
ML Case-study Interview Question: Fair On-Device Face Recognition via Clustering Face/Body Embeddings & Sparse Coding.


Case-Study question
A tech company wants to implement on-device face recognition for photos stored on user devices. They must handle variations in lighting, pose, and obstructed faces. They also want to ensure fairness for all skin tones, ages, and genders. The product needs to identify individuals across large photo libraries, build a local gallery of known people, and update that gallery as new photos are added. The approach must keep the entire pipeline on-device to preserve user privacy. How would you design and implement this system end-to-end, and which methods would you use for training, evaluation, and deployment?
Detailed Solution
Overview
This solution involves two main phases: (1) building a gallery of known individuals through clustering, and (2) assigning identities to new observations via a classification step. Everything runs on-device for privacy. The system uses face and upper-body embeddings to account for photos where faces are partially occluded. The pipeline needs to handle high variability in user-generated imagery, where faces may have varying expressions, lighting, or poses. A fairness strategy ensures consistent accuracy across demographics.
Phase 1: Building the Gallery with Clustering
A deep neural network locates faces and upper bodies. The system pairs each face bounding box with a corresponding upper-body bounding box for that same person. Two separate deep neural networks extract a face embedding and an upper-body embedding. Each embedding is a vector in a high-dimensional space. Similar embeddings cluster together.
We cluster these embeddings in two passes. First, a conservative pass merges only highly similar embeddings. Second, we run a hierarchical agglomerative clustering step focused on face embeddings. This two-pass approach boosts recall without sacrificing precision.
A key distance formula blends the face distance F_ij with the upper body distance T_ij. For two observations i and j, the system computes a combined distance:
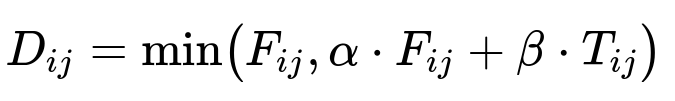
Here, D_{ij} is the overall distance between observations i and j, F_{ij} is the face embedding distance, T_{ij} is the upper-body distance, alpha is a scaling factor for the face distance, and beta is a scaling factor for the upper-body distance. The min operation helps the pipeline rely on whichever cue (face or upper body) provides a robust signal.
Clustering runs periodically and forms a gallery of major clusters representing different individuals. The system applies heuristics based on cluster size and inter/intra-cluster distances to finalize the set of known people.
Phase 2: Assigning Identities to New Observations
When a new image comes in, the pipeline extracts the embeddings and matches them to the gallery. Instead of simple nearest neighbor, the system uses a sparse coding approach. Let y be the new embedding vector, and let D be the dictionary of exemplars from each cluster. We solve:
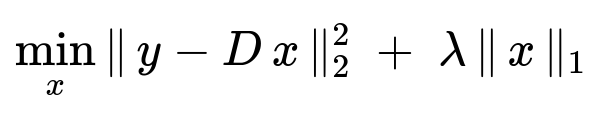
The vector x is a sparse representation indicating how much y aligns with each exemplar in D. We pick the cluster whose exemplars collectively have the highest activation in x. This is more robust than a single centroid, especially for large, diverse galleries. If the new embedding does not align well with any known cluster, the system creates a new cluster or tags it as unknown.
Data Preparation and Fairness
The pipeline requires a training dataset that reflects global diversity in age, gender, and skin tone. The model must be tested for balanced error rates. Data augmentation helps the model cope with real-world conditions, such as face masks, varying lighting, and different clothing styles.
Neural Network Architecture
A lightweight convolutional network runs on-device. It has inverted residual blocks and channel attention for efficiency. Each face embedding is normalized onto a unit-hypersphere so that distances and cosine similarities become more discriminative.
Margin-based softmax loss with hard-example mining helps the network learn separable embeddings. This margin-mining approach scales well when training from scratch. It amplifies differences between classes and pushes embeddings from the same class closer. The pipeline also includes an uncertainty branch to detect out-of-distribution inputs, preventing noisy detections from contaminating the gallery.
On-Device Optimization
All steps run locally on specialized hardware. On some devices, specialized neural engines can speed up inference. This is critical for real-time image processing and ensures user data never leaves the device. Memory optimizations and careful scheduling allow the system to handle large libraries overnight or when charging.
Example Code Snippet (Training a Face Embedding Model)
Below is a simplified Python example illustrating a training loop for a model that outputs normalized embeddings. This code uses a margin-mining softmax loss. Assume you have a Model class and a custom margin_mining_softmax loss function.
import torch
import torch.nn as nn
import torch.optim as optim
# Example face embedding model
model = Model()
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.0001)
def margin_mining_softmax(predictions, labels):
# Custom margin-based loss calculation
# 'predictions' -> output from the final layer
# 'labels' -> ground truth indices
# Return a scalar loss
# (Implementation details omitted for brevity)
loss = ...
return loss
# Training loop
for epoch in range(num_epochs):
for images, labels in train_loader:
optimizer.zero_grad()
embeddings = model(images)
# embeddings -> shape (batch_size, embedding_dim)
# labels -> shape (batch_size)
loss = margin_mining_softmax(embeddings, labels)
loss.backward()
optimizer.step()
In production, you would also include data augmentation, a curriculum-learning approach, and a separate step to calibrate an uncertainty module for out-of-distribution detection.
How would you ensure the system handles images where faces are partially occluded or turned away?
Occlusion is addressed by including upper-body embeddings. If a user’s face is invisible or obstructed, the clothing features help group those images with others from the same person, as long as the photos are from the same time or context. During the first clustering pass, the system only compares upper-body embeddings for images in the same moment, because clothing is more consistent in a short timespan.
How do you handle fairness and avoid bias in the recognition pipeline?
Fairness starts with diverse data collection. The training set must represent a wide range of demographics. The system tracks performance separately on multiple demographic slices. Margin-based losses and data augmentation (such as mask overlays) boost generalization. We then test to confirm minimal performance gaps among sub-groups. Failure analysis focuses on cases where the system assigns incorrect identities or fails to detect a face at all.
How do you detect false positives or non-human objects that trigger face detection?
We train a confidence branch that outputs a measure of embedding reliability. During training, we show the network out-of-distribution examples (random crops or non-human faces) and label them as invalid. If the confidence branch is below a threshold for a particular crop, we filter that detection and prevent it from contaminating the clusters.
What strategies do you use to keep the entire process private and on-device?
All model inference, clustering, and classification occur locally. Images and embeddings never leave the device. We rely on hardware acceleration to achieve real-time speeds without offloading to remote servers. The gallery storage uses local metadata. User confirmations (labeling who is in a photo) stay private, as the system updates the clusters on-device.
How would you optimize computational performance for large photo libraries?
We run the clustering incrementally. Each time new images arrive, we cluster only the new embeddings and merge them into existing clusters. We schedule intensive processes (like the second pass of hierarchical clustering) when the device is idle or charging. The dictionary-based classification is fast since it uses a sparse coding approach, which involves quick vector operations.
How do you maintain accuracy when a user adds thousands of images with new individuals?
If a new face is repeatedly observed, the clustering step naturally forms a new cluster. When it meets certain size or distance criteria, the gallery designates it as a known person. The dictionary for identity assignment expands with exemplars from that new cluster. The system also monitors user confirmations. If the user labels that new cluster with a name, subsequent observations can be assigned quickly.
Conclusion
A complete on-device face recognition system involves high-quality embeddings, robust clustering, a dictionary-based classification method, fairness checks, and privacy guarantees. By combining face and upper-body embeddings, the system handles occlusions and partial views. By using margin-based losses and out-of-distribution detection, it maintains strong accuracy across diverse populations. By limiting computation to the device’s neural engine and scheduling major tasks during idle times, it scales to large libraries without sacrificing speed or user privacy.