
ML Case-study Interview Question: Knowledge Distillation & Automated Pipelines for Scalable DNN Recommendation Rankers.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale platform provides a contextual recommendation feed when a user clicks on a piece of content to view it in detail. The team needs a pipeline to log training data efficiently, sample from high-volume impressions and engagements, and regularly refresh the underlying deep neural network model. The model must adapt to changing user behavior and content shifts, while ensuring stable performance. Propose a complete solution for designing and maintaining this recommendation ranker. Address logging strategy, data sampling, knowledge distillation, and automatic retraining. Suggest ways to optimize both model quality and system efficiency.
Proposed Solution
Logging Strategy
Hybrid logging captures user impressions and engagements. The pipeline logs a lower percentage of impressions while keeping all positive actions, reducing storage without sacrificing crucial information. A service on the client side logs seen items, then requests additional features from a backend service. Duplicates are pruned before ingesting data into storage.
A small slice of random traffic is logged in full. These fully logged sessions help correct possible biases and serve as a reference for evaluation or calibration. This small random dataset is also crucial for offline replay experiments that compare new models against a baseline.
Data Sampling
Raw data often arrive in massive volumes. A dedicated sampling job in a batch processing environment (for example, using PySpark) transforms a petabyte-scale dataset into a more manageable training dataset. The job can apply configuration-driven logic to sample negative labels (impressions with no engagement) while preserving all positives. This manages class imbalance and lowers training cost.
Varying sampling configurations, such as focusing on certain user segments or content types, can systematically shift the training distribution to prioritize specific outcomes. Experiments show that refined sampling yields consistent quality gains in user engagement, even site-wide.
Future plans involve integrating the sampler with a distributed data loader (for example, using Ray) to perform sampling on the fly. That reduces workflow runtime and storage overhead by unifying sampling and model training steps into a single pipeline.
Knowledge Distillation
A teacher model provides scores that guide the student model’s learning. The training objective combines the student model’s cross-entropy loss with a Kullback-Leibler divergence term between teacher and student outputs. Below is one typical formulation of a knowledge distillation loss:
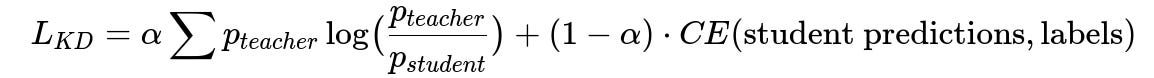
Where:
p_{teacher} is the teacher model's predicted probability distribution (in text form for inline references).
p_{student} is the student model's predicted probability distribution.
alpha is a constant in [0,1] controlling weight of the divergence vs. ground truth labels.
CE(...) is cross-entropy against the true labels.
The previous production model often serves as the teacher. The new model learns from these teacher scores to maintain consistency in ranking behavior while still improving upon fresh data.
Automatic Retraining
A scheduled pipeline (for example, an internal Auto Retraining Framework) triggers a new training job at intervals (daily, weekly, etc.). It performs data validation checks on feature distributions and label statistics. The training job then runs the model, performs offline validation, and—if metrics exceed configured thresholds—pushes the model to production.
The platform uses a multi-model approach: one model is uncalibrated for teacher-student distillation, and a calibrated version is used in serving. Both must be refreshed at once so that the distillation teacher and served model remain synchronized. Automated alerts and holdout experiments check each new release for improvements or regressions in user engagement metrics.
When the new model passes tests, it is gradually deployed. If the updated model exhibits performance issues in real time, the system can revert to a known good model. Consistent gains appear over time by capturing shifting user preferences, content trends, and distribution drifts.
Code Snippet Example (PySpark Sampler)
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SamplingJob").getOrCreate()
full_data = spark.read.parquet("path_to_full_data")
# Example: keep all positive labels, sample negative labels at 10%
sampled_data = (full_data
.filter("label == 1 or rand() < 0.1")
)
sampled_data.write.parquet("path_to_sampled_data")
This code snippet shows a simple negative sampling strategy that can be extended with more sophisticated filters. The training job then reads path_to_sampled_data.
What if your dataset has distribution drifts over time?
Refreshed data captures daily or weekly changes in user tastes, content supply, and trends. Automatic retraining addresses drifts by leveraging the most recent user interactions. Offline checks ensure that feature distributions match expected ranges. If certain inputs drift in ways that degrade predictions, pipeline owners adjust sampling or add new features. In advanced setups, real-time monitoring checks user feedback distributions to detect abrupt changes.
How do you ensure the teacher model does not lock you into a suboptimal state?
The teacher acts as a guiding reference but not the sole arbiter of correctness. The student still receives signals from actual user interactions. Tuning alpha ensures the model balances teacher knowledge with ground-truth feedback. Periodic experimentation can compare teacher-distilled models against non-distilled models to confirm that the teacher approach remains beneficial. If the teacher model has degraded, rolling back to an older version or training from scratch remains a fallback.
How would you handle performance regressions after deployment?
Pre-deployment checks compare the new model’s metrics against a baseline. If the new model’s performance regresses after live deployment, revert to the stable baseline. Conduct deeper offline experiments to isolate which segments or features caused the regression. Inspect data distribution changes, check sampling logs, or verify knowledge distillation alignment. Adjust sampling or retrain with corrected data. Monitoring tools must track engagement, latency, and resource usage.
How do you combine the random traffic dataset with the main dataset?
The random traffic slice is fully logged to capture items users did not click or even see in detail. Merging it with the main dataset offers a less biased view of negative samples and overall candidate ranking. When constructing final training data, keep some fraction of random samples to prevent overfitting to previously engaged items. This combined dataset improves calibration and helps measure model robustness.
Why does weekly retraining balance model freshness and overhead?
Frequent retraining (e.g., daily) can catch fast user preference changes but may incur high operational costs. It can also accelerate propagation of teacher model errors. Infrequent retraining (e.g., monthly) risks stale parameters failing to reflect user behavior shifts. Weekly schedules often strike the right balance. Automated frameworks handle pipeline orchestration, offline validation, model registration, and production deployment with minimal human intervention. This scheduling ensures consistent refreshes while reducing maintenance load.
How do you verify real impact on user engagement and satisfaction?
Holdout experiments randomly split traffic between the new model and the previous production model. Continuous logging measures actions, dwell time, or conversions. Statistical comparisons show lifts in key metrics such as clicks, saves, or downstream engagement. In practice, a month-long holdout helps confirm that the improvement remains stable and not just a short-term fluctuation.
How do you scale this approach for even larger user bases or item catalogs?
Use distributed computing for data preprocessing (PySpark, Ray, or similar frameworks) and distributed training (for example, using a GPU cluster). Handle logging with scalable storage solutions optimized for large-scale writes. For real-time inference, deploy the model on a low-latency serving platform with caching or batching. Constantly profile bottlenecks in data ingestion, model scoring, and memory usage to maintain throughput for billions of items.
How would you further optimize the sampling process to reduce storage overhead?
Implement on-the-fly sampling during the data loading stage. A distributed data loader can filter out negative samples that do not meet certain thresholds and preserve all positives. This removes the need to write huge intermediate sampled datasets to disk. Storage savings accumulate when multiple training configurations share the same base data. Caching partial results or streaming data transformations also reduces time-to-train.
What is the key insight behind focusing on training foundations rather than only model architecture?
Cutting-edge architectures can help, but flawed data pipelines or stale models degrade performance. Good logging captures the right signals at minimal cost, strong sampling corrects biases, and consistent retraining tracks user interest shifts. Together, these foundation improvements unlock the potential of deep learning models, sustain metric lifts, and drive system reliability.