
ML Case-study Interview Question: Efficient Video Classification Using Active Learning and Vision-Language Models


Browse all the ML Case-Studies here.
Case-Study question
A media platform needs an efficient way to build video classifiers for their large content library. They must handle complex video concepts and events. They employ domain experts for labeling, but repeated annotation cycles with external teams are expensive and slow. They want a solution that integrates model training with the annotation process, uses large vision-language models for quick searches, and applies active learning to focus on the most challenging cases. How would you architect and implement a system that addresses these constraints, maximizes labeling efficiency, and reduces time to deploy accurate video classifiers?
Detailed Solution
They create a self-service framework that enables domain experts to label examples and continuously refine a classifier through active learning and zero-shot vision-language models. The system has three main steps: search for initial samples, actively refine the classifier, and review annotation quality. Direct user involvement removes handoffs and accelerates model iteration. Below is a detailed breakdown:
Step 1: Searching for initial samples
They use text-to-video search. A large vision-language model encodes both text prompts and video clips into a shared embedding space. Domain experts type queries like “wide shots of buildings,” and the system retrieves matching video segments. This speeds up cold-start labeling because users see relevant clips immediately. No external annotation or data scientist involvement is required.
Step 2: Active learning loop
They train a lightweight binary classifier using the labeled samples. The classifier scores every clip in the library. The system surfaces:
Top-scoring positives
Top-scoring negatives
Confident borderline cases
Random clips
Domain experts label or correct these results. The borderline set reveals edge cases and potential errors. Random clips ensure general coverage. Each labeled round triggers retraining and re-scoring, gradually improving precision. This process repeats until the classifier meets performance needs.
Step 3: Reviewing annotations
All labeled clips appear in a review panel. Domain experts catch mistakes and confirm consistent labels. If they discover new concepts or new edge cases, they can restart at Step 1 or Step 2. This cyclical approach tightens feedback loops and maintains model quality.
Large vision-language model usage
Vision-language encoders enable zero-shot retrieval. This drastically reduces the need for a huge labeled dataset. The classifier then refines results with a smaller supervised set. As a result, labeling overhead goes down while performance improves.
Continuous deployment strategy
After each annotation cycle, the new classifier goes live. Monitoring reveals how it performs on real data. If domain experts spot a drift or an error in production, they label a handful more examples and retrain. This self-service cycle maintains trust and control in the hands of the experts.
Measured performance: average precision
They measure binary classifier quality using average precision (AP). One standard formula is shown below.
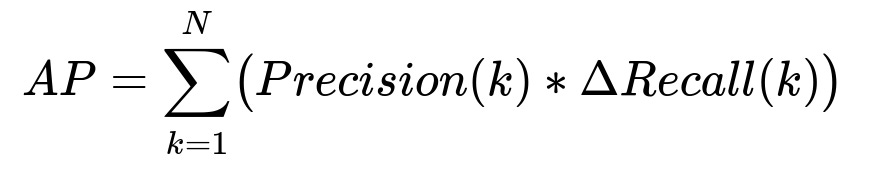
In this formula:
N is the number of relevant clips for a given task.
Precision(k) is the ratio of true positives to total predicted positives at the k-th threshold step.
Recall(k) is the ratio of true positives to total actual positives at the k-th threshold step.
Delta Recall(k) is the incremental change in recall from step k-1 to k.
If AP is too low, they continue adding labeled data or tune hyperparameters. They empirically observe that combining zero-shot retrieval with active learning yields a marked improvement in AP with fewer labeled samples.
Example code snippet for model training
They typically extract embeddings using the vision-language model. They store these embeddings in a feature matrix X. They store labels as y. Then they train a simple classifier:
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import average_precision_score
# Suppose embeddings is a numpy array of shape (num_samples, embedding_dim).
# Suppose labels is a numpy array of shape (num_samples,).
model = LogisticRegression(max_iter=1000)
model.fit(embeddings, labels)
predictions = model.predict_proba(embeddings)[:,1]
ap = average_precision_score(labels, predictions)
print("Average Precision:", ap)
They iterate by adding new annotated samples, retraining, and monitoring AP on a hold-out set or cross-validation.
Follow-up Question 1
How do we efficiently scale text-to-video embedding searches for a very large corpus?
In-depth Answer
Storing embeddings in a vector index is essential. Each video clip embedding is placed in a high-dimensional data structure (for instance, a Faiss index). The system encodes text queries on the fly using the same vision-language model. It retrieves the nearest video embeddings with similarity search. Approximate nearest neighbor methods make searches run quickly even at million-scale. Periodic index updates enable continuous ingest of new content without full re-computation.
Follow-up Question 2
Why do we include a random feed in addition to the highest and lowest scoring examples?
In-depth Answer
Active learning can overfocus on the most uncertain or high/low scoring clips. Randomly sampling ensures coverage of diverse samples that might be skipped by the model’s current confidence boundaries. This reduces model bias. Borderline clips refine the decision boundary, but random clips protect against missing unexpected scenarios.
Follow-up Question 3
What if the user’s textual search terms are too vague or the concept is difficult to express in words?
In-depth Answer
They can label a few example clips manually. The zero-shot embedding still helps by suggesting content visually related to those samples. The user can refine or shift the search based on discovered clips. They can also combine multiple textual searches or synonyms to broaden coverage. Over time, the classifier’s active learning loop further narrows the concept boundaries.
Follow-up Question 4
How do we address potential biases in the annotations or embeddings?
In-depth Answer
Domain experts can systematically audit high-scoring results for unintended patterns. If a subset is misclassified due to biased training data, experts label more examples from that subset to correct it. Random sampling helps reveal potential skew. Monitoring production performance highlights if certain subgroups consistently fail. Extra labeling or domain-aware transformations can mitigate these issues.
Follow-up Question 5
How would we integrate a drift detection mechanism?
In-depth Answer
They log model outputs and track distribution changes in the embedding space over time. Automated alerts fire if prediction patterns shift significantly. Once drift is detected, domain experts sample new data from these shifted distributions, label them, and retrain. Quick iteration cycles keep the production model aligned with evolving content.