
ML Case-study Interview Question: Real-Time Product Embeddings for Enhanced E-commerce Semantic Search


Case-Study question
A growing e-commerce platform wants to improve its on-site product search using real-time machine learning. Consumers frequently search for products, and the platform struggles to interpret the true intent of their queries. The goal is to build a system that understands query context and delivers more relevant product results based on real-time updates to product listings. The platform’s engineering team must design a streaming data pipeline that processes new or updated product images and descriptions at high volume, converts them into meaningful embedding vectors, and immediately makes those embeddings available to a semantic search engine. How would you architect this solution, handle the operational challenges of GPU-accelerated inference in a streaming environment, and ensure low-latency updates for end users?
Additional context
The platform handles millions of embedding computations daily for text and images.
The system must be scalable to accommodate high concurrent loads while keeping latency acceptable for real-time search updates.
Cost-effectiveness is important because each additional millisecond of GPU usage and memory overhead can significantly affect the overall budget.
Detailed Solution
Overview of the Approach
Building a real-time semantic search solution involves generating embedding vectors for text and images in near real time. The embeddings capture contextual information about both the user’s query and the product data, allowing the system to understand potential semantic matches beyond simple keyword overlaps.
Core Mathematical Operation
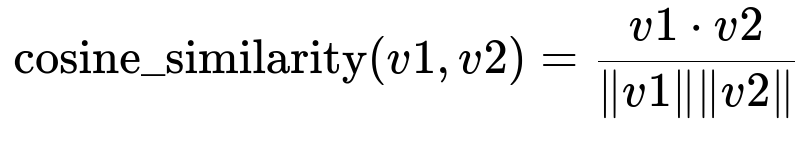
v1 is the embedding vector for the user’s search query. v2 is the embedding vector for a product listing. The dot represents the dot product between the vectors, and the norms in the denominator are the magnitudes of those vectors. Higher similarity scores indicate more relevant product results.
Embedding Generation Pipeline
The pipeline listens to incoming product data changes. Each event triggers a process that transforms the product’s text and images into embedding vectors. A typical implementation involves a Python-based streaming framework, where each process:
Loads or receives the new data (text, image).
Runs a pre-processing step (image download or text normalization).
Passes the preprocessed data to a GPU-accelerated model.
Receives the computed embedding vector.
Writes embeddings to both a data warehouse for offline analysis and a separate topic or service for real-time ingestion into the semantic search engine.
Example snippet (simplified) using a Python streaming framework:
import apache_beam as beam
from apache_beam.ml.inference import RunInference
class ImagePreprocessor(beam.DoFn):
def process(self, element):
# Download and resize image
# Return preprocessed image
yield preprocessed_image
class EmbeddingModelHandler:
def load_model(self):
# Load GPU model
return model
def run_inference(self, batch, model):
# Compute embeddings for each preprocessed image in batch
return embeddings
with beam.Pipeline() as p:
(
p
| "ReadImageEvents" >> beam.io.ReadFromPubSub(topic="product-images-topic")
| "Preprocess" >> beam.ParDo(ImagePreprocessor())
| "ComputeEmbeddings" >> RunInference(
model_handler=EmbeddingModelHandler())
| "WriteEmbeddings" >> beam.io.WriteToPubSub(topic="embeddings-topic")
)
Real-Time vs. Batch Tradeoff
The real-time approach ensures immediate availability of updated embeddings for new products or changes in existing products. This boosts relevance for consumers searching right after a product update. A batch system is simpler but delays new product embeddings, which undermines the freshness of search results. The additional streaming complexity is justified by higher merchant satisfaction and more accurate retrieval of relevant products.
Memory Management on GPU Workers
Large images and concurrent threads can quickly exhaust worker memory. Balancing concurrency and throughput is key. Limiting the number of threads per process can reduce memory pressure, while still keeping the GPU busy. Machines with sufficient GPU and CPU capacity maintain a stable pipeline without frequent restarts. The right combination of machine type, parallel threads, and concurrent model loads ensures that each GPU remains utilized near 100% without hitting out-of-memory errors.
Model Loading and Parallelism
Streaming frameworks often spawn multiple processes on a single worker node to maximize parallelism. Each process may load a separate model instance to GPU memory. This design speeds up total inference throughput but raises memory usage. A single shared model instance reduces memory footprint, yet often leads to slower throughput. In practice, a balanced number of processes or threads, combined with carefully sizing each worker machine, gives a sweet spot of throughput and cost-efficiency.
Batching for GPU Utilization
GPU throughput benefits from batching data. Each data transfer to the GPU imposes overhead, so combining many items in a single batch can increase performance. In a streaming context, batching can increase latency if the system waits to accumulate enough items to form a batch. The chosen streaming framework might try to batch within a bundle or across multiple bundles. If data arrives in bursts, the concurrency from multiple processes can also keep the GPU busy.
How would you handle potential follow-up questions?
What strategies would you apply to keep GPU utilization high while preventing memory issues?
Balancing concurrency and resource usage is crucial. Decreasing the number of threads per worker lowers concurrency but can resolve out-of-memory errors from oversized batch accumulations. If throughput drops, adjusting the worker machine type or the number of workers compensates. A single model instance is easier on memory but can limit parallel inference. Multiple smaller processes, each loading a model instance, can maintain high GPU usage at the cost of higher memory consumption. Fine-tuning this balance involves gradually testing different configurations and monitoring memory and throughput metrics in production.
Why is real-time embedding generation worth the added complexity compared to a simpler batch pipeline?
Consumers expect immediate search relevancy whenever a product changes or a new product appears. Embeddings generated in real-time ensure semantic search sees the most current data. While a batch system might be simpler and cheaper, it delays product updates, degrading search performance and user satisfaction. The near real-time system can increase conversions and user engagement by reflecting product changes immediately, providing a strong return on the added complexity.
How do you scale this pipeline for millions of embeddings per day?
Auto-scaling features in the streaming framework can add workers during traffic spikes and remove them during slow periods. Horizontal scaling across multiple GPU-enabled workers spreads the inference load. Each worker runs a portion of the data stream to stay near peak utilization. The storage and message bus also need adequate throughput. Using a robust pub/sub system with partitioned topics can help distribute the events evenly, avoiding bottlenecks. Monitoring end-to-end latency and GPU metrics helps identify when more workers are needed.
How do you ensure data consistency and reliability in a streaming environment?
Acknowledge messages only once the embedding has been computed and stored. If a job fails before acknowledging, the messaging system replays the event. Schema enforcement prevents malformed data from breaking pipelines. To handle potential duplicates, maintain item timestamps and unique IDs. Duplicate events can be deduplicated at the stream or sink layer. Periodic data quality checks in the data warehouse help reconcile the real-time pipeline’s output with the source-of-truth product database.
Why use similarity metrics like cosine similarity for search relevance?
Embedding vectors capture semantic meaning, and the dot product alone does not normalize for vector magnitude. Cosine similarity is a normalized measure of alignment between two vectors, making it well-suited for textual and visual embeddings. It efficiently highlights items with closely aligned embedding directions. The magnitude of the vectors (caused by differences in word or pixel intensities) matters less than their directional similarity, which directly connects to conceptual similarity.
How does the search engine layer integrate these real-time embeddings?
The search engine listens to new embedding vectors from the pipeline’s output topic or service. It indexes these embeddings alongside the corresponding product identifiers. When a consumer types a query, the query text is converted to an embedding vector in real time. The engine then calculates similarity scores between this query embedding and the product embeddings. Results are ranked by descending similarity score. The pipeline ensures embeddings are continuously fresh, so newly updated products show up accurately.
How would you monitor pipeline performance in production?
Collect metrics on GPU usage, CPU usage, memory usage, and inference latency. Track the number of events processed per second, the backlog in the message queue, and the rate of any failed or retried events. Visual dashboards for resource usage combined with alerting on unusual spikes or drops in throughput help detect issues. Periodic logs of model response time show whether a change in data patterns or model complexity is causing higher latency. Real-time logs of exceptions and OOM errors allow quick troubleshooting.
How do you avoid throughput dips during model version upgrades?
Deploy the updated model instance in parallel and run a small subset of traffic (canary testing) through it. Once stable, gradually shift more traffic. Keep the old model version available until the new version’s performance is confirmed. This approach maintains continuous service and prevents sudden throughput drops from unforeseen model issues. Rolling back is faster if something fails. A well-planned deployment pipeline with robust monitoring ensures minimal service disruption.
Are there best practices for addressing schema changes or model updates?
Maintain versioned schemas and keep older versions in sync for backward compatibility. When the new schema or model version is introduced, add logic that can interpret both versions of data. Gradually phase out older versions after verifying minimal usage. Provide clear version tags in the output streams, so downstream services detect a new version and handle the embeddings accordingly. Stagger the rollout to catch errors before they propagate widely.
How do you incorporate new data modalities, like short videos, into this pipeline?
Extend the existing pipeline to apply a new preprocessor that extracts frame-level or clip-level features. Feed those frames or clips into a specialized embedding model. Generate embeddings in near real time, just like for images and text. Existing design principles remain applicable: load the model on GPU workers, ensure concurrency is tuned for the new data format, and push embeddings to the search index. Monitoring resource needs for larger input sizes or bigger model architectures keeps throughput stable.