
ML Case-study Interview Question: ML for Smooth Streaming: Predicting Throughput, Adapting Bitrate, Caching, Detecting Anomalies.


Browse all the ML Case-Studies here.
Case-Study question
You are working at a streaming platform serving millions of users worldwide. Each user can watch movies and shows on devices ranging from smartphones to TVs. Many networks are unpredictable, with throughput that can surge or plunge at random. The streaming platform’s core challenge is ensuring high-quality video playback with minimal buffering, across varied devices and network conditions. How would you design a machine learning solution to improve streaming quality, predict network throughput, decide when and how to switch video quality levels, proactively cache likely-to-be-watched content on a device, and detect device anomalies?
Provide a step-by-step approach explaining what data you would collect, which models you would build, and how you would evaluate success. Explain how your solution would adapt in real time, handle unexpected conditions, and scale globally.
Detailed Solution
Network conditions fluctuate in unpredictable ways. High variability can cause buffering if the selected video bitrate is too high relative to actual bandwidth. Some users watch content over stable networks, while others are on volatile cellular connections. Building a robust solution involves several parts.
Network Quality Prediction
Statistical models can extract features from past throughput measurements, device metadata, time of day, and longer historical patterns. Recurrent Neural Networks (RNNs) or other time-series models can capture temporal dependencies, while additional variables such as device type and location can improve the predictions. The output can be a probabilistic forecast of likely bandwidth ranges or a direct regression value of expected throughput.
Historical training data comes from real sessions, where actual bitrates and buffering events are logged. The model uses these labeled sessions to learn patterns. Predictions update every few seconds, letting the system adjust dynamically.
Adaptive Bitrate Selection
A streaming session can choose from multiple encodings. The playback software needs a policy to switch among these encodings. A reinforcement learning approach can learn a policy that balances higher video quality against rebuffer risk. A common practice is to define a reward function that penalizes buffering and rewards higher quality.
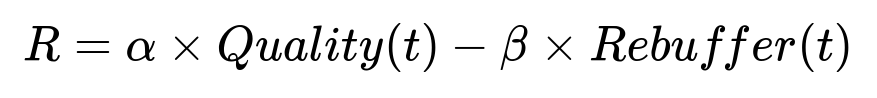
alpha is a weight that increases reward for higher quality. beta is a weight that penalizes rebuffer events. Quality(t) is the chosen bitrate at time t. Rebuffer(t) represents stalling or waiting for data at time t.
The system updates Quality(t) for each video chunk download. Predictions of future throughput help reduce rebuffering by staying within reliable bandwidth. Large future bandwidth estimates allow higher quality. The policy is evaluated by measuring average rebuffering frequency and delivered bitrate.
Predictive Caching
Predictive caching starts pre-downloading content based on high-confidence guesses of what a user will watch next. Historical watch patterns guide a classifier or ranking model that outputs the most probable title or episode for each user. The device caches partial or full segments if bandwidth is available and disk space permits.
For instance, a user watching Season 2, Episode 3 of a show is highly likely to play Episode 4 next. A machine learning model refines these predictions by incorporating watch streaks, time intervals between episodes, and user device type.
When the user plays the cached title, waiting time drops and the video can start in higher quality. The approach is measured by comparing startup times and average initial bitrates against a baseline with no predictive caching.
Device Anomaly Detection
The system runs on many device types. Sudden performance drops may indicate firmware regressions or network changes. A supervised model can rank potential anomalies based on metrics like error rates or average rebuffer times. The system continuously checks for unusual deviations from historical norms and flags them. A random forest or gradient boosting model can ingest device logs, firmware version, region, and time window. A strong predicted anomaly score prompts engineers to investigate root causes.
Root cause analysis can isolate whether the anomaly is local to certain hardware versions, firmware updates, or a new application release. Filtering out normal network fluctuations or planned rollouts is critical to avoid chasing false alarms.
Example Code Snippet for Adaptive Streaming Policy
import numpy as np
class AdaptiveBitratePolicy:
def __init__(self, alpha, beta):
self.alpha = alpha
self.beta = beta
def get_action(self, predicted_throughput, buffer_level, candidate_bitrates):
# predicted_throughput in Mbps
# buffer_level in seconds
# candidate_bitrates is a list of possible rates in Mbps
# simplistic approach that picks the highest feasible bitrate
feasible_bitrates = [b for b in candidate_bitrates if b < predicted_throughput]
if not feasible_bitrates:
return min(candidate_bitrates)
return max(feasible_bitrates)
def reward(self, quality, rebuffer):
return self.alpha * quality - self.beta * rebuffer
The simplistic method picks the highest feasible bitrate below predicted_throughput. More advanced approaches can leverage lookahead or advanced RL algorithms.
Follow-Up Question 1
How would you handle extremely noisy throughput data where the network may drop suddenly and exceed expectations in short bursts?
Answer
Short bursts and sudden drops need probabilistic forecasting. A distribution-based prediction, rather than a single point estimate, yields a better sense of the risk of sudden low bandwidth. The streaming logic can then pick a bitrate that reduces rebuffer risk if there is a high probability of a throughput dip. Local smoothing and outlier handling can reduce the impact of spiky measurements. Sliding-window filtering or short-term exponential smoothing can stabilize predictions. Adding memory to the model (like in RNNs) helps capture transitions that might happen in recurring patterns, such as commuting tunnels or home microwave interference.
Follow-Up Question 2
How would you cope with conflicting objectives, for example wanting to minimize buffering while also maximizing video quality?
Answer
The reward function encodes both objectives, weighting them via alpha for quality and beta for buffering. Tuning alpha and beta is crucial. A large alpha pushes the system to stream at higher bitrates, risking more buffering. A larger beta emphasizes buffering avoidance, possibly compromising quality too much. Grid searches or Bayesian optimization can find alpha and beta values that balance these objectives effectively. Offline simulation with real logs can tune parameters before a live rollout.
Follow-Up Question 3
How would you measure success for predictive caching when memory constraints are tight?
Answer
Success measurement focuses on reducing startup latency and increasing initial video quality. The system logs how often the next-played title was already cached. True-positive caching rates reflect how often the system guessed correctly and pre-downloaded content actually watched. A ratio of beneficial preloads to total preloads shows the precision of the caching predictor. Storage overhead or bandwidth usage must remain within allowable limits. If caching success metrics are good but memory overhead is too high, you refine the model’s threshold so only the highest-confidence titles get cached. This ensures strong performance gains while respecting constraints.
Follow-Up Question 4
What techniques would you use for large-scale anomaly detection that must simultaneously handle thousands of device variants?
Answer
A multi-stage approach works well. An unsupervised clustering or density-based method (like DBSCAN or isolation forests) can flag unusual patterns in high-dimensional data. A separate supervised model can rank and filter these events to reduce false positives, using historical labeled alerts as training data. The supervised model’s features incorporate device type, version, region, error rate changes, rebuffering changes, and timeline patterns. The approach scales by partitioning data streams by device group or region. Each partition processes its own anomaly checks, then aggregates results. This parallelized strategy handles diverse device families at once.
Follow-Up Question 5
How would you ensure that your anomaly detection system is robust to typical user behavior changes, such as seasonality or big feature launches?
Answer
Seasonality or large product launches can cause sudden metric shifts that are not actual anomalies. Historical data that includes past seasonal patterns helps the model learn normal fluctuations. Datasets spanning multiple years let the model see prior events during the same time frame and avoid flagging them as anomalies. The system also tracks major planned launches and adjusts anomaly thresholds around those dates. Explicit features marking holiday weeks or big releases provide context to the model. Frequent retraining or incremental learning strategies keep the model aligned with evolving user behaviors.
Follow-Up Question 6
How would you scale your entire solution globally, given that each region has different networks, devices, and user profiles?
Answer
Global scaling requires a flexible architecture and region-aware models. At the data pipeline level, each region streams logs to a central processing system. Models can share a common architecture but receive region-specific embeddings or separate specialized models. Hybrid approaches combine a broad global model with fine-tuned local parameters. The platform architecture must efficiently update and deploy model parameters to client devices. Monitoring pipelines must verify that region-specific anomalies or network variances are caught. Distributed data storage and compute clusters can handle high volumes of logs from different continents, allowing near-real-time updates for adaptation logic.