
ML Case-study Interview Question: Real-Time Grocery Availability Prediction: Scaling Gradient Boosting with Mean Encoding


Browse all the ML Case-Studies here.
Case-Study question
A rapidly growing online grocery aggregator wants to predict the real-time availability of more than 200 million items across thousands of stores. Each item is defined by a product identifier, store identifier, brand, department, and other metadata. Orders flow in continuously, and in-store shoppers sometimes mark certain items as “not found.” The aggregator does not control store inventory. They rely on a daily batch feed from retailers plus real-time signals from shopper scans. They want a predictive model that updates every hour to score each item’s likelihood of being found in-store. How would you build and deploy a system to achieve high-accuracy real-time availability predictions at massive scale?
Detailed Solution
Overview of the modeling approach
Construct a binary classification model predicting whether an item will be found in-store. Label items marked “not found” as 0 and items scanned successfully as 1. For each item-hour combination, generate a probability score that indicates the likelihood of that item being available in a given store at that time.
Key predictive features
Extract features in three main categories:
Item-level features from historical found/not-found patterns. For instance, time since last not-found event, item’s long-term found rate, and time since last successful find.
Time-based features indicating day of week and hour of day. Early mornings might show higher restocked availability while late nights can have depleted shelves.
Mean-encoded categorical features for high-cardinality attributes (brand, product, store, region). Instead of one-hot encoding or embeddings, convert each category to its historical found rate, which yields continuous values that capture the underlying availability patterns.
Core classification objective
Many implementations use gradient-boosted trees (like XGBoost) for classification. They optimize an objective combining logistic loss with regularization on the additive trees.
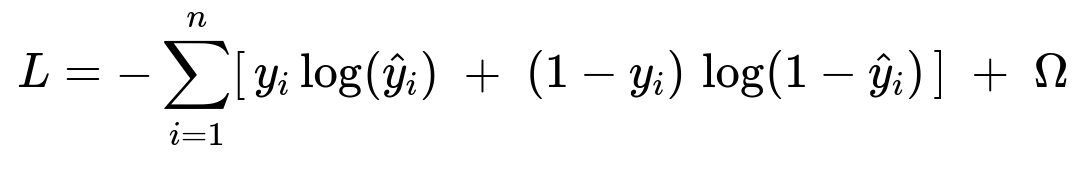
Where:
n is the total number of training samples.
y_i is the ground truth label (1 if found, 0 if not found).
hat{y}_i is the model’s predicted probability that the item is found.
Omega is the regularization term penalizing model complexity.
Handling the tail of rarely ordered items
Many items have minimal sales data. Mean-encoded features help these items because they share broader product or store attributes with better-known items. When the sparse item does not have its own solid history, aggregated found rates from related groups provide strong signals.
Large-scale scoring and architecture
Every hour, score hundreds of millions of item-store pairs. Move heavy feature engineering to a data warehouse layer for efficient joining and precomputation. Cache static features that do not change frequently. Use parallelized Python-based inference to generate predictions. Write scores back to a fast-access data store. This pipeline must be optimized to handle high throughput while finishing in minutes.
Use cases of the predictions
Hide items with low availability scores, recommend replacements, and possibly direct orders toward locations with higher stock. This improves the experience for customers, reduces shopper frustration, and increases overall efficiency.
Python example for inference pipeline
import xgboost as xgb
import pandas as pd
def load_features():
# Load precomputed features from data warehouse extracts
# Return as a Pandas DataFrame
pass
def score_batch(model, features_df):
dmatrix = xgb.DMatrix(features_df)
predictions = model.predict(dmatrix)
return predictions
if __name__ == "__main__":
model_path = "xgboost_item_availability.bin"
model = xgb.Booster()
model.load_model(model_path)
features_df = load_features()
scores = score_batch(model, features_df)
# Store or publish scores for downstream applications
Explain in short paragraphs that large-scale parallelization can be done with Spark or Ray if the scoring dataset is huge. Make sure to optimize data transfers and concurrency.
How would you handle items that appear unexpectedly or change distribution over time?
Explain that many items might be newly introduced or discontinued. Maintain a rolling update schedule for the model. Recompute the mean-encoded rates frequently so new items eventually develop relevant metadata statistics. If items are discontinued, they naturally get a decreasing found rate and predictions drop.
How would you address overfitting, especially for items with extensive historical data?
Explain using early stopping based on a validation set. Use regularization parameters in XGBoost (gamma, lambda) to avoid overly complex trees. Keep track of performance metrics (AUC or log loss) on a hold-out set. Monitor drift in predictions across different stores or item categories.
Why choose mean encoding over embeddings for categorical variables?
High-cardinality embeddings can blow up training data size and require enough observations per category for good representation. Mean encoding is simpler, runs faster, and captures a direct signal of how likely items in each category are found. Regularize it by smoothing to avoid overfitting small categories.
How do you manage the real-time update frequency for predictions?
A strict hourly or half-hourly pipeline can keep predictions fresh. Whenever a shopper marks an item as not found, that event quickly adjusts item-level features, which lowers the predicted probability. Cache partial aggregates in memory or an efficient key-value store for faster updates, and recalculate probabilities incrementally.
Could a deep learning approach handle this scale?
In principle, yes, but a tree-based solution combined with mean encoding handles sparse data and high-cardinality features more cleanly. Deep approaches could be tried, but the engineering complexity might be higher, and it may not offer a significant advantage over well-tuned boosting at this scale.
Why is efficient parallelization crucial for this problem?
Hundreds of millions of items must be scored every hour. Slow feature extraction or model inference would not finish within the time window. Partition the data, run parallel processes, and reduce overhead on data transfers. Tune concurrency to minimize resource cost while meeting strict latency deadlines.
How would you measure the success of this availability prediction system?
Compare predicted probabilities against actual found/not-found rates. Log loss or AUC measure how well the probabilities separate found from not-found outcomes. The business impact is also key: improved fill rates, fewer replacements, higher customer satisfaction, and shorter shopping times for in-store pickers.