
ML Case-study Interview Question: Scalable Half-Hourly Food Delivery Forecasting with Python, Dask, and Time Series


Browse all the ML Case-Studies here.
Case-Study question
You are leading a Data Science effort at a nationwide food delivery platform. The business requires accurate order volume forecasts for each half-hour time block in every region over a multi-week horizon. Demand fluctuations affect how many couriers to schedule in advance. Too few couriers cause delays, and too many couriers cause financial losses. Design a complete end-to-end system to generate daily forecasts at scale. Address the technical architecture, data pipeline, distributed computing framework, research-to-production handoff, and strategies to ensure forecast reliability. Suggest the modeling approaches and explain how you would implement them, then describe your plan for monitoring, versioning, and fallback if a forecast fails.
Detailed Solution
System Overview
A Python-based pipeline works best for scalable model research and production. Python is already a standard in machine learning and offers convenient libraries for data manipulation and modeling. Data is housed in a central datalake. Each day, new data arrives with the previous day’s orders. The pipeline must transform these raw data sources into the required features, train or update the models, and then produce forecasts for every region and every half-hour timeslot.
Research and Production Alignment
Data scientists often serve as machine learning engineers. They maintain quality across both research and production code to avoid duplicate implementations. This practice ensures that a prototype model written in Python can be deployed without rewriting it in another language. Code is kept in a shared repository, with robust version control and automated testing.
Data Pipeline
Historic order data per region needs to be aggregated to daily features. Regions can be redefined over time, so each forecasting run reconstructs feature histories for the current region layout. This reconstruction is computationally expensive, so it is done on a daily schedule once the prior day’s final data is available. The dataset is then cached, making local research simpler.
Distributed Computation with Dask
Thousands of forecasts must be generated daily across multiple models and hundreds of regions. Local testing can run on a small sample, then scale out to the full workload on a cluster. Dask running on YARN handles parallelization. Each region-model combination is an independent unit of computation. Dask dynamically schedules these tasks to different workers. Switching between local CPU testing and full-cluster deployment requires only changing command-line parameters.
from dask.distributed import Client
client = Client() # Connect to Dask scheduler on YARN
def forecast_region(region_data):
# Train or load model here
# Generate forecast
return forecast_result
regions = [...] # List of region identifiers
data = {...} # Dictionary mapping region -> input data
futures = []
for region in regions:
futures.append(client.submit(forecast_region, data[region]))
results = client.gather(futures)
# results now contains forecasts for all regions
Model Approaches
ARIMA-based methods, gradient boosting, or deep learning can be applied. Some time series models incorporate seasonality, trends, and external factors. One such example is an ARIMA variant with exogenous variables. A simplified version of the ARIMA(p, d, q) equation is shown below.
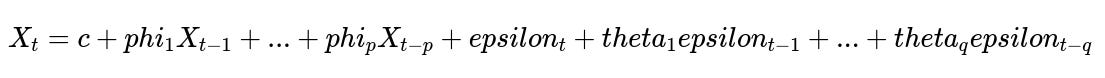
Where:
X_t is the value at time t (the order volume for a region and timeslot).
phi_i are autoregressive coefficients.
theta_j are moving average coefficients.
c is a constant.
epsilon_t is white noise at time t.
Exogenous variables can include weather, promotions, local events, and holidays. These help the model capture external demand shifts.
Quality Assurance
The pipeline checks for invalid outputs. Negative or zero forecasts over long intervals indicate potential errors. Forecasts are compared day-over-day to catch sudden outliers. Simple average-based backup forecasts provide a fallback if a primary model fails or produces anomalous outputs. Alerts are configured to flag abnormal forecasts.
Monitoring and Alerting
Logging and monitoring track run times and resource usage. Automated alerts fire when runs exceed expected times or memory limits, or when forecasts deviate too much from historical baselines. Results are also pushed to a dashboard for stakeholder oversight. This setup ensures immediate investigation when issues occur.
How do you handle drifting region boundaries?
Regions can merge or split due to business needs. The daily pipeline reconstructs each region’s entire history after these boundary changes. This re-aggregation process sums up the historic orders or reassigns restaurants to their updated region. Research code is designed to read these re-aggregated features so that the same logic is used for model training and for daily prediction, preserving consistency.
Accurate mapping from old to new region definitions is critical. Archival metadata tables store when each restaurant changes region. The pipeline joins these tables to ensure the final dataset aligns with the current day’s region layout.
How do you validate the accuracy of your forecasts?
An internal evaluation framework compares forecast vs actual orders at half-hour intervals. Metrics like mean absolute error, root mean squared error, or mean absolute percentage error are tracked region by region. Each region’s daily evaluation is compiled into a trend analysis over weeks. Significant errors trigger deeper investigation into model assumptions or data anomalies. Important events like holidays receive special attention to ensure the model captures unusual patterns.
Validation occurs both offline (using historic data) and online (monitoring actual vs predicted daily). A champion-challenger approach can run multiple models in parallel and automatically pick the best performer for each region once enough real data is collected.
How do you ensure the system scales as new regions are added?
The pipeline remains flexible because each region’s forecasting job is independent. Dask or a similar framework automatically distributes additional tasks across cluster workers. Regions can be added to the data ingestion layer. The pipeline then starts generating forecasts for them without altering core logic. Storage considerations on S3 or similar data storage systems are routinely monitored. Compute resources are scaled horizontally by provisioning more worker nodes in the cluster.
What if your main model fails for certain edge cases?
A fallback model runs in parallel for every region. Often, this fallback is a moving average of previous days, or a simpler linear approach. If the primary model yields outputs that fail basic checks, the system selects the fallback forecast. This setup prevents disruptions in courier scheduling. Alerts and logs capture such events so that data scientists can investigate. Failures can arise from data corruption, unexpected events, or an algorithmic bug, and the fallback ensures minimal impact on operations.
Why is a Python-based solution preferred over reimplementing in another language?
Data scientists typically develop advanced models in Python. Rewriting these models in languages like Java can introduce errors, slow research iterations, and cause mismatches between research and production. Python offers a strong ecosystem of data libraries (NumPy, pandas, scikit-learn) and can scale using Dask or Spark. A Pythonic solution means the same code used in research goes to production with minimal friction. This approach keeps the model improvement cycle fast and consistent.
How do you address hyperparameter tuning and advanced model selection?
Hyperparameter searches can be distributed. Each worker trains a model variant with different parameters. Results are tracked on a validation set. The best configuration is chosen for production forecasts. The system must store details of each run, including parameters and performance metrics. This history helps trace improvements over time and revert if a new model underperforms.
Local experimentation may be performed on a small subset of regions to test wide ranges of parameters. A final distributed run can test refined ranges or finalize the model. The code remains consistent throughout research and deployment, supported by version control.
How do you incorporate external data like weather or holidays?
These factors are joined with historical order data to form exogenous features. Weather data is fetched from an API and stored daily. Holiday flags or event schedules are pulled from relevant repositories. The pipeline merges these into the main dataset before training. Each model receives these additional signals and can learn correlations between weather, holidays, promotions, and demand. A region might see spikes in winter storms or on local festival weekends, which the model can capture with these exogenous variables.
A thorough data dictionary describing each external feature is crucial so the pipeline remains maintainable. Changes or gaps in these external sources are caught early by validation checks.
How do you handle real-time changes in conditions?
This pipeline focuses on daily scheduling decisions, not minute-by-minute optimization. Real-time adjustments can still occur, but the half-hour forecasts form a baseline for courier block scheduling. In truly dynamic conditions (major weather events, sudden local disruptions), a near-real-time reforecasting tool can overlay or refine the daily forecasts. This real-time layer might collect signals from courier app usage or location data. The daily pipeline remains the main mechanism for multi-week horizon planning.
No sentence or section here is an introduction or conclusion.