
ML Case-study Interview Question: Efficient Image Embeddings for E-commerce Visual Search and Recommendations.


Case-Study question
A major e-commerce marketplace hosts a wide range of unique items with seller-uploaded images and buyer-provided review photos. The business wants a robust “search-by-image” feature and visually similar item recommendations. They also want low-latency inference on mobile devices to handle real-time image queries. The focus is on training efficient deep learning architectures that can generate image embeddings for downstream tasks such as search, recommendation, and sponsored ads ranking. The marketplace has limited GPU resources and must also evaluate retrieval quality with reliable metrics. How would you design and implement an end-to-end system for efficient visual representation learning, including architecture choice, multitask training, evaluation (with recall-based metrics), and large-scale serving of these image embeddings?
Detailed Solution
Model Architecture
Lightweight convolutional neural networks (CNN) and Vision Transformers (ViT) are considered. CNN models like EfficientNet optimize width, depth, and resolution through scaling coefficients. This allows incrementally scaling if more resources become available.
ViT variants can outperform CNN in large-data regimes. Standard ViT has higher training costs, but newer designs are more efficient. An example is an EfficientFormer architecture. It downsamples multiple blocks and uses limited attention layers. That results in strong representations with fewer parameters than a full ViT.
Model Training
Fine-tuning starts with pre-trained backbones. One approach is taking EfficientNetB0, replacing its final layer with an embedding layer plus classification heads for multiple tasks. The new layers are trained from scratch for one epoch with the backbone frozen, then the top backbone layers are unfrozen and trained for additional epochs. A similar approach is applied to an EfficientFormer-based ViT, using average pooling of the last hidden state.
Multitask learning boosts efficiency. A single embedding encodes multiple aspects: category taxonomies, color attributes, and so on. Different classification heads share the same base embedding. This helps capture common visual features.
Evaluating Visual Representations
Nearest neighbor retrieval is the core test. A small queries set and a larger candidates set are embedded. A brute-force index is built, and top-k neighbors are checked for correct matches. Recall@k is measured after each epoch for tasks like “intra-item” retrieval (seller images of the same item) and real user interactions (clicked visually-similar ads).
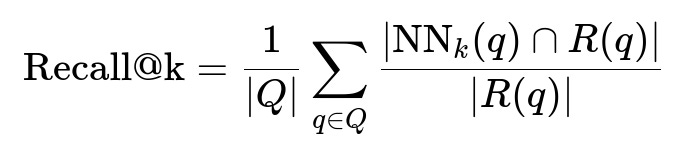
Here, Q is the set of query images. NN_k(q) is the set of top-k nearest neighbors for query q. R(q) is the set of relevant (matching) images for q.
A hybrid evaluation uses text-to-image generation for queries. A diffusion model generates multiple possible images from a text query, bridging text and image space. That image set is used to evaluate the retrieval performance. Efficient generative pipelines with token merging and float16 inference help reduce GPU usage.
Inference and Serving
Online inference happens when a user uploads a new image. Model size, number of parameters, and input resolution all affect latency. EfficientNetB0 (about 5 million parameters) can run in ~1.7ms on an iPhone 12, which is practical for real-time queries. Embedding dimension also matters for approximate nearest neighbor retrieval. A 256-dimensional embedding is smaller than other variants and speeds up distance computation.
EfficientFormer-l3 can produce more expressive embeddings at ~30 million parameters and ~2.7ms latency on iPhone 12. This model lifts recall metrics in offline evaluations and can improve click-through rate (CTR) and purchase rate in A/B tests. It trades off a slight increase in latency for greater retrieval quality.
Example Python Snippet
import torch
import torch.nn as nn
import torch.nn.functional as F
class EfficientNetEmbedding(nn.Module):
def __init__(self, backbone, embed_dim=256, num_tasks=4):
super(EfficientNetEmbedding, self).__init__()
self.backbone = backbone
# Example final layers
self.new_conv = nn.Conv2d(1280, embed_dim, kernel_size=1) # dimension depends on backbone
self.bn = nn.BatchNorm2d(embed_dim)
self.activation = nn.SiLU() # swish
self.pool = nn.AdaptiveAvgPool2d((1,1))
# Multiple classification heads
self.class_heads = nn.ModuleList([nn.Linear(embed_dim, out_dim)
for out_dim in [15,1000,10,100]]) # example
def forward(self, x, task_id=None):
feat = self.backbone.extract_features(x)
feat = self.new_conv(feat)
feat = self.bn(feat)
feat = self.activation(feat)
feat = self.pool(feat) # shape: (batch_size, embed_dim, 1, 1)
feat = feat.view(feat.size(0), -1)
if task_id is not None:
logits = self.class_heads[task_id](feat)
return logits
return feat # final embedding
Layer freezing is done by setting requires_grad = False for certain blocks in the backbone. Classification heads handle different tasks (taxonomy, attributes, etc.). In inference, only the final embedding is extracted.
Follow-up Question 1
How do you handle domain shift between seller-uploaded (well-lit, high-quality) images and buyer-uploaded (sometimes blurry, varied lighting) images?
Answer: Data diversity in training is critical. Combining a fine-grained classification task with buyer-uploaded images captures those domain characteristics. Augmenting buyer review images with random cropping, color jitter, and distortions helps the model generalize. It sees noisy or non-ideal examples during training. Freezing earlier backbone layers and finetuning later layers can adapt the learned weights to the new domain without overfitting.
Follow-up Question 2
Why might ViT-based models capture more global features, and how does an efficient architecture offset their usual compute burden?
Answer: Transformers compute attention over the entire image patch sequence, so they model global relationships better than a typical CNN. Standard ViTs have large memory and computational overhead. Efficient solutions reduce costs by downsampling at multiple stages, limiting the attention scope, or mixing CNN-like operations with selective attention blocks. This preserves the global representational power with fewer parameters.
Follow-up Question 3
How would you improve the text-to-image diffusion-based evaluation if the generated images sometimes lose important details?
Answer: Prompt engineering guides the generation process to focus on key details. An expanded prompt adds descriptors like color, style, or shape. Re-ranking or filtering the generated set can remove poor-quality outputs. We can also sample multiple seeds and keep the images that best match text references. For real-time scenarios, employing a more advanced diffusion model with better memory optimization might reduce artifact severity.
Follow-up Question 4
What steps ensure retrieval scalability when you have millions of candidate item images?
Answer: Approximate nearest neighbor indexing reduces retrieval latency. Methods like hierarchical clustering or graph-based indexing limit full brute-force searches. The 256-dimensional embeddings stay small, which reduces storage. Periodic offline reindexing keeps data fresh, while online ephemeral indexes can handle newly uploaded images. Sharding indexes by category or popularity can also improve speed.
Follow-up Question 5
How do you measure real-world impact beyond recall metrics?
Answer: Online A/B tests measure click-through rate, conversion rate, and purchase rate. Embeddings can be plugged into ads and search ranking models. If incorporating the new embeddings lifts conversions or ad returns compared to a baseline, it indicates the representations meaningfully improve user satisfaction. Tracking latency and memory usage ensures the system remains performant for mobile users in production.