
ML Case-study Interview Question: Enhancing Vector Search with LLM Re-ranking for Complex Text Queries


Browse all the ML Case-Studies here.
Case-Study question
A data-centric platform has a large dataset of items with descriptive text fields (for example, food items or tourist spots). Traditional vector similarity search returns items close in embedding space but struggles with intricate queries that involve negations or conceptual details (for example, “food with no fish or shrimp” or “exposure to wildlife”). The platform wants a robust search solution that first retrieves a shortlist using vector similarity, then re-ranks that shortlist using a Large Language Model to handle nuances. Propose a detailed solution design for implementing this. Show how to handle embedding generation, vector indexing, query negations, and re-ranking with the Large Language Model. Explain potential performance trade-offs and how you would test its effectiveness on both straightforward and complex queries.
Detailed Solution
Vector similarity search transforms textual entries into numerical embeddings. A popular approach uses an embedding model like text-embedding-ada-002 to generate vector representations. A library such as Facebook AI Similarity Search (FAISS) speeds up nearest neighbor lookups in high-dimensional vector space. A Large Language Model (LLM) such as GPT-4 can re-rank potential matches. First, a shortlist (for example, top 10 or 15) is returned by FAISS. Then, that shortlist and the user’s original query are fed into the LLM to pick the best final matches. This method addresses subtle cues, constraints, or negations in the query.
Core Formula for Cosine Similarity
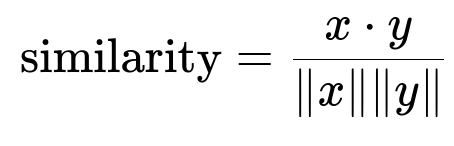
Here, x and y are embedding vectors (for example, dimension d). x dot y is the sum of x_i * y_i over all i. |x| is the Euclidean norm of x, computed as the square root of the sum of x_i^2. |y| is the Euclidean norm of y.
Explanation of the Approach
A search pipeline starts by encoding each data entry into vectors stored in a FAISS index. When a query arrives, it is converted to a vector, and FAISS computes its similarity with the stored vectors. This process quickly returns a shortlist. That shortlist, along with the user query, is passed to the LLM. The LLM re-checks each item’s text, searching for constraints like negation or conceptual matching. It then outputs a refined ranking.
In practice, items with contradictory constraints in embeddings (for example, “do not include fish”) often appear close in raw similarity to items that do contain fish, because negations are tricky for vector space alone. The LLM re-checks each item’s text to ensure items containing fish are excluded if the user specifically requests no fish. This hybrid pipeline usually handles more complex queries accurately.
Example Code Snippet (Python)
import openai
import faiss
import numpy as np
openai.api_key = "YOUR_API_KEY"
# Sample vectors (assume we have precomputed item_vectors using a model like text-embedding-ada-002)
dimension = 1536
index = faiss.IndexFlatIP(dimension) # Using inner product for similarity
index.add(item_vectors) # item_vectors is shaped [num_items, dimension]
# Query embedding
query_text = "food with no fish or shrimp"
query_embedding = openai.Embedding.create(
model="text-embedding-ada-002",
input=query_text
)["data"][0]["embedding"]
query_embedding_np = np.array(query_embedding, dtype='float32').reshape(1, -1)
# FAISS search
k = 15
distances, indices = index.search(query_embedding_np, k)
# Re-ranking with LLM
retrieved_items = [items[i] for i in indices[0]] # The shortlist
prompt = f"""
You are a helpful system. The user query is: "{query_text}".
We have these items:
{retrieved_items}
Return the most relevant 3 items.
"""
llm_response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
ranked_items = llm_response["choices"][0]["message"]["content"]
print(ranked_items)
The code snippet shows the general logic: building an index, generating a shortlist, and re-ranking with an LLM.
How to Test
Comparisons are performed between raw similarity search versus LLM-assisted re-ranking. Complex queries involving negation or conceptual nuance measure how well the final output matches real user intent. Simpler queries (for example, “Japanese food”) can confirm that re-ranking does not degrade obvious results.
Scalability and Latency
LLM calls increase latency and cost. For high-throughput systems, caching or limiting how often the LLM is invoked is important. A smaller shortlist reduces LLM overhead but risks missing edge cases.
Potential Pitfalls
Inconsistent embeddings or low-quality textual fields reduce the accuracy of vector search. The LLM relies on data clarity. If items contain contradictory or incomplete descriptions, re-ranking may fail. Handling negations also depends on correct text representation in the item’s data.
Follow-up question 1
How would you optimize this pipeline for large datasets beyond a few thousand items?
A big dataset can exceed millions of items. FAISS supports various indexing methods for approximate nearest neighbor search that can handle such scale, such as Hierarchical Navigable Small World (HNSW) indexing. Precomputing vectors in batches and storing them in a GPU or CPU-based index speeds up recall. Sharding or partitioning by item categories can reduce the search space. Having a caching layer for frequently repeated queries avoids unneeded LLM calls. Distilling expensive LLM calls into a smaller re-ranking model is another potential optimization.
Follow-up question 2
How do you handle domain-specific queries if the language model is general-purpose?
A domain-specific embedding model or fine-tuning approach can be used if general embeddings fail to capture domain nuances. One might store specialized embeddings alongside general embeddings to see which approach yields better results for a certain query. A retrieval-augmented approach might also enrich prompts with domain definitions or knowledge documents, guiding the LLM to interpret domain-specific terminology.
Follow-up question 3
How would you address privacy and data protection in such a system?
Sensitive content in the dataset must be masked or tokenized prior to generating embeddings. The raw text stored in vector databases should be secured with proper authentication and encryption at rest. If the system relies on a third-party service for embeddings or LLM inference, all data exchanged must be anonymized and any direct personal identifiers removed from the prompt.
Follow-up question 4
What if negations are missed by the LLM in certain contexts?
Difficult negations sometimes confuse LLMs. A mitigation step can parse the query for negations and filter out disqualified entries before or after the re-ranking. For example, if the user says “no fish,” the system can do a keyword-based removal of items containing “fish” from the shortlist. The LLM then ranks the filtered list. This helps correct systematic errors caused by missing or misinterpreted negations.
Follow-up question 5
Why not fine-tune a simpler re-ranking model instead of calling a large model for every query?
A smaller fine-tuned ranking model can be faster and cheaper to run. It can be trained on user feedback or labeled data. However, a large model often handles open-ended or nuanced queries better. If cost is high, a hybrid approach is feasible: a smaller re-ranker for common or simpler queries, and an LLM for critical or complex queries.
Follow-up question 6
How do you ensure the system remains stable if the LLM's outputs are unpredictable?
System stability can be enforced by combining the LLM’s output with rule-based filtering or scoring. If the LLM’s top choice is too far from the user query in embedding space, the system can reject that result and fall back to raw similarity. Another approach is to have a threshold on final similarity or a set of constraints the LLM’s output must pass (for example, item category checks).
Follow-up question 7
How would you measure the success of this approach in an A/B test?
An A/B test would compare a baseline (raw vector search) with the new LLM-assisted pipeline. Key metrics might include click-through rates on returned items, user satisfaction surveys, or time to find the correct result. Queries can be randomly assigned to each variant. If the LLM-assisted approach shows increased relevance and user satisfaction without hurting latency significantly, that suggests success.
Follow-up question 8
What if data quality or item metadata is incomplete?
LLMs or embeddings cannot salvage missing key attributes. A data cleaning step that ensures each item has consistent metadata is often needed. One might fill missing fields from known sources or remove items with insufficient data. Without clean text, embeddings become unreliable, and re-ranking with LLM has minimal context to parse.
Follow-up question 9
Why does cosine similarity sometimes rank items with opposite meaning near each other?
Negation is subtle in embeddings, because the vectors often cluster by topic, not sentiment or negation markers. “I like fishing” and “I do not like fishing” share many overlapping tokens and context. The LLM re-ranking can parse the presence of negation in the textual description to correct that shortcoming.
Follow-up question 10
How would you integrate a knowledge graph into this workflow?
A knowledge graph can store explicit entity relationships. One might combine vector-based retrieval with graph lookups to refine the shortlist. For instance, if the query involves “tourist spots with wildlife,” the system can filter for items labeled as wildlife attractions before the LLM re-ranks. This synergy improves relevance and interpretability by leveraging structured relationships.