
ML Case-study Interview Question: Enhancing Retail Search Relevance with Dual-Tower Transformer Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A major online retailer with a vast product catalog wants to improve the relevance of its search results. They have many popular queries that account for over 50% of search traffic, along with a long tail of queries that produce sparse user engagement signals. They seek to build a system that learns unified, dense vector representations for both queries and products, so that (query, product) pairs can be measured for semantic closeness. They also need to address cases where training data is noisy, certain products have zero conversion, and new products and queries must be handled daily at scale. As the Senior Data Scientist, propose a complete approach for constructing and deploying such a system. Include details on how you would gather training data, generate positive and negative samples, handle noisy relevance labels, use product metadata, architect the model, and continuously integrate it into the main search pipeline.
Comprehensive Solution
A dual-tower transformer-based embedding model encodes queries in one tower and products in another. Each tower learns a representation that resides in the same vector space, enabling a direct relevance comparison via similarity (often cosine). The model is pretrained on generic text corpora and then fine-tuned on in-house query–product data. This approach allows independent encoding of queries and products, making it computationally efficient in production.
Data is sourced from logged search impressions. Conversions (user adds) serve as positive samples, because adding an item after a query often implies relevance. However, unconverted items do not necessarily imply irrelevance. An in-batch negative approach addresses this. For each batch, only the diagonal (query_i, product_i) pairs are positives; off-diagonal (query_i, product_j) pairs are treated as negatives. Self-adversarial re-weighting highlights the challenging negatives. Hard examples receive higher weights, forcing the model to refine its representation for subtle differences.
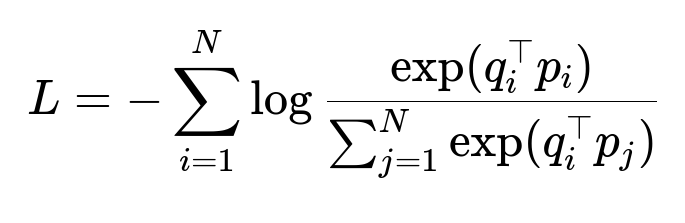
Above, q_i and p_i are the embedding vectors for the i-th query and its matching product. p_j is the embedding for a different product j in the same batch. This loss moves relevant pairs closer and irrelevant pairs farther in the embedding space.
Noise arises because a user might add items unrelated to the query’s original intent (for example, a user searches for cereal but also adds produce in the same session). The model is first trained on large but noisy data. Then a smaller high-quality dataset is used in a fine-tuning step. During the warmup, weights are shared between both towers. During fine-tuning, towers can specialize, and this cascade training mitigates label noise.
Synthetic queries expand training coverage by permuting product metadata. For rare products lacking past conversions, brand, category, size, or other attributes can form extra queries. Combining this with multi-task learning—where the product tower predicts brand and category—clusters similar items closer. This reduces drift from popularity bias and stabilizes optimization.
In production, the system precomputes product embeddings offline on a daily schedule. For queries, embeddings are stored for the most frequent searches. A smaller fraction is processed on the fly. The pipeline uses an approximate nearest neighbor search index for fast retrieval. Final reranking blends embedding-based relevance signals with other features (popularity, user preferences, real-time context).
Rich metadata enables distinct uses beyond query–product similarity. One example is to measure product–product similarity for deduplicating suggestions or for recommending complementary items. Whenever new products or queries appear, fresh embeddings are generated and incorporated into the index, ensuring coverage of the evolving catalog.
Ensuring low inference latency requires careful caching of query embeddings and a fast lookup for product vectors. Distributed systems handle the scale, while daily batch jobs recompute and roll out updated vectors. In an experiment, measuring the top converted item’s position and the overall search conversion rates revealed a consistent uplift after introducing embedding-based signals.
Model performance tracking involves monitoring search metrics, usage trends, and segment-level impact (for example, new or less frequent queries). Online A/B tests confirm whether the embedding system boosts conversions, user satisfaction, or revenue. Further expansion can incorporate advanced transformer variants, additional metadata, and more domain-specific language modeling.
How would you handle negative samples without explicit user feedback?
A query that does not convert on a product is not always proof of irrelevance. The in-batch negative approach helps. For every positive pair in a batch, the remainder of (query_i, product_j) pairs become negative. A soft self-adversarial weighting technique prioritizes negatives that the model currently finds plausible. This tightens the decision boundary and avoids the risk of conflating personal preference (not adding an item) with irrelevance.
Filtering out truly confusing samples (e.g., items that might be relevant but were not added for non-search-related reasons) is done by carefully selecting thresholds for how many relevant items per query are kept as positives in the training set. Minimizing false positives preserves model reliability.
Why use a two-step training (cascade) instead of a single pass?
A single pass on noisy query–product pairs often pushes the model to memorize incomplete signals, hurting generalization. A larger dataset includes spurious matches (for instance, products that users added for other reasons). Training exclusively on this data can degrade model precision.
A two-phase cascade strategy first captures broad patterns by training on a larger, noisier dataset with the weights tied between towers. This readies the base transformer layers. The second phase narrows the fine-tuning to a more selective dataset and unties the tower weights. The product tower captures product metadata distinctions, and the query tower focuses on user search intent. This approach stabilizes learning and refines embeddings for better relevance.
How do you incorporate product metadata?
Metadata such as brand, category, size, and dietary labels is appended to product text. In the model input, these tokens appear in brackets, for example “[PN] product name [PBN] brand name [PCS] category1 [PAS] attributes.” Synthetic queries arise by recombining brand, category, and other fields. This increases coverage for underrepresented items.
Multi-task learning also makes the product tower predict brand categories or hierarchical labels. This ensures that items in the same category cluster more tightly, improving semantic understanding. This helps the model handle brand-specific or category-specific queries.
How do you handle real-time deployment and latency?
Products and queries get vectorized, then stored in an approximate nearest neighbor index (for example, using libraries like FAISS). During searches:
If a query embedding is cached, retrieval uses that vector instantly.
For new queries without a cached embedding, a fast on-the-fly transformer call encodes them, typically in under 8 ms.
The nearest neighbor search quickly fetches candidate products based on vector similarity.
A reranker refines results using other signals.
Daily offline jobs refresh product embeddings. The system merges the updated vectors into the existing index. This ensures minimal stale data while maintaining sub-second overall latency.
How would you address popularity bias or coverage for less popular products?
Popularity bias arises if the model overfits to products with high conversion frequency. The synthetic query approach and multi-task learning reduce that risk by forcing the product tower to learn brand/category semantics, not just raw conversion stats. The two-step training also removes some noisy or spurious positive labels.
Less popular products that never appear in logs receive artificial positive pairs from their attributes. This approach integrates them into the embedding space. Observing post-launch metrics confirms if the system surfaces more diverse products across queries. If not, adjusting the weighting or threshold in synthetic queries can calibrate coverage further.
How would you extend this to synonyms or misspellings?
Subword tokenization in the transformer partially addresses near-synonyms and slight variations in spelling. If the data covers enough domain-specific text, synonyms align in the embedding space. For synonyms that rarely appear in training, data augmentation can artificially link them to known categories. For severe misspellings, specialized expansions or error-correction modules can suggest queries that match known embeddings. This synergy helps direct the model to relevant products without losing semantic context.