
ML Case-study Interview Question: Ad Strategy Simulation: Optimizing Bids and Auctions with Reinforcement Learning


Browse all the ML Case-Studies here.
Case-Study question
A large online platform that hosts thousands of advertising campaigns wants to evaluate new ad bidding and auction strategies. Their existing process of conducting online experiments is costly and time-consuming. They created a simulator that uses historical or synthetic auction logs, replicates real-time bidding and campaign state updates, and models how users respond to winning ads. The simulator’s key modules are: (1) the list of auctions, participants, and user contexts; (2) a set of campaigns each with a bidding agent, pacing agent, and campaign monitor; (3) an auctioneer that scores and ranks bids; and (4) a user-response model for clicks and orders. They also have an internal logging system to track spend, clicks, and conversions. Your task is to design a proof-of-concept plan to incorporate multiple changes in bidding and pacing strategies. The goal is to demonstrate how to use the simulator to test new auction mechanisms (like different reserve prices), and to recommend optimal campaign budget allocations for specific regions. Provide the approach, the data needed, the system modifications required, the user-behavior modeling approach, and how you would validate that simulator results align with reality.
Proposed Solution
Simulator Overview and Data Requirements
Fetch a comprehensive set of auction logs containing the following: all candidate ads eligible for each auction, their real-time states, and contextual signals such as user location and time of day. Include data for campaigns that might have been filtered out by ranking steps to avoid selection bias. Construct synthetic data if you need to test unusual market conditions or saturate extreme use-cases.
Bidding Agent and Reinforcement Learning
Use a reinforcement learning approach to help each campaign decide the best bid. Represent the environment as a sequence of auctions. Let the agent observe features such as remaining campaign budget, time horizon, and signals about user intent. The agent calculates an action (the bid) to maximize future reward, typically defined by clicks, orders, or revenue. A typical Q-learning update rule might be:
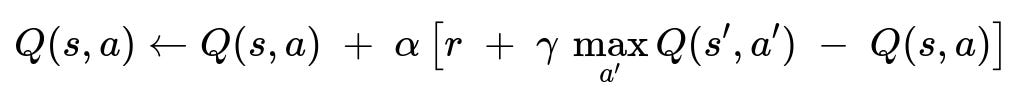
Here, Q(s,a) is the current estimate of the total discounted future reward for taking action a in state s. alpha is the learning rate. gamma is the discount factor for future rewards. r is the immediate reward from the environment (clicks or orders). The max_{a'}Q(s',a') term is the best future value from the next state s'. This learned policy drives the bidding logic. Reinforce it with pacing constraints to ensure campaigns do not deplete budgets prematurely.
Pacing Mechanism
Implement a pacing agent that adjusts bid multipliers based on how quickly the campaign is consuming its budget. When the pacing agent detects overspending, it reduces the next bid. If the campaign is underspending, it increases the next bid. Combine this multiplier with the reinforcement learning output to control daily spend. The pacing agent tracks real-time spend, time elapsed, and remaining budget. It updates an internal multiplier m, so the final bid is typically base_bid multiplied by m.
Auctioneer and Reserve Price Experimentation
Run the Auctioneer with configurable reserve prices. Given a list of bids, filter out those below the reserve. Assign winners via first-price or second-price rules. Track key metrics (cost-per-click, total spend, revenue, click-through rate). Vary the reserve across multiple simulation runs to identify potential sweet spots. Observe how different segments of advertisers respond in your logs.
User Response Modeling
Estimate impression probability, click probability, and purchase probability from a predictive model. Derive calibration from historical data. For example, if the predicted click probability for a user-campaign pair is p, simulate a Bernoulli draw with parameter p to decide if a click occurs. This approach scales well and emulates real user variability.
Budget Allocation Across Regions
Integrate a mechanism to simulate campaigns that allocate budgets geographically. For each region, allow an extended budget or restricted budget and measure changes in spend, conversions, or overall net revenue. Observe market equilibrium effects by tracking how competition evolves in each region and how user response changes if more ads are displayed.
Validation Strategy
Replay real historical auctions in the simulator with actual bids and measure how closely the simulation metrics match the real outcomes. If the simulator is sufficiently accurate, the difference between predicted and actual spend or click metrics should be minimal. For new strategies that have never been tested online, run small-scale online experiments on a subset of traffic. Compare experiment results with simulator predictions. If the results align, expand deployment.
Implementation Example in Python
Use a main driver that initializes the environment, loads the Auction Context, and sets up the Bidding Agent, Pacing Agent, Auctioneer, and User Response Simulator. A simplified pseudocode:
class SimulationEnv:
def __init__(self, auction_logs, config):
self.auctions = auction_logs
self.config = config
self.campaigns = [AdCampaign(cfg) for cfg in config['campaigns']]
self.auctioneer = Auctioneer(config['reserve_price'], config['auction_type'])
self.user_response_model = UserResponseModel(config['calibration_params'])
def run(self):
for auction in self.auctions:
bids = []
for campaign in self.campaigns:
bid_value = campaign.bidding_agent.get_bid(auction)
bids.append((campaign.id, bid_value))
winners = self.auctioneer.run_auction(bids, auction)
for winner in winners:
user_action = self.user_response_model.get_click_or_order_prob(auction, winner)
winner_campaign = self.get_campaign_by_id(winner)
winner_campaign.monitor.update_campaign_state(user_action, auction)
simulation = SimulationEnv(my_auction_logs, my_config)
simulation.run()
log_data = simulation.get_logs()
analyze_results(log_data)
Model Interpretations and Next Steps
Inspect the logs to see if pacing logic is controlling daily spend. Check how the reinforcement learning agent modifies bids. If a region is saturating quickly, see if the agent lowers bids or reserves. Iterate with refined user response calibration, especially if usage patterns differ significantly by time-of-day or geography.
Potential Follow-Up Questions
How do you ensure the simulator closely mimics real user behavior?
Train a reliable predictive model for user interactions using features such as user demographics, time-of-day, context of the query, and advertiser attributes. Calibrate this model with real conversion data. Compare simulator outcomes (e.g. click rates) to real outcomes in a holdout set. If the distribution does not match, adjust the calibration function until you can replicate observed metrics. Validate with smaller real experiments and measure how closely the simulated predictions match actual data.
What are the challenges of using historical logs to simulate future states?
Logs reflect past strategies and filter out certain advertisers who might have been eliminated earlier. This bias can lead to unrealistic outcomes if new or previously filtered advertisers enter the simulator. Solving this requires collecting logs at more upstream stages to have full visibility. Another issue is that historical logs contain bids generated by an older policy. In a new policy scenario, advertisers might behave differently, so the simulator’s baseline data might become less accurate.
Why not rely only on synthetic data for testing?
Synthetic data allows control over every parameter, but it can deviate from real-world distributions in unpredictable ways. It cannot fully capture marketplace dynamics like competition among advertisers or actual customer buying patterns. A hybrid approach combines real auction logs with synthetic expansions to handle edge cases.
How do you handle region-by-region differences in budget allocation experiments?
The simulator treats each region as part of the environment with unique user densities and advertiser pools. Each campaign has a segmented budget or certain portion allocated to each region. The pacing agent monitors each region separately. If the model indicates overspending in a region, it scales down bids. If a region remains under-target, it scales up bids. Observe the interplay with competing campaigns also operating in that region. Compare the final performance across regions to see if the budgets were optimally distributed.
How do you decide that your reserve price design is optimal?
Compare total ads revenue, advertiser ROI, and user engagement across different reserve-price settings. Observe how the distribution of winning bids shifts. Check the simulator logs for signs of suppressed competition or inflated bid prices. If a small tweak in reserve price yields a higher overall profit without harming user engagement, that suggests a more optimal strategy. Confirm the results with a limited online experiment to reduce the risk of large-scale misalignment.
How would you adapt the simulator if you introduced a new ad format?
Incorporate the new format into the user-response model by extending the click probability function. If it requires a distinct set of advertisers or separate auctions, add a parallel module in the core flow to handle that format. Log impression, click, and spend metrics specific to the new format. Validate with a small real test to confirm that user behaviors in the new format remain consistent with the simulator’s assumptions.
How do you interpret performance metrics in the presence of multiple campaigns with shared constraints?
Track each campaign’s performance individually and in aggregate to see how they compete for limited user attention. If two big campaigns overshoot spend in overlapping markets, the simulator might show a drop in marginal performance for both. Compare cost-per-click, cost-per-order, and total conversions across multiple campaigns. Examine whether the presence of large advertisers starves smaller campaigns. Evaluate fair bidding policies or dynamic pacing to keep the system balanced.
How do you ensure the simulator continues to be relevant over time?
Update historical auction logs regularly. Retrain or re-calibrate the user response model with the newest data. Incorporate new campaign types or advertiser behaviors. Continuously validate simulated predictions against real experiments. Maintain instrumentation in production so that whenever the real system changes (new ranking features, new bidding constraints), you reflect those changes inside the simulator.