
ML Case-study Interview Question: Optimizing Subscription Renewals with Machine Learning for Optimal Charge Timing.


Browse all the ML Case-Studies here.
Case-Study question
You are asked to optimize recurring subscription payments for an online service. Many customers enter renewal failure due to insufficient funds, expired cards, or other reasons. The organization wants to reduce involuntary churn and ensure smooth payment collection. They have a billing system with fixed retry schedules (for example, retry every 4 days until day 28). The rule-based system is cumbersome to maintain and leads to degraded performance over time. How would you design and implement a Machine Learning solution that determines the optimal times to charge a customer to maximize successful payment rates and minimize manual intervention?
Detailed Solution
Overview of the Approach
Machine Learning can replace hardcoded billing rules by using predictive or ranking models that suggest the best time to retry a payment. This reduces failed payments and churn. The system automatically learns patterns for different user segments, card types, and usage behaviors.
Data Collection and Features
The system needs a robust data pipeline. Important signals:
Payment history: Timestamps of previous charges, success/failure reasons.
Customer usage: Frequency and recency of account activity.
Billing cycles: Subscription length, renewal date, payment type.
External signals: Geographic location, time zone, known bank behaviors.
Collecting these signals in a central store (for example, a daily Airflow job storing data in a metadata repository) ensures fresh training data.
Model Training
A gradient boosting model (for example, XGBoost or LightGBM) can rank possible time windows by predicted payment success probability. The model sees each potential time slot as a candidate “arm” to pull. This setup resembles a multi-armed bandit framework, which aims to pick the best action at each step.
When using a multi-armed bandit, the Upper Confidence Bound approach is a common technique. One simplified example formula for the UCB at time t is:
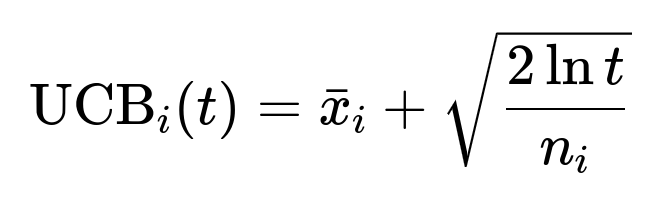
Where:
UCB_i(t)is the upper confidence bound for decision (arm) i at time t.bar{x}_iis the average observed success (reward) when picking arm i in the past.tis the total number of trials so far.n_iis the count of how many times arm i has been chosen.
The system picks the time slot with the highest UCB_i(t) for each retry. Gradient boosting models can also be used to learn these “arms” or time slots by mapping features to success probabilities.
Model Inference and Serving
A separate model-serving infrastructure prevents your main billing service from bloating with dependencies. The billing system sends the relevant customer signals to a prediction service, which runs the model and returns the best time to charge. This approach:
Lowers latency (predictions in milliseconds).
Ensures a clean separation between the payment workflow and ML pipeline.
Example of Model Implementation in Python
import xgboost as xgb
import pandas as pd
# Suppose 'data.csv' has features for 'user_id', 'time_slot', 'features...' and a label 'success'
df = pd.read_csv('data.csv')
X = df.drop(['user_id', 'success'], axis=1)
y = df['success']
# Create a DMatrix for XGBoost
dtrain = xgb.DMatrix(X, label=y)
# Set basic parameters
params = {
'objective': 'binary:logistic',
'eval_metric': 'auc',
'seed': 42
}
# Train model
model = xgb.train(params, dtrain, num_boost_round=100)
# In production, you'd store this model and load it in a prediction service
The code reads a dataset where each row represents a potential “time slot” for retry, along with features describing the user’s payment and usage context. The label indicates success (1) or failure (0) if charged at that slot. The trained model can output a probability of success for each time slot.
Model Monitoring and Maintenance
Set up alerting and dashboards to monitor:
Invoice approval rate: Whether the system is boosting overall successful renewals.
Attempt success rate: Whether individual charges succeed faster.
Prediction latency: Response time from the prediction service.
Data freshness: Timely arrival of new data to retrain models.
Retrain the model periodically to adapt to changing card issuer rules, seasonality, and user payment patterns.
Potential Follow-up Questions
1. How would you ensure data freshness and handle late-arriving data in production?
Data freshness is crucial for accurate predictions. Late-arriving data can skew the model’s understanding of recent payment behaviors.
Answer and Explanation Schedule daily or even more frequent ETL (Extract, Transform, Load) jobs to update the metadata store. Use frameworks such as Airflow to orchestrate these pipelines. If data for a given day arrives late, mark that partition as incomplete and rerun the pipeline. Keep track of data arrival times using timestamps. Train models only on partitions with full data. If partial data is used, monitor for anomalies in model performance.
2. How would you address the cold-start problem when a new user subscribes with no historical data?
A new subscriber has no direct payment history, so the model sees insufficient signals.
Answer and Explanation Use aggregated behaviors of similar segments. For instance, consider location, card type, or brand-level grouping. Initialize new users with global or segment-based defaults. As soon as the user generates usage or payment data, incorporate those signals for personalized predictions.
3. Why might you consider reinforcement learning instead of a simple ranking or classification model?
Reinforcement learning can optimize sequential decisions, rather than a single-step prediction.
Answer and Explanation Machine learning ranking models might treat each retry in isolation. Reinforcement learning can dynamically explore different charge times, learn from successes and failures across multiple attempts, and adapt policies in real-time. This approach is powerful when each decision affects future states or rewards. For example, if the first retry fails, the system continues to update its strategy for the second retry.
4. How do you evaluate and compare the effectiveness of this ML-based solution against the rule-based baseline?
Teams typically measure improvement in payment success rates and user churn.
Answer and Explanation Run a controlled A/B test. Randomly assign a fraction of users to the new ML-based approach, while others stay on the rule-based baseline. Compare:
Invoice approval rate (proportion of subscriptions successfully charged).
Time to successful charge (how quickly the system recovers from failures).
User retention (reduction in involuntary churn).
If the ML system statistically outperforms the baseline, roll out broadly.
5. How would you handle retraining and model decay over time?
Payment behaviors shift due to economic conditions, user growth, or new card standards.
Answer and Explanation Schedule regular retraining. For example, gather recent months of data to create a fresh training set. Monitor key metrics. If you see a consistent drop in performance, trigger an immediate retraining job. Track data drift by comparing distributions of features in production vs. training. Retraining every few weeks or monthly usually balances resource usage and model accuracy.
6. What are the main engineering challenges when integrating an ML model with a high-availability billing system?
Billing systems must be robust and cannot be easily taken down.
Answer and Explanation Keep your ML components decoupled from the billing engine. Host the model in a separate prediction service. Implement circuit breakers for fallback if the prediction service fails or times out. Ensure minimal overhead in data fetching. Guarantee near real-time inference (<300ms) to avoid slowing down payment workflows.