
ML Case-study Interview Question: Spark-Powered Association Rules for Scalable Retail Co-Buy Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A major retailer with a large product catalog wants to scale product recommendations by analyzing millions of historical shopping transactions from both online and in-store channels. Each department in the product hierarchy must yield curated product pairs that are co-purchased, with the aim of suggesting additional items to customers. You are asked to design a scalable recommendation system that extracts these co-buy relationships and provides output in real time. The retailer wants robust rules that capture frequent purchases and also emphasize high-revenue products. Explain your approach in detail, propose the end-to-end solution architecture, address memory and performance constraints, and show how you would handle new items that have no purchase history.
Please formulate your plan step by step. Show the data processing stages, the mathematical approach for identifying strong co-purchase relationships, the distributed computation framework, and how you would validate and deploy your recommendations at scale.
Detailed Solution
Data Gathering and Hierarchical Segmentation
Pull transactional data from all sub-departments, considering store and online channels over a fixed period. Organize products into divisions, departments, categories, and subcategories. Identify the relevant time window to ensure enough transactions for robust patterns.
Data Preprocessing
Filter out transactions with only one product. Remove items bought too infrequently or too frequently to avoid noisy signals. Include a price or revenue-based threshold to keep expensive but infrequent products that can boost profitability.
Core Mathematical Concepts
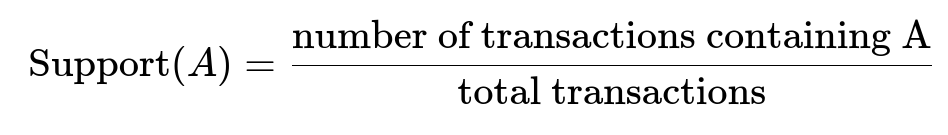
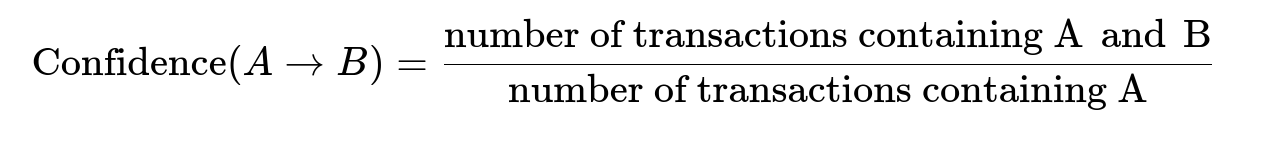
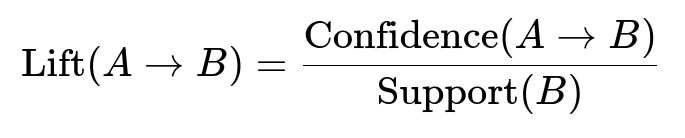
For each pair of items A and B, Support(A) is the frequency of A in all transactions. Confidence measures how often B occurs when A is present. Lift indicates how much more likely A and B are to be purchased together compared to random chance.
Model Construction
Two approaches:
Frequent Pattern Growth (FP-Growth): Uses distributed computations to derive frequent itemsets and generate association rules. Minimum support and minimum confidence parameters filter out weak rules. This approach considers multi-item rules but can be computationally expensive with large volumes.
Probability-Based Co-Occurrence: Focuses on pairs (A, B) only and calculates how often B appears with A. Eliminates higher-order combinations to achieve lower complexity from O(n^n) to O(n), where n is the mean item count in a basket. This smaller scope can be more scalable across departments.
Validation of the Recommendations
Generate hundreds of thousands of co-buy pairs. Sort by the most relevant metrics (confidence, lift, revenue contribution). Compare short-term vs. longer-term windows to see stability of rules. Examine whether these recommendations match intuitive product relationships.
Distributed Processing and Workflow Scheduling
Use PySpark on a cluster. The driver program coordinates tasks. Worker nodes handle the bulk of data transformations and model computations. Prepare Airflow or a similar scheduler to run these batch jobs across multiple sub-departments in parallel. Merge final outputs into a master table, partitioned or clustered by super-department. End-to-end execution should be timed and monitored for performance, typically requiring a few hours to handle billions of records.
Cold-Start Items
New items with limited data cannot rely on co-purchase patterns. Incorporate product attribute-based similarity (shared category, brand, or features) to initialize suggestions until enough transactions accumulate.
Practical Python Implementation Notes
Use Spark’s built-in FP-Growth:
from pyspark.ml.fpm import FPGrowth
fpGrowth = FPGrowth(itemsCol="items", minSupport=0.001, minConfidence=0.1)
model = fpGrowth.fit(transaction_data)
freqItemsets = model.freqItemsets
associationRules = model.associationRules
Or write your own logic for probability-based item pairs:
# Pseudocode
paired = transaction_data \
.flatMap(lambda basket: generate_pairs(basket)) \
.map(lambda pair: (pair, 1)) \
.reduceByKey(lambda a,b: a+b)
total_counts = ...
# Then compute co-occurrence probability:
pair_prob = paired.mapValues(lambda count: count / total_counts)
Adjust thresholds, minSupport, minConfidence, or probability cutoffs depending on each department’s purchase distributions.
What techniques would you use for performance tuning in a large-scale Spark environment?
Adjust the partitioning strategy so data is evenly distributed across worker nodes. Cache frequently used dataframes in memory if repeated across transformations. Increase executor memory and shuffle partitions for large joins or aggregations. Use broadcast joins when one dimension is small enough. Regularly monitor job execution with Spark’s web UI to identify skewed partitions or unnecessary shuffles.
How would you ensure meaningful recommendations instead of trivial pairs?
Apply maximum support thresholds to eliminate overly common items that do not add value. Use price or revenue-based filters. Combine confidence and lift to find pairs that truly stand out. Check cross-category or cross-department pairs that meaningfully boost basket size rather than pair items that are commonly purchased together by default.
How do you handle item bundling for promotions with these rules?
Map each recommendation pair to potential promotions. Bundle items that appear in strong association rules and yield high incremental revenue. Consider the highest confidence pairs first. Then run A/B tests to measure lift in actual baskets.
Why might you still consider multi-item relationships?
Certain categories (like meal kits) can require bundles of more than two items. If the domain calls for 3-item or 4-item combinations, you might revert to FP-Growth for multi-item sets. Probability-based two-item logic will miss those multi-item relationships.
How would you adapt your approach for near real-time recommendations?
Stream transactions to a structured streaming system. Maintain incremental counts of item co-occurrences. Update the frequency metrics in small batches. Periodically refresh an online store of recommendation rules. Use approximate streaming algorithms to handle extremely high data throughput.
How would you validate performance on new sub-departments never seen before?
Run offline back-tests, measuring the accuracy of recommended pairs on historical data. Compare predicted co-purchase pairs vs. actual future purchases. Observe any changes in buying patterns and tune filters or thresholds. Possibly gather user feedback or run small-scale experiments to confirm that recommendations remain relevant.