
ML Case-study Interview Question: Ranking Real Estate Filters Probabilistically via User Clickstream Patterns


Browse all the ML Case-Studies here.
Case-Study question
A real-estate marketplace wants to help users find their ideal property by suggesting relevant filter refinements. There are almost 50 different filters, such as number of bedrooms, price range, and pet policy. Many filters are hidden within dropdowns, so customers often miss important ones. Management wants a system that ranks the most relevant filters for each user, conditioned on the location they are searching in and on the filters already chosen. This system should capture two key user behaviors: co-occurrence of filters, and sequential revisions where users adjust filter values. Design a solution that uses historical clickstream data to estimate the probability of a future filter selection given the current context, rank those filters, and display them to the user. Provide a detailed machine learning approach, address how to handle data sparsity across regions, and discuss how you would measure performance through experimentation.
Proposed Detailed Solution
Modeling this as a filter-ranking problem involves estimating the conditional probability that a user will select a given filter f_i, given their current set of chosen filters F and the region g. The model can use aggregated user interactions to learn these probabilities.
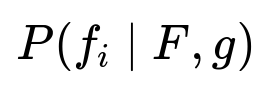
f_i represents a possible filter, F is the set of filters the user has already chosen, and g is the region. The goal is to rank all candidate filters f_i not in F by this probability.
Baseline Co-occurrence Approach
This approach counts how frequently filters occur together. It looks for patterns of the form: “People who use filters A, B, C in region g also choose filter f_i.” The system collects clickstream data showing which filters users selected in the same query, grouped by region. For each region, it computes the number of unique users who selected F ∪ f_i, and normalizes it by the count of unique users who selected F. This gives an approximate probability of choosing f_i next, given F and g. This method is simple and effective for most cases but cannot model the scenario where users revise the same filter multiple times.
Sequential Approach for Filter Revisions
This approach focuses on events when users explicitly change a filter from one value to another. It tracks sequences of the form: “People who use filters A, B, C in region g then switched a filter to f_i.” By looking at the order of filter changes rather than co-occurrence within a single query, it captures user behavior when they revise or tweak filter values. This method needs more data, because sequences are rarer than co-occurrences. Where data is abundant, the sequential approach is preferred. Otherwise, the co-occurrence model serves as a fallback.
Practical Implementation Details
A large clickstream dataset is collected. Each record indicates a region, the set of selected filters, and any filter changes. A pipeline aggregates these events per region. For co-occurrence, it tallies unique user counts for sets of filters. For sequential changes, it tracks transitions from one filter combination to the next. A smoothing strategy prevents zero-probability estimates. A fallback mechanism checks if the sequential approach for region g has enough data; if not, it reverts to co-occurrence. An experiment framework (e.g., A/B testing) is used to measure improvements in user engagement and business metrics such as conversions.
A high-level Python-like snippet might look like:
import pandas as pd
# Assume df has columns: user_id, region, prev_filters, new_filter, event_type
# event_type can be "cooccur" or "seq"
cooccur_counts = {}
seq_counts = {}
for row in df.itertuples():
region = row.region
prev_set = tuple(sorted(row.prev_filters)) # as a canonical key
new_f = row.new_filter
if row.event_type == "cooccur":
# Aggregate co-occurrence counts
cooccur_counts[(region, prev_set, new_f)] = cooccur_counts.get((region, prev_set, new_f), set())
cooccur_counts[(region, prev_set, new_f)].add(row.user_id)
else:
# Aggregate sequential counts
seq_counts[(region, prev_set, new_f)] = seq_counts.get((region, prev_set, new_f), set())
seq_counts[(region, prev_set, new_f)].add(row.user_id)
# Then compute probabilities by normalizing over (region, prev_set).
A/B Testing
The system is deployed to a random fraction of users to observe the impact of the ranked filter suggestions. Key metrics include refinements clicked, time-on-site, saves, and agent contacts. A positive lift in these metrics confirms relevance.
Future Extensions
Data for each property includes hundreds of attributes. Some are never shown as filters. The system can suggest new filters that could matter in specific regions (e.g., presence of a rooftop garden). User feedback from the new suggestions can refine the ranking logic further. Unstructured data (e.g., keywords in descriptions) can also feed into the model. Over time, an end-to-end learning-to-rank approach can replace manual probability estimation.
How would you handle these tricky follow-up questions?
1) How do you address cold-start problems when a new region has few recorded user events?
Set a minimum threshold of user events. Regions that fail this threshold use a fallback heuristic. One fallback is taking the global probability distribution derived from more active regions. Another option is grouping under similar “neighbor” regions. Combining region-based stats with high-level global usage helps address sparse data.
2) How do you decide between co-occurrence and sequential models at scale?
Assess data density in each region. If the event count for sequential changes is too low, use the co-occurrence model. If enough data exists, the sequential approach is used. A weighted ensemble is an option when partial data is available. Regularly recalculate coverage for each region to switch models dynamically.
3) How do you ensure you are not just ranking popular filters but actually personalizing suggestions?
Incorporate the user’s active filters into the probability calculation. The presence of certain filters (like “pet-friendly”) strongly shifts the probability distribution for the next filter. Filter out irrelevant refinements that contradict already-chosen options. Factor in user properties where available, such as if they previously selected large dog–friendly rentals. Also run personalized models that track user-specific patterns if enough data is available.
4) How do you handle potential biases in user clicks, such as users clicking only the top-most refinements?
Account for positional bias by randomizing the order of displayed refinements for a subset of the population. Track whether engagement changes when a refinement appears in different positions. Use inverse propensity scoring or related methods for debiasing. Collect new data that is less biased by ranking position.
5) How do you approach storing and updating probabilities in real time when you have millions of users?
Maintain aggregated statistics in a scalable data store, such as a key-value store with composite keys for (region, filter_set, candidate_filter). Update these counts at regular intervals or use streaming pipelines. Probabilities are recomputed after each batch or streaming window. Caching strategies speed up queries. A specialized noSQL schema or distributed cache can handle the large volume of lookups.
6) How do you measure success beyond click metrics?
Track downstream outcomes like property saves, number of contacts to agents, or completed applications. Compare the distribution of listed properties that users view before and after the new system. Keep track of user satisfaction signals like session duration or completed sessions without bouncing. If these metrics improve, it indicates higher relevance of suggested filters.
7) How can you expand the solution to incorporate unstructured text?
Extract frequent keywords from property descriptions (e.g., “waterfront,” “near university”) and treat them like additional filters. Use click logs on those properties to infer how often users select homes matching those keywords. Integrate these into the same probability ranking framework. Over time, use embedding-based language models to cluster semantically similar property descriptions and generate new “filters” that matter in certain markets.
8) How would you adjust the approach if mobile users rarely interact with detailed filters?
Use a simpler interface that surfaces the most probable few filters. Offer them in a compact UI element or a single scrollable panel. Combine signals from co-occurrence, sequential usage, and device type. On mobile, watch for different engagement patterns. Show fewer, more relevant refinements based on location or frequently used filters. A context-based approach can adapt to typical mobile usage patterns.
9) How do you prevent the model from reinforcing existing biases (like always suggesting the same well-known attributes)?
Randomly explore new or less common filters for a fraction of impressions to gather data about unexplored refinements. Blend exploitation (picking top-ranked refinements) and exploration (adding less popular but potentially relevant attributes). Track performance of these attributes and adjust the ranking logic to avoid stagnation.
10) How do you troubleshoot a drop in user engagement following a new model release?
Compare user cohorts served by the new model vs. the old model. Investigate feature distributions and ensure no major data pipeline break occurred. Analyze region-level performance. If the decline is region-specific, the fallback logic or model coverage might have changed. Examine logs for abnormal patterns. Roll back to the previous version if needed and debug with offline replays and small-scale tests.