
ML Case-study Interview Question: Detecting Emerging Transaction Fraud with Unsupervised Bipartite Graph Autoencoders.


Browse all the ML Case-Studies here.
Case-Study question
A global platform collects consumer-to-merchant transaction data for its on-demand services. The platform wants to detect new fraudulent patterns in these transactions that are not captured by historical fraud labels. The data is represented as a bipartite graph with consumer nodes, merchant nodes, and edges denoting transactions. Node and edge features contain user profile attributes, merchant attributes, and order details. Propose an unsupervised graph-based solution to spot emerging fraud patterns. Describe how you would structure the model architecture, training approach, and scoring mechanism. Explain how you would integrate these anomaly scores with human or automated systems. Show how your approach can catch novel fraud behaviors at scale.
Detailed Solution
Overview of the Approach
The data is a bipartite graph G with two disjoint node sets U (consumers) and V (merchants), and edges E representing transactions. Node features include user or merchant profile data. Edge features include transaction details. The aim is to learn a model that can reconstruct normal behaviors and assign high anomaly scores to suspicious activities. Autoencoders are well-suited because they learn a compressed representation of normal patterns and produce high reconstruction errors for abnormal ones.
Graph Construction
Each consumer node u in U has feature vector X_u. Each merchant node v in V has feature vector X_v. Each edge (u, v) in E has feature vector X_(u,v). Include time of transaction, total amount, promotional codes used, and other relevant factors. Construct a bipartite graph from these interactions.
Model Architecture
Use a bipartite graph autoencoder. The encoder learns latent representations for consumer nodes and merchant nodes while incorporating their edge attributes. The decoder then reconstructs the node and edge features. This reconstruction forms the basis for anomaly scoring.
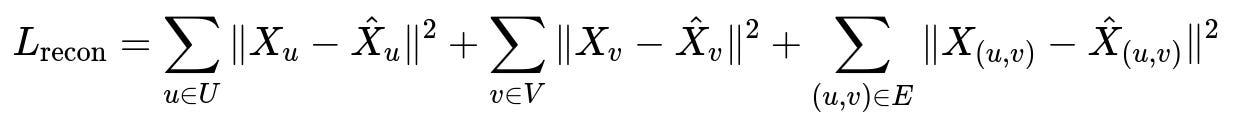
L_recon is the overall reconstruction loss. X_u, X_v, and X_(u,v) are the original features of the consumer node, merchant node, and edge. hat{X}_u, hat{X}v, and hat{X}{(u,v)} are their reconstructed versions from the autoencoder. Minimizing L_recon helps the model learn typical behaviors.
Anomaly Score Computation
Edge-level anomaly score is the reconstruction error for the edge features. Node-level anomaly score is a combination of the node's own reconstruction error and an aggregation (mean or max) of its connected edge errors. Higher scores indicate behaviors the model fails to reconstruct well, suggesting out-of-distribution or fraudulent activities.
Automated Actioning System
Pass computed anomaly scores into a rules engine that automatically labels suspicious patterns (possible promotion abuse, unusual transaction patterns, or collusion). Combine these scores with other domain signals. Examples of actions include flagging suspicious users or merchants for review, temporarily disabling promotional codes, or suspending high-risk transactions in real time.
Human-in-the-Loop Validation
Send top anomalies to fraud experts. They confirm or deny suspicious cases. Confirmed cases update a knowledge base for potential future improvements. This feedback can help refine the model by periodically integrating known anomalies into model retraining.
Example Python Snippet
import torch
import torch.nn as nn
import torch.optim as optim
class GraphEncoder(nn.Module):
def __init__(self, in_dim, hidden_dim):
super(GraphEncoder, self).__init__()
self.gc1 = nn.Linear(in_dim, hidden_dim)
self.gc2 = nn.Linear(hidden_dim, hidden_dim)
def forward(self, x):
h = torch.relu(self.gc1(x))
z = self.gc2(h)
return z
class GraphDecoder(nn.Module):
def __init__(self, hidden_dim, out_dim):
super(GraphDecoder, self).__init__()
self.dc1 = nn.Linear(hidden_dim, hidden_dim)
self.dc2 = nn.Linear(hidden_dim, out_dim)
def forward(self, z):
h = torch.relu(self.dc1(z))
out = self.dc2(h)
return out
# Suppose node_features shape = [num_nodes, in_dim]
# Suppose adjacency list or edge_features is used for node-edge-node training logic
encoder = GraphEncoder(in_dim=64, hidden_dim=32)
decoder = GraphDecoder(hidden_dim=32, out_dim=64)
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=1e-3)
for epoch in range(100):
optimizer.zero_grad()
z = encoder(node_features)
reconstructed = decoder(z)
loss = (node_features - reconstructed).pow(2).sum()
loss.backward()
optimizer.step()
This simplified code shows how you might build a graph autoencoder. In a real scenario, incorporate graph convolutions tailored for bipartite data and incorporate edge features explicitly.
Practical Implementation Details
Use mini-batch training if the graph is large. Store node and edge embeddings efficiently. Evaluate performance by manually checking flagged anomalies. Ensure that your pipeline can update or retrain frequently because fraud patterns shift.
Possible Follow-up Questions
How do you extend the model to detect anomalies in multi-entity graphs beyond consumers and merchants?
Use heterogeneous graph techniques with specialized encoders for each node type. Include interactions among various node classes. Represent each relation type (consumer-merchant, consumer-driver, merchant-distributor, etc.) in separate adjacency structures or hyperedges, then combine them in a shared latent space. Modify the reconstruction loss to include each relation type’s features.
What if fraudsters spoof node features, making them appear normal?
Rely more on the dynamic or relational patterns within the graph. Temporal and structural features often reveal suspicious link patterns that are harder to fake. Also integrate external signals (device info, behavioral logs). Weighted loss can emphasize edge-level reconstruction when node features are unreliable.
How do you decide thresholds for labeling nodes or edges as anomalies?
Use unsupervised metrics like percentile-based thresholds on reconstruction error. Alternatively, use a small labeled set of known anomalies to guide threshold selection. Conduct offline experiments to see how different thresholds balance false positives and false negatives.
How would you handle cold-start scenarios for new consumers or merchants?
Short-horizon incremental training with a small batch of data. Combine default or average embeddings for new nodes. Update embeddings as more data arrives. Ensure real-time partial retraining or adaptation to accommodate new nodes rapidly.
How do you evaluate model performance without explicit labels for new fraud patterns?
Perform retrospective analysis with newly emerged fraud cases identified by experts. Conduct ablation studies to confirm that high anomaly scores align with suspicious behaviors. Use delayed labels from confirmed fraud investigations to measure precision and recall.
How can you optimize the pipeline for very large bipartite graphs?
Partition the graph into subgraphs for distributed processing. Use mini-batch or sampling-based graph convolution approaches. Employ parallel data loaders. Use efficient graph data structures (e.g., sparse adjacency). Consider approximate nearest neighbor search for large-scale node embeddings.
How do you keep this system robust when fraudsters adapt to the model?
Monitor drift in node and edge distributions. Incorporate continuous or periodic model retraining. Maintain adaptive thresholds that reflect new distributions. Integrate ensemble detectors to reduce reliance on a single model’s assumptions. Include feedback loops from domain experts to track new exploits quickly.
How do you integrate additional business constraints or rules into the model?
Embed domain rules in a post-processing step or a parallel subsystem. For instance, if a certain consumer location is known to have minimal fraud risk, reduce false alarms by lowering anomaly scores for that region. If certain merchant categories are prone to abuse, raise anomaly scores to reflect that risk profile.