
ML Case-study Interview Question: Three-Tower Deep Learning for Fresh, Calibrated Ad CTR Prediction.


Browse all the ML Case-Studies here.
Case-Study question
You are leading an ads platform that runs auctions to select which ads to display to users. The goal is to implement a new click-through rate prediction system built on a three-tower deep learning model. The first tower is a deep multilayer perceptron that captures full interactions between user, ad, and context features. The second tower is a wide linear layer that tracks memorization signals from sparse identity features such as ad IDs. The third tower is a shallow linear layer over the same generalization features as the deep tower, aiming to help with output calibration. The existing baseline model is a linear system that has been heavily optimized, and the new approach must provide better relevance without compromising the monetization objective. The monetization objective is often modeled with an Expected Cost Per Click formula, shown below, where pCTR is the predicted click-through probability and biddingPrice is the amount advertisers pay if users click:
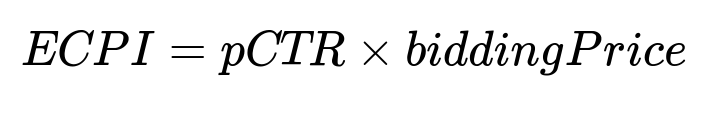
However, unlike many standard ranking systems that only require strong relative ordering, your ads platform needs the predicted probability to match the observed probability of click (oCTR), so that advertisers are neither overcharged nor undercharged. You also need to handle rapidly arriving new ads and shifting trends in ad performance, which requires partial re-training of the memorization component with fresh data on an hourly basis. The deep and shallow parts can be re-trained at a slower daily frequency.
Design the final solution that provides full user-ad-context interactions, keeps memorization features fresh, and prevents over-prediction. Explain how you would architect the system, handle partial re-training, and address calibration challenges caused by exposure bias (the fact that only the highest-ranked ads get shown in the system). Propose a strategy for collecting representative training data and outline how you would use it to ensure that predictions remain well-calibrated under continuous distribution shifts.
Solution
System Architecture and Core Logic
The system stacks three main components. The deep tower is a multilayer perceptron that ingests user, ad, and context features. Those features are first projected into dense embeddings, then passed through several fully connected layers for complete interaction. The wide tower is a linear model that processes sparse identity signals such as ad IDs, advertiser IDs, or other entity IDs, letting the model quickly memorize historical performance patterns. The shallow tower is a linear model that processes the same generalization features as the deep tower, except for certain sensitive or bias-inducing features (like position) excluded from the deep part. The outputs from the three towers are summed and passed through a sigmoid activation, then optimized under a cross-entropy loss:
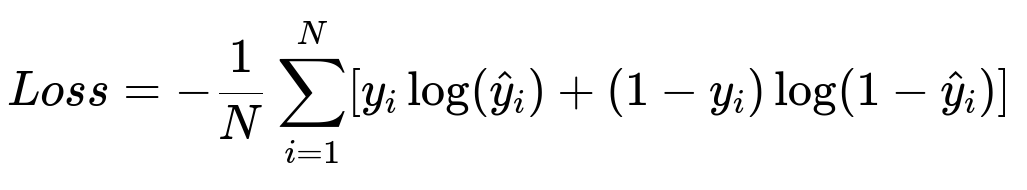
Here y_i indicates the ground-truth click label (1 for click, 0 for no click), and hat{y}_i is the model’s predicted probability. The model’s final probability is pCTR. The deep tower provides rich cross-feature interactions. The wide tower captures memorization from sparse IDs and can be re-trained quickly. The shallow tower helps mitigate overconfidence issues by resembling a linear residual block that softens the final probability distribution.
Frequent Partial Re-training of the Wide Tower
Frequent re-training of the memorization layer is key. The memorization features, such as ad or advertiser IDs, need fast updates to avoid stale parameters when new ads and advertisers appear or when existing ads shift performance. The daily full re-training is done for the deep and shallow towers to capture broader patterns. After that, their parameters remain frozen while a fresh wide tower is trained hourly on new data. In each iteration, the system infers the partial score from the frozen deep and shallow towers and records it as a “cold-start offset.” That offset, plus new memorization features (recent performance data), are used to re-train or warm-start the wide tower. This process is fast because only the wide tower is updated.
Below is a conceptual Python-like snippet for partial re-training:
# partial_retraining.py
import numpy as np
# Suppose we have new_dataset with the same columns plus a cold_start_offset
# wide_features is the set of sparse ID features
# offset_column holds the deep+shallow score from the frozen towers
def train_wide_tower(new_dataset):
# Extract features and labels
wide_X = new_dataset[wide_features] # e.g., ad_id, advertiser_id
offset = new_dataset['offset_column'] # cold-start offset
y = new_dataset['label']
# Combine offset into wide input or treat it as a fixed intercept
input_for_wide = np.concatenate([wide_X, offset.reshape(-1,1)], axis=1)
# Fit a linear model or run gradient descent
# This example uses a pseudo gradient step for illustration
# In practice, you would use your ML framework's solver
model_params = gradient_descent(input_for_wide, y)
return model_params
# Typically run once per hour with newly arrived data
latest_data = fetch_hourly_data()
wide_tower_params = train_wide_tower(latest_data)
save_params_to_production(wide_tower_params)
The result is a quick update that captures fresh memorization signals without touching the rest of the network. This ensures that if a new ad performs differently than older ones, or an existing ad’s performance drifts over time, the system can catch that change promptly.
Handling Calibration and Over-prediction
Deep neural networks often produce probability distributions that skew higher than the true click probability. A standard post-training calibration method, such as isotonic regression, might fail if the model sees online data different from the offline data used to fit the calibration curve. Over-prediction can be especially problematic in ads because higher pCTR can overcharge advertisers. Adding the shallow linear tower, which captures a more stable and less overconfident mapping, improves the final probability distribution. The result is a composite of a deep MLP path and a linear path, making the model less overconfident than a purely deep approach.
Exposure Bias Problem
A major challenge arises because the system only collects training data on ads that were shown to users. The set of shown ads depends on the model’s own pCTR predictions and the associated bids. The training data distribution is thus skewed if the online ranking model is different from the one that created the offline data logs. The new model might see a different distribution of user-ad interactions once deployed, leading to hidden over-prediction or under-prediction that isotonic regression cannot fix. The strategy is to collect logs from a fraction of online traffic already served by the new model. That fraction can be small at first so as not to disrupt the whole platform. The newly created dataset—collected from the new model’s own decisions—gradually builds a more representative offline set. Re-fitting the calibration on that data reduces over-prediction. Over time, as the new model’s traffic fraction grows, the data distribution stabilizes, and the calibration error shrinks.
Position Feature and De-biasing
Position is a known bias factor for ads CTR. The system might have a more favorable or unfavorable prediction for certain positions, but the ads pipeline might not have that position feature available at scoring time. Feeding that feature into the deep tower can exacerbate overconfidence. Excluding the position feature from the deep tower while using it in the shallow tower keeps the deep interactions from incorporating spurious position effects. The shallow layer can apply a direct linear adjustment based on position without letting it bleed heavily into the deeper layers.
Final Steps for Deployment
Rolling out the new system involves simultaneously introducing the three-tower neural network, partial re-training for memorization, and a robust calibration strategy. A slow ramp of traffic to the new model allows the system to gather logs that reflect actual online distribution. The calibration module then re-fits to that dataset, closing the gap between the predicted probability and the observed rate of clicks.
How would you handle the transition from the old baseline model to the new three-tower model without risking large financial loss?
Collect a small percentage of impressions served by the new model while the old model handles most traffic. Estimate calibration error and financial impact on that sample. Re-fit any calibration or post-processing modules. Incrementally raise the traffic share of the new model. Monitor key metrics for undercharging or overcharging. Stop or roll back if any large anomaly surfaces.
Why is partial re-training restricted only to the wide tower?
Re-training every tower frequently is computationally expensive. The deep tower consumes heavy features and must run expensive embedding lookups and dense MLP computations. Freezing it and only updating the linear wide tower with sparse ID features is faster. That partial re-training approach ensures up-to-date memorization of each ad's performance, while the slower deep re-training captures broader cross-feature interactions at a daily cadence.
How do you ensure that the shallow tower mitigates overconfidence?
The shallow tower is a linear layer attached to the same inputs as the deep tower, except for certain bias-inducing features. The final prediction is the sum of the shallow output and the deep output. This architecture mimics a residual approach where the deep network models the more complex residual and the shallow network captures straightforward linear effects. That combination often shows lower calibration error than purely deep outputs, since purely deep architectures can produce sharper probability distributions.
How do you correct calibration when exposure bias skews the training data?
Serve a portion of requests with the new model so that exposed ads reflect the new model’s decision boundary. Collect those impressions and outcomes in offline logs. Train or adjust your calibration component on that data. Gradually increase the traffic share. This iterative process improves calibration on the new distribution of shown ads, rather than on the old baseline data.
How would you handle new advertisers who do not yet have historical metrics?
The wide tower’s memorization features might not be applicable to brand-new ads or advertisers with zero history. Use a cold-start offset from the deep and shallow towers. They capture generalized user-ad-context interactions without relying on that memorization. As the new advertiser gathers impressions and clicks, partial re-training in the wide tower picks up any emerging patterns.
How can you avoid performance bottlenecks in this architecture?
Efficient serving requires specialized infrastructure that can quickly run the deep and shallow towers within tight latency constraints for ads auctions. Precomputing and caching embeddings for frequent users or caching partial MLP outputs can reduce inference load. Parallelizing the wide layer lookups with a high-throughput storage solution further ensures speed. Monitoring GPU or CPU utilization and scaling horizontally might be necessary.
Why is a deep tower with complete feature interaction superior to a single embedding-based approach?
A single embedding-based approach might only focus on user-specific or ad-specific embeddings. That approach only captures partial signals and lacks the ability to combine user, ad, and context features on the fly. A full end-to-end deep network learns interactions among all features simultaneously, including context signals. That synergy often yields significant accuracy gains over simpler embeddings appended to a linear baseline.
Could we remove the shallow tower if we fix calibration with advanced methods like temperature scaling?
In practice, advanced calibration methods can help, but a shallow linear tower can still mitigate overconfidence by blending a simpler linear path with the deeper nonlinear path. It also has less computational overhead than repeated advanced calibration iterations. Empirical tests often show that combining a shallow tower with a deep network is simpler to tune and robust in terms of calibration.
How does the pCTR x biddingPrice objective change CTR prediction design?
It forces the model to produce not only a correct rank ordering but also a probability that aligns with real click likelihood. Overestimating or underestimating pCTR alters the product pCTR x biddingPrice and risks misalignment between actual cost and the expected cost. That risk is critical in an ads platform because it ties directly into revenue and advertiser satisfaction.