
ML Case-study Interview Question: LightGBM for VM Origin Classification using Heuristics with Limited Labeled Data.


Browse all the ML Case-Studies here.
Case-Study question
A large enterprise wants to identify whether newly created Virtual Machines (VMs) in its cloud platform are truly migrated from on-premises systems or are cloud-native deployments. They lack direct labels for migrated workloads because only a small percentage of VMs are explicitly tagged as “migrated.” They need a classification model to detect which VMs originated on-premises, so they can intervene more effectively for clients who struggle with migration. They also need to reconcile domain knowledge from migration experts, given that most VMs do not have verifiable migration tags. How would you design, build, and deploy a Machine Learning solution to address this classification challenge, while maintaining a feedback loop with business stakeholders to keep refining your model over time?
Detailed solution
Understanding the objective
They want to classify each new VM as either migrated or cloud-native. They have limited labeled data (migrated VMs) and must supplement labels with heuristics and domain knowledge. They also want to track each customer’s migration funnel to identify stuck stages and accelerate progress.
Building the training data
They have only around two to three percent of VMs labeled as migrated. They rely on domain experts for heuristics. For example, older operating system usage might signal a migrated application. These heuristic rules become pseudo-labels and expand the labeled training set. They then validate a subset of these pseudo-labeled VMs with account managers and correct mistakes. They repeat the cycle: refine heuristics, retrain the model, and gather better labels.
Model selection
They experiment with multiple supervised classifiers such as Decision Trees, Logistic Regression, Random Forest, and Light Gradient Boosting Machine (LightGBM). They measure performance on a test set. They consider common metrics such as accuracy, precision, recall, and the Area Under the Receiver Operating Characteristic curve (AUC).
Core logistic regression formula
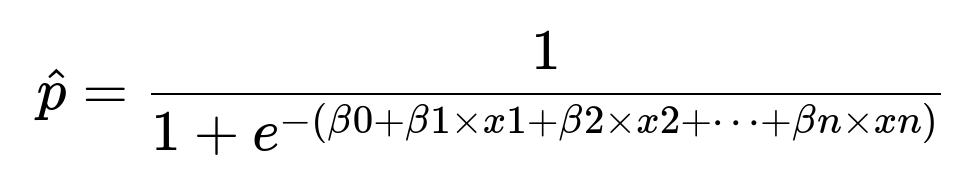
Here:
beta0 is the intercept term.
beta1, beta2, ..., beta n are the learned coefficients for the corresponding features x1, x2, ..., x n.
The output p is the predicted probability that the VM is migrated.
They ultimately settle on LightGBM because it handles large feature spaces and imbalanced data well. They evaluate the model’s AUC, which is near 0.9. They also examine the precision-recall curve, selecting a threshold based on the desired tradeoff between high precision (fewer false positives) and high recall (fewer missed migrated VMs).
Pipeline for labeling and training
They repeatedly label a small portion of new data with refined heuristics. They train or retrain the model on the new labeled data and then send predictions to domain experts for feedback. This iterative approach keeps improving label quality and model performance.
Code snippet example (LightGBM training)
import lightgbm as lgb
import pandas as pd
import numpy as np
# Suppose df_labeled is the DataFrame containing features X and label y
X = df_labeled.drop('label', axis=1)
y = df_labeled['label']
train_data = lgb.Dataset(X, label=y)
params = {
'objective': 'binary',
'learning_rate': 0.05,
'num_leaves': 31,
'metric': ['auc']
}
model = lgb.train(params, train_data, num_boost_round=200)
# Predict probabilities for unlabeled data
unlabeled_X = df_unlabeled
predictions = model.predict(unlabeled_X)
They feed predictions back to the business teams or domain experts, who verify or correct some records and enrich the training data in subsequent iterations.
Deployment and feedback
They deploy the model in a service that flags newly created VMs as “migrated” or “cloud-native.” Account managers can focus attention on high-risk customers with many “migrated” VMs that stall in the funnel. The business sees more accurate tracking of migration progress, better visibility into stalled customers, and faster iteration.
Potential follow-up questions
How would you address data imbalance?
Many “cloud-native” VMs overshadow the “migrated” minority. Stratified sampling can ensure the minority class appears in higher proportion in each training batch. Weights or class-balanced loss functions help. Oversampling (e.g., SMOTE) or undersampling can also address imbalance.
How would you measure success beyond accuracy?
Accuracy might be misleading if most VMs are cloud-native. Precision, recall, and F1-score give a more nuanced view. The Area Under the Precision-Recall curve is useful. Business impact matters, so they can track how many stalled customers they successfully identify and re-engage.
How would you maintain model performance over time?
The distribution of workloads changes. Scheduled retraining is essential. They can automate data labeling from new heuristics and feedback. They can also establish continuous monitoring for data drift and performance metrics drift. Once drift is detected, they trigger a retraining pipeline.
How do you integrate stakeholder feedback?
They hold regular reviews with account managers who validate predictions. They define a procedure to send misclassified or uncertain VMs to a human-in-the-loop interface. They incorporate newly validated labels into the training data. This keeps the model aligned with real-world conditions.
How do you pick a threshold on the precision-recall curve?
They weigh the costs of false positives vs. false negatives. If it is expensive to falsely label a VM as migrated, they might choose a higher precision (even at the cost of recall). If missing a migrated VM has bigger consequences, they push for higher recall. They decide on a threshold that balances these operational tradeoffs.