
ML Case-study Interview Question: Cross-Lingual Video Classification with Multilingual Embeddings


Browse all the ML Case-Studies here.
Case-Study question
You are given a large video-hosting platform with content in more than 20 languages. The platform already uses a deep learning pipeline that classifies videos into main categories using textual metadata, but this system works only for English and French. The company wants to extend this classification to other languages without investing heavily in manual labeling or external translation services. How would you build and deploy a cross-lingual solution to categorize videos from various languages, relying on existing English and French training data?
Detailed solution
Overview
This problem is about Transfer Learning for text classification across different languages. Training from scratch for each language is costly. Building one model for English and French, then reusing that knowledge for other languages is more efficient. Multilingual embeddings can align textual data across languages into a common vector space. Feeding these vector representations to a classifier helps the model predict categories for languages never seen in training.
Multilingual model choice
Several pre-trained multilingual models exist, such as m-BERT, XLM, and MUSE. Each provides different trade-offs for cross-lingual tasks. m-BERT and XLM often perform well on a wide range of NLP tasks but can be resource-intensive. MUSE emphasizes aligned embeddings for diverse languages, which is especially helpful for zero-shot classification. Simpler embeddings that align semantically similar texts across languages often yield better cross-lingual transfer performance with lower computational overhead.
Architecture
Pass the textual metadata (title, tags, description) through a multilingual embedding model to get a single vector representation. Feed this embedding to a feed-forward neural network (two Dense layers, a Batch Normalization layer, and a Dropout layer) that produces category probabilities.
Simple example code snippet
import tensorflow as tf
import numpy as np
# Suppose embed_text is a function wrapping MUSE inference for text
def embed_text(text):
# Hypothetical function returning aligned multilingual embedding
return np.random.rand(512) # placeholder for an actual embedding
# Build a small classifier
input_layer = tf.keras.Input(shape=(512,))
x = tf.keras.layers.Dense(256, activation='relu')(input_layer)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(0.5)(x)
x = tf.keras.layers.Dense(128, activation='relu')(x)
output_layer = tf.keras.layers.Dense(num_categories, activation='sigmoid')(x)
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='binary_crossentropy')
# Example training loop
train_embeddings = [embed_text(text) for text in train_texts]
train_embeddings = np.array(train_embeddings)
train_labels = np.array(train_labels)
model.fit(train_embeddings, train_labels, epochs=5, batch_size=64)
Explaining this: Train the final classifier by converting each training sample (English or French text) to an aligned embedding. Use binary cross-entropy loss because multiple categories may apply. After training, feed new-language samples into the embedding model, then send that embedding into the classifier.
Why not translate everything
Translating all foreign text to English can be expensive. Existing multilingual embeddings reduce costs. Training once on English and French text, then reusing these embeddings for other languages makes the approach scalable. Accuracy can be high if the embedding model effectively aligns semantically similar sentences across languages.
Performance measurement
Assume the primary metric is top-1 accuracy. This indicates how often the highest-confidence category matches the ground truth label for each video.
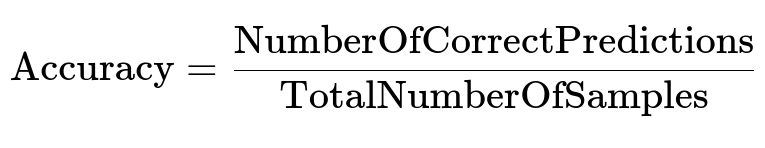
"NumberOfCorrectPredictions" is how many times the classifier's highest-scoring category matches the true category. "TotalNumberOfSamples" is the total videos tested. Multilingual embeddings that properly align text from different languages help maximize this score.
Practical considerations
Use the same text preprocessing for all languages to keep the input consistent (lowercasing, special-character handling). Expect domain mismatches where some languages focus on different topics than English or French. Fine-tune or calibrate the classifier if certain languages produce skewed distributions. Deploy the final pipeline so that each newly uploaded video passes through the embedding model and classifier. The system returns categories in real time or near real time.
Follow-up question 1
How do you handle short or noisy textual metadata, such as tags with abbreviations or misspellings?
Answer and explanations Short and noisy text can degrade embedding quality. Using robust text preprocessing for special characters and repeated letters helps reduce errors. Splitting hashtags into separate tokens might help. If tags are too short or not meaningful, consider fallback approaches: expand the text by appending available descriptions, or combine tags from the channel that owns the video. A multilingual model trained on diverse data (including casual language) handles some irregularities, but explicit normalization steps often improve results.
Follow-up question 2
How do you deal with situations where new languages have a unique semantic distribution that differs significantly from English and French?
Answer and explanations This situation arises because the alignment learned from English and French might not capture new language nuances. Creating a small labeled dataset for the new language and fine-tuning the classifier can mitigate domain mismatch. Injecting a few real samples from that language helps the classifier adapt. Another approach is using unsupervised domain adaptation techniques that re-align the embeddings for the new language distribution. Monitoring performance metrics on representative subsets ensures the model does not degrade when exposed to unfamiliar linguistic patterns.
Follow-up question 3
How do you ensure that your final cross-lingual model generalizes well in production for many unseen linguistic variations?
Answer and explanations Maintaining generalization requires regular re-evaluation. Periodically sample new videos from multiple languages and measure accuracy. Track performance drift over time. Retraining the final classifier on fresh data addresses changes in language usage or video topics. Monitoring user feedback, watch-time patterns, or content popularity by region also gives signals if the categorization is shifting. A modular design where the embedding model is swappable helps in updating to improved multilingual encoders without rewriting the entire pipeline.
Follow-up question 4
How would you extend this architecture to incorporate visual signals if the textual metadata is missing or insufficient?
Answer and explanations Extracting features from video frames or short clips provides additional context. Computer vision models pretrained on large datasets can encode visual information into embeddings. Concatenate these visual embeddings with the text embeddings if available, or rely solely on visual features when text is unavailable. Train a fusion network that ingests both types of embeddings. Deploying a hybrid approach improves coverage for videos where text is sparse or inaccurate.
Follow-up question 5
Why might a simpler CNN-based multilingual model outperform a more complex Transformer-based model for your zero-shot classification task?
Answer and explanations Large Transformer-based models capture intricate patterns but are heavier in computation and sometimes less aligned for purely zero-shot classification. A CNN-based model like MUSE focuses on aligning embeddings across multiple languages, yielding consistent representations for semantically similar text, which is essential for zero-shot inference. Empirical tests often reveal that simpler aligned embeddings outperform heavier models for this specific cross-lingual classification, especially when speed and cost are priorities.
Follow-up question 6
What are key steps to deploy and monitor this multilingual classifier in a production environment?
Answer and explanations Steps start with packaging the embedding model and the final classifier in a reproducible container. Integrating the pipeline in the platform’s upload process ensures newly added videos are categorized automatically. Logging the classifier’s confidence scores, input language, and predicted categories is critical for analytics. Setting up monitoring and alerting for sudden changes in data distributions or drastic drops in accuracy is also necessary. Periodically retraining on fresh data addresses language drift and ensures continued relevance.