipelines for training must handle significant volume from daily orders. Real-time inference requires caching top repeat scores for quick retrieval. A separate deep model server can handle the explore logic. Consider ranking fusion for final recommendations to combine both scores.
Follow-Up question 1
How do you ensure that large neural architectures (like transformers) do not overfit on popular items and ignore tail items?
Answer
Layer normalization, dropout, and careful regularization are necessary. Large models may latch onto highly frequent patterns (milk, bananas, bread). Limit overfitting by:
Performing category-level pretraining to capture broad preferences.
Using uniform sampling or upweighting rare interactions during training. This combats popularity bias.
Applying negative sampling for items not purchased but likely relevant to users based on embeddings.
Follow-Up question 2
How do you handle the cold start problem for new users with minimal purchase history?
Answer
Profile new users through:
Basic demographic or regional data if available.
Overall popular products to bootstrap recommendations.
Real-time updates once a user buys items, quickly transitioning them into the repeat model.
Follow-Up question 3
How would you combine repeat and explore predictions in the final recommendation list?
Answer
Rank items by combining the repeat score P_repeat(i) and the explore score P_explore(i). A common practice is an additive or weighted average: final_score(i) = alpha * P_repeat(i) + (1-alpha) * P_explore(i). Calibrate alpha based on validation data, ensuring a balanced mix of both item types.
Follow-Up question 4
How do you measure the success of category-based recommendations?
Answer
Track how often users click on, or purchase from, recommended categories. Evaluate how many explore items in those categories eventually convert to purchases. Measure funnel drop-off from category-level suggestion to final basket. Use standard ranking metrics for categories (Precision@K for recommended categories versus actual categories purchased later).
Follow-Up question 5
What if your final recommended items conflict with the user’s dietary restrictions or brand preferences?
Answer
Use a filtering mechanism that excludes items flagged by user preferences. Maintain a user-level preference profile. Adjust the final candidate list by removing restricted items and brand omissions. Re-rank to ensure relevant alternatives stay at the top.
Follow-Up question 6
Which engineering considerations optimize serving latency in production?
Answer
Precompute repeat scores offline in a batch pipeline. Keep them in a low-latency store keyed by user-item. Deploy the deep model for explore in a streaming or micro-batch architecture, possibly behind a caching layer. Use approximate nearest-neighbor search for quick retrieval of top embeddings.
Follow-Up question 7
How do you refine or update your approach when new product categories are introduced?
Answer
Include newly created category embeddings trained via incremental learning. Propagate them through the sequence model. If historical data is limited, use similarity to existing categories. Carefully retune the ensemble weights so new categories have representation in the final ranking.
Follow-Up question 8
Why might you incorporate recipe recommendations instead of single-item recommendations?
Answer
Certain products sell better in combination (e.g., all ingredients for a pasta dish). Suggesting recipes solves a meal-planning task and can increase cross-sell. It also simplifies user decisions by recommending cohesive bundles. Track repeat behavior of recipes to see which sets of items resonate with each user.