
ML Case-study Interview Question: Detecting Delicate Text Beyond Toxicity with Transformer Models


Browse all the ML Case-Studies here.
Case-Study question
You are given a large-scale text-processing system and asked to detect text segments that are emotionally charged or potentially triggering, even if they are not overtly toxic. The system must capture a wide range of risky content, from self-harm and mental health references to texts that discuss race, religion, or socioeconomic issues. You must create a robust model and supporting pipeline that can accurately identify such “delicate” text while minimizing false positives for content that uses strong language but is not truly risky. Describe your proposed solution approach and how you would handle data acquisition, annotation guidelines, model architecture choices, and evaluation. Assume that existing toxicity-detection solutions alone are insufficient.
Detailed Solution
A robust solution starts by defining delicate text as content that discusses emotionally charged or potentially triggering topics, with potential harm to users or language models. This category includes topics like self-harm, mental health, hate speech, violence, or explicit discussion around sensitive personal identities. Traditional toxic-language detectors may fail to capture this entire spectrum, since delicate text can be non-vulgar but still risky, or it can involve sensitive issues without direct insults.
Gathering data for a specialized delicate-text detector requires careful design. Start by sampling from news sites and forums covering controversial or sensitive subjects. Construct a dictionary of keywords associated with delicate topics, each tagged with an approximate severity level. Filter text passages by these terms to capture varied examples, while including neutral examples for contrast. Labeling must reflect both binary classification (delicate vs. not delicate) and risk severity (low, medium, high). Use professional annotators with domain expertise, and provide thorough examples to reduce confusion about edge cases.
Consolidate these annotations into a training set and hold out a benchmark set for final evaluation. Fine-tune a transformer-based classifier (for instance, a RoBERTa variant) on this specialized training set. Make sure the objective reflects the intended delicate-text label, not purely toxicity. Compare performance against typical hate-speech or toxicity datasets to confirm that the new classifier can capture subtle but risky expressions (e.g., mental health admissions or threatened self-harm) and not over-penalize harmless profanity.
Core Formula for F1 Score
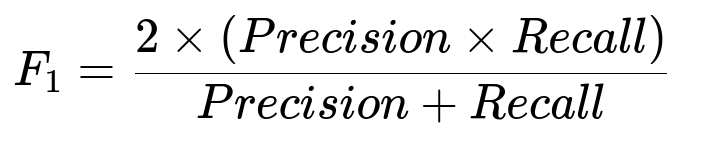
Precision measures how many predicted delicate texts are actually delicate. Recall measures how many of the delicate texts in the dataset are detected. The harmonic mean (F1) is a balanced metric when you must optimize for both.
Benchmarks show that toxic-language models often miss medical or mental health topics or mislabel benign profanity as delicate. Calibrating the detection threshold is crucial. When the model is tuned too aggressively, it flags harmless content; when it is not strict enough, it misses sensitive messages. An optimal threshold is typically found by maximizing the F1 score on the held-out dataset.
Domain adaptation or model ensembling can further boost accuracy. You may combine specialized detection modules for hate speech, self-harm, and general delicate topics. This ensemble can pass uncertain cases to a more advanced classifier for final decision.
In production, handle sensitive predictions with caution. Set up confidence levels that might trigger secondary checks or a different user experience. Because this content can be legally or ethically high-stakes, incorporate privacy, compliance checks, and a robust feedback loop from users or moderation experts.
What if your delicate-text model misclassifies benign content containing strong words?
Train the model on sufficiently diverse negative examples of profanity or strong language that do not indicate risk. Emphasize this difference in annotation guidelines. Use techniques like confidence calibration to interpret model outputs. If the confidence for “delicate” is borderline and the text is only profane, steer the model toward “not delicate.” Manual reviews of borderline cases may be necessary to refine these thresholds.
How can you address domain drift when new sensitive topics emerge?
Update your training data with newly observed vocabulary or contexts. Increase coverage by scraping additional sources that mention emerging topics. Annotate carefully to maintain consistency. Periodically retrain or fine-tune the model with a blend of older data and fresh samples. Monitor the model’s performance metrics and user feedback to catch domain drift early.
How do you handle sub-topics like hate speech within delicate text?
Treat hate speech as a distinct category of delicate text and label it with a specialized sub-label. Maintain a multi-tier classification: first, detect delicate text in general. Then refine with specialized modules that classify hate speech, self-harm, and other specific domains. Train these specialized modules on relevant sub-labels to improve accuracy.
How can you explain model decisions to non-technical stakeholders?
Offer short highlights of which phrases or keywords contributed most to the delicate classification. Use methods like attention visualization or gradient-based explanations to emphasize risk factors. Present confusion matrices and threshold-based performance plots to clarify trade-offs. Maintain straightforward criteria for why certain language is flagged as high-risk or why benign profanity is not flagged.
Is a single classification score sufficient, or should we estimate severity?
A single delicate vs. not-delicate label might be too coarse. A severity scale helps prioritize alerts. For instance, you could rank self-harm or direct threats higher than mild controversial statements. In practice, tie this severity to actionable interventions, such as immediate help resources for self-harm. The same model architecture can predict ordinal risk levels, but it requires well-defined labels and examples for each severity level.
How would you implement real-time inference at scale?
Use efficient transformer-based architectures or quantized versions. Leverage GPU or TPU acceleration and batch requests when feasible. If latency is a constraint, consider distilling a smaller model from the original. Cache repeated or partial requests when possible. Use robust logging and monitoring to detect bottlenecks or performance degradation in production.
How can you ensure data privacy?
Store raw data securely, restrict access, and anonymize or redact personally identifiable information. Carefully handle text referencing personal details or sensitive identities. Only keep minimal necessary details for model development. If working under strict regulations, incorporate privacy-preserving techniques like data masking. Document compliance with relevant data protection standards.
How can you manage the ethical concerns of labeling and using data about self-harm or trauma?
Provide mental health resources and training for annotators. Limit exposure to the most extreme content by distributing tasks carefully. Keep annotation guidelines precise, and allow annotators to skip samples that are too distressing. Regularly rotate tasks or incorporate professional supervision. Document your policy for data usage, storage, and annotation to align with legal and ethical standards.
When would a multi-lingual approach be necessary?
If your user base spans different languages, scale the pipeline beyond a single language. Gather labeled data for each language, or use cross-lingual learning with shared embeddings. Verify that cultural nuances are addressed, since what constitutes delicate content may differ by region and language. Validate performance with in-language test sets. Roll out in phases to mitigate risks.
How do you measure success beyond traditional metrics?
Observe real-world outcomes, such as the rate of missed critical content, user satisfaction, and false alarms. Engage a human-in-the-loop review of borderline decisions. Track feedback from users who might report misclassified or missed delicate messages. Combine these feedback loops with offline testing for a more holistic assessment. If success metrics degrade, retune or retrain the model.
Why might non-contextual approaches fail?
Non-contextual keyword matching often flags all text containing certain terms, but words like “violent” or “depression” may be used in neutral discussions, false-alarming the system. A context-aware model discerns the actual sentiment, stance, or risk level. Modern transformer encoders capture context to avoid naive triggers, reducing misclassifications.
How do you manage continuous improvement?
Maintain a pipeline that supports routine re-labeling of evolving terms. Create a monitoring dashboard to catch performance drifts. Gather user or expert feedback on false positives and negatives to guide iterative refinements. Retrain periodically with improved annotation coverage. Keep versioned models so you can revert to stable baselines if regressions occur.
What final advice do you have for optimizing a delicate-text detection pipeline?
Continuously monitor metrics and user reports. Use advanced architecture but keep it interpretable. Validate across varied sensitive domains. Update data and thresholds to match new language trends or topics. Leverage risk-based severity so the system can respond proportionally. Always incorporate ethical practices around training data, annotation, and user impact.