
ML Case-study Interview Question: Fine-Tuning Multilingual Transformers for Scalable Content Moderation


Case-Study question
You are leading a multilingual content moderation project at a large consumer internet firm. You receive a massive volume of user-generated text messages in different languages, and you need to classify them for harmful or rude content. The core objective is to build a reliable deep learning model that scales across multiple languages, performs near real-time checks, and raises warnings for potentially harmful messages. You have large internal text datasets in 15+ languages, including English, Portuguese, and Russian. You also consider leveraging a pretrained multilingual Transformer model and further fine-tuning it on your internal data for toxicity detection. How would you design the system end-to-end, and what are the possible challenges and optimizations to ensure high accuracy across all languages?
Your tasks:
Explain:
How you would incorporate a multilingual Transformer as a foundation model for this classification.
How you would handle model fine-tuning with internal data that spans many languages and dialects.
How you would measure the model’s performance.
How you would enhance model interpretability to confirm that the model is encoding relevant multilingual semantics.
How you would handle the real-time inference constraint.
Add any assumptions or clarifications if needed. Then give a thorough solution, step by step, and justify each design choice. Propose additional use cases for the multilingual embeddings if relevant.
Detailed Solution
Overview
You need a robust pipeline that addresses both training and inference for multilingual content moderation. The core includes a multilingual Transformer model (for example, an XLM-RoBERTa). The pipeline loads this model, applies your custom classification head, then fine-tunes it on your labeled toxicity dataset. Each step must address language imbalance, real-time latency constraints, interpretability, and scalability.
Architecture and Data Processing
Start with a pretrained multilingual foundation model. This model has context-aware embeddings for up to 100 languages. Create a classification head on top, typically a linear layer, taking a 768-dimensional sentence representation as input. Feed data into the model in mini-batches, grouped by language or at random, depending on the training strategy. Separate the data into training and validation sets for each language to track how well the model generalizes.
Preprocessing must tokenize text for all supported languages. Retain minimal text cleaning to avoid losing any contextual cues, such as emoticons or punctuation that might indicate rudeness. Use the built-in tokenizer for the chosen model, since it knows how to handle multiple alphabets.
Fine-Tuning Strategy
Train the classification head with your internal labeled data. Use a moderate learning rate to avoid catastrophic forgetting of cross-lingual representations learned in pretraining. Introduce a small portion of unannotated text to preserve general linguistic representations if feasible.
When the data distribution is skewed toward certain languages, apply sampling techniques. For example, you can upsample underrepresented languages so that each mini-batch has a balanced subset of languages. Monitor validation metrics per language to confirm that minority languages are not overshadowed by majority languages.
Real-Time Inference
Deploy the model as a service behind an endpoint. Each incoming message is tokenized, fed through the model, and the resulting classification score determines if the message is flagged. Optimize the model with batching and GPU acceleration to keep latency below a set threshold (for instance, 200 milliseconds). Use fast tokenizers and possibly quantize the model if memory or speed becomes a bottleneck.
Cross-Lingual Semantic Analysis
The foundation model naturally positions semantically similar sentences in a shared embedding space. Sentences with similar meaning in different languages end up near each other. This improves the model’s ability to generalize across languages.
To illustrate a key formula that measures similarity in the embedding space, you can apply cosine similarity:
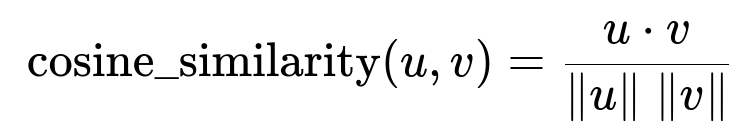
Here, u dot v is the dot product of the two embeddings, and ||u|| and ||v|| are their magnitudes. A higher score means the embeddings are more similar.
Interpretability
Extract the hidden states for tokens or sentence embeddings at different layers. Analyze them for separation by language or meaning. Techniques like t-SNE can reduce the dimensionality and offer a 2D or 3D view. If clusters of embeddings separate by language, you can derive insights into how the model manages multilingual features.
Explainability methods like Integrated Gradients or attention-weight inspection can highlight which words influence the toxicity prediction. This helps verify that the model focuses on relevant tokens and not random artifacts.
Possible Additional Use Cases
Use these embeddings for tasks beyond toxicity detection. For instance, you can detect language by training a small classification head on top of the embeddings. You can also measure cross-lingual similarity for tasks like duplicate message detection or real-time translation checks.
Example Python Snippet
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "xlm-roberta-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Example input
text_list = ["Hello there", "Bonjour", "Olá mundo"]
# Tokenize batch
inputs = tokenizer(text_list, padding=True, truncation=True, return_tensors="pt")
# Forward pass
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
print(predictions)
Explain in detail how each line processes the input and returns classification logits. In production, wrap this inference code within a service to handle requests.
Follow-up Question 1
How would you address issues with highly imbalanced data where some languages have very few toxic samples or minimal textual data?
Answer
Oversampling or targeted sampling is an effective strategy. Gather more data for underrepresented languages if possible, or artificially replicate minority-language samples to amplify their importance during training. Apply dynamic sampling so each mini-batch contains a balanced mix of languages. Monitor each language’s performance using separate validation splits. If some languages are extremely low-resource, explore transfer learning from typologically similar languages or use synthetic data generation.
In some cases, domain adaptation helps. If you have a small set of unlabeled text in a rare language, you can train the model on masked-language modeling tasks for that language to improve its general representation.
Follow-up Question 2
If the model starts returning too many false positives for certain languages, how would you debug or fix this issue?
Answer
Investigate those languages’ training samples. Check for translations or annotations that might be noisy. Increase the dataset size with better-labeled examples from those languages. Inspect attention heads or hidden-layer outputs to see if certain tokens are misrepresented, possibly due to morphological variations.
Adjust the threshold for classification or calibrate the output probabilities. You can perform threshold tuning per language if you notice systematic over-prediction. If you see consistent mistakes with specific slang or idioms, add curated examples to the training set for the model to learn local linguistic patterns.
Follow-up Question 3
How would you confirm that the learned embeddings correctly capture cross-lingual semantics?
Answer
Extract sentence embeddings from different layers for pairs of translated sentences. Measure their cosine similarity. High similarity indicates that the model places those translations close in the embedding space.
Run an experiment where you pick an English sentence, find its nearest neighbors among sentences in other languages, and verify if they are faithful translations. Visualize embeddings in a 2D or 3D projection (for example, t-SNE) and look for clusters by meaning across languages. If the clusters align semantically, that implies correct cross-lingual mapping.
Follow-up Question 4
How would you optimize this system for real-time checks on a high-traffic platform?
Answer
Host the model on dedicated hardware with GPU or high-performance CPU. Use optimized libraries (for example, ONNX Runtime or TensorRT) and batch requests together, if feasible. Use smaller variants of multilingual Transformer models for low-latency settings. You can quantize weights to 8-bit or 16-bit without losing much performance.
Apply load balancing to replicate the service and handle peak load. Monitor the inference response times and scale the number of worker processes dynamically. If the traffic is extremely large, consider approximate methods, such as caching embeddings of frequent sentences or partial document encoders, though you must ensure no loss in accuracy.
Follow-up Question 5
If you wanted to reuse this pretrained model for other tasks (for example, cross-lingual topic classification), how would you go about it?
Answer
Keep the same pretrained backbone and replace or add a new classification head suited for the topic classification task. Fine-tune on your topic-labeled dataset with minimal architecture changes. The cross-lingual capabilities remain embedded in the model’s backbone.
When you train, freeze the initial layers of the Transformer if your new dataset is small, so you preserve language-related knowledge. Unfreeze the top layers to adapt to topic classification. Validate performance on a multi-language test set and refine hyperparameters to maintain or improve cross-lingual transfer.
End of solution.