
ML Case-study Interview Question: Accurate Multimodal Product Categorization via Semantic-Aware Label Smoothing.


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform has a fast-growing product catalog with thousands of categories arranged in a complex hierarchy. Users often see incorrect or irrelevant categories for certain products, leading to a poor shopping experience and missed revenue. You must build a robust product categorization model that learns meaningful relationships among product labels, handles data imbalance, and improves the semantic consistency of the model’s top predictions. How would you design, implement, and optimize a multimodal solution that incorporates both text and images to address this problem?
Detailed Solution
Overview of the Core Objective
Accurate product categorization across thousands of hierarchical labels requires more than traditional one-hot encoding. Simple classification approaches ignore semantic similarities between related categories and often produce severe misclassifications. Incorporating semantic information into label representations helps smooth the decision boundary for related categories while still pushing unrelated categories farther apart.
Traditional One-Hot Limitations
One-hot encoding (OHE) treats each category as unrelated to any other category. This disregards the fact that some categories are similar (for example, cowboy_boots and rain_boots) while others are very different (for example, boots versus t_shirts). Misclassifications between similar categories are penalized as harshly as misclassifications between unrelated categories.
Semantic Label Smoothing
Label smoothing distributes some probability mass to the negative classes instead of assigning a hard 1.0 probability to the true class. Uniform label smoothing assigns the same small probability to all other classes and loses information about which classes are more alike. Instead, semantic label smoothing leverages a distance or similarity matrix to assign higher probability to semantically closer classes.
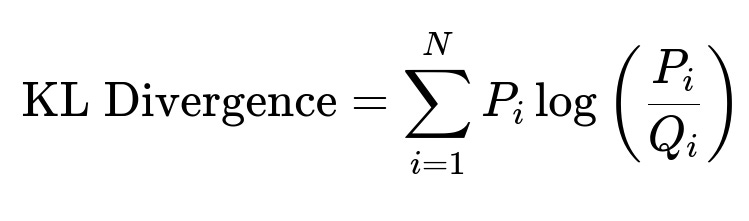
This measures the difference between the softened label distribution P_i and the predicted distribution Q_i. Minimizing this term nudges the model to produce logits that match the semantically smoothed target.
Feature-Based Label Representations
Another strategy transforms the multi-class problem into a multi-label one by encoding each category with binary patterns that capture shared features. Classes that share certain visual or textual cues might share bits in their label encoding. This approach can accelerate learning but requires carefully defined binary codes, which can be difficult to scale for thousands of categories.
Multimodal Architecture
Freezing pretrained encoders (such as text and image encoders from a foundational model) captures general representations of product images and titles. Training a separate, smaller fusion network on top of these encoders for product categorization, combined with a focal loss to handle class imbalance, is effective. Semantic label smoothing can be added as an auxiliary objective, guiding the logits to align with the smoothed label distribution.
Curriculum Learning
Gradually hardening the smoothed labels during training can help the model learn coarse similarities first, then more fine-grained distinctions. Early in training, the model sees less “sharp” labels. As epochs proceed, the smoothing factor is decreased so that the model becomes more confident about final predictions.
Sample Python Snippet for Training
import torch
import torch.nn as nn
import torch.optim as optim
class FusionNetwork(nn.Module):
def __init__(self, embed_dim, num_classes):
super(FusionNetwork, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(embed_dim, 512),
nn.ReLU(),
nn.Linear(512, num_classes)
)
def forward(self, fused_embedding):
return self.mlp(fused_embedding)
# pseudo code for the training loop
model = FusionNetwork(embed_dim=1024, num_classes=4350)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
focal_loss = FocalLoss() # assume custom implementation
kl_loss = nn.KLDivLoss(reduction='batchmean')
for epoch in range(num_epochs):
for images, titles, semantic_targets in dataloader:
# images -> pretrained image encoder -> image_emb
# titles -> pretrained text encoder -> text_emb
# fused_emb = some_fusion_layer(image_emb, text_emb)
logits = model(fused_emb)
focal_l = focal_loss(logits, true_labels) # standard multi-class labels
# semantic_targets is a distribution capturing similarity
log_probs = nn.LogSoftmax(dim=1)(logits)
kl_div = kl_loss(log_probs, semantic_targets)
total_loss = focal_l + kl_div
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
Experimental Observations
Tests with millions of product samples and thousands of classes show that semantic-aware label smoothing boosts both top-1 accuracy and preserves semantic coherence in the model’s top predictions. Many false predictions are less “embarrassingly off” because top labels stay within a neighborhood of the true label, improving overall user experience.
Follow-up Question 1: How do you quantify the semantic relationships among labels?
A simple approach uses a pretrained text encoder to obtain embeddings for each category name. Calculate pairwise cosine similarities to build a similarity matrix. For each true label, pick its top-k neighbors to construct a soft label distribution. Normalization ensures probabilities sum to 1. Classes with higher similarity scores receive higher probability mass, which smooths labels more aggressively where semantic overlap is strong.
Follow-up Question 2: How would you handle label imbalance?
Focal loss is widely adopted. It downweights easy examples and boosts difficult ones. This helps address long-tail categories that appear rarely. In highly imbalanced data, many products belong to a few major categories, while others have minimal coverage. Focal loss with well-chosen hyperparameters (gamma and alpha) is effective in preventing large classes from overshadowing small ones.
Follow-up Question 3: Why combine focal loss with KL divergence?
Focal loss focuses on correct classification for imbalanced data. KL divergence ensures the model learns a probability distribution aligned with semantic smoothing. These two terms solve separate but complementary problems. Focal loss alone does not enforce semantic consistency among similar labels, and KL divergence alone does not handle imbalance. Combining them balances these objectives.
Follow-up Question 4: How do you evaluate severity of misclassifications?
Instead of only checking top-1 or top-5 accuracies, measure how many predicted classes land among the top-k nearest neighbors of the ground truth label. If a misclassification points to a closely related label, that error is less severe than pointing to an unrelated label. This numeric count of how many predictions lie close to the correct category highlights model performance on semantic coherence.
Follow-up Question 5: What if you cannot rank category closeness precisely?
Using approximate neighbors still offers value. You can define a similarity threshold or pick top-k nearest neighbors without strict ordering. Assign equal probability to those neighbors in place of weighting by exact distances. This uniform approach simplifies label smoothing while still leveraging a partial notion of semantic similarity. It works well when the taxonomy is too ambiguous for precise pairwise distances.